



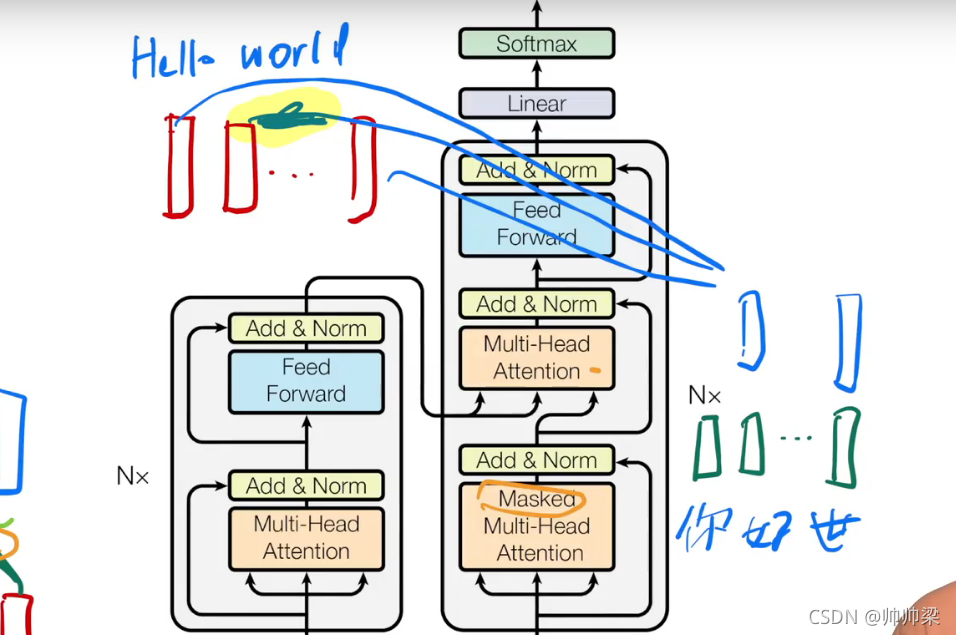
3模型架构
大多数有竞争力的神经序列转导模型都有编码器-解码器结构。在这里,编码器映射一个符号表示的输入序列(x1,…,xn)(x_1,…, x_n)(x1,…,xn)为一个连续的表示序列z=(z1,…、zm)z= (z_1,…、z_m)z=(z1,…、zm)。给定,解码器然后生成一个输出序列(y1,…(,ym)(y1,…(, y_m)(y1,…(,ym)每次一个元素的符号。在每个步骤中,模型都是自动回归的,在生成下一个步骤时,将之前生成的符号作为额外的输入使用。Transformer遵循这种总体架构,编码器和解码器都使用了堆叠的自注意层和点式的、完全连接的层,分别如图1的左右两部分所示。
自动回归: 给定一个z,然后生成y1y_1y1,根据y1y_1y1生成y2y_2y2,y3y_3y3,ymy_mym,就是一个一个往外蹦。
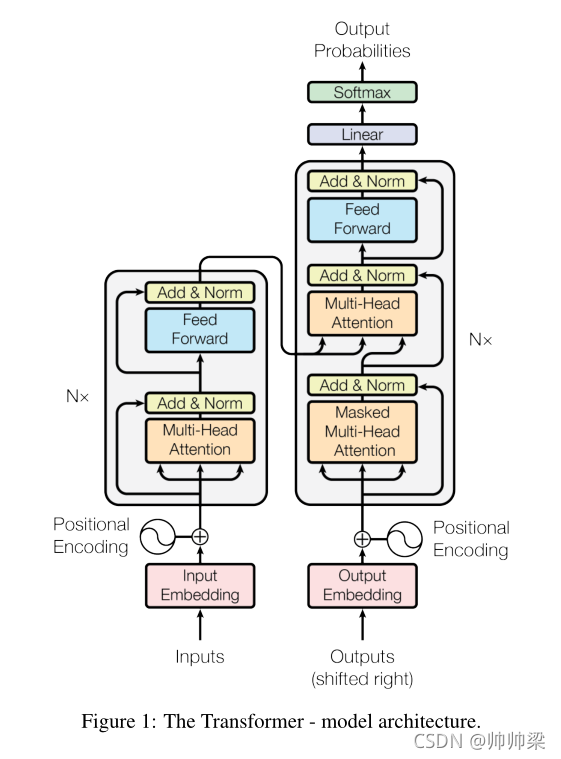
左边是编码器,右边是解码器,解码器最开始是没有输入的,shifted right就是一个个往右崩,往右移动。
首先进入的使我们的词向量,词嵌入,一个个词变成我们的词向量。
上面的,就是有一个我们的注意力层,有一个残差连接,一个mlp,然后一个归一化norm。
然后编码器的输出作为解码器的输入,
3.1 编码器和解码器
编码器:编码器由n = 6个相同的层组成。
每一层有两个子层。第一种是多头自注意机构,第二种是简单的位置全连接前馈网络。我们在两个子层周围使用残差连接,然后是层归一化。也就是说,每个子层的输出是LayerNorm(x+ Sublayer(x)),其中ublayer(x)是子层本身实现的函数。
为了方便这些剩余连接(因为残差连接需要我的输入和输出大小是一样的),模型中的所有子层以及嵌入层都产生了dimension model= 512的输出。(也就是把每一层输出的维度都固定成512)
batch-normal
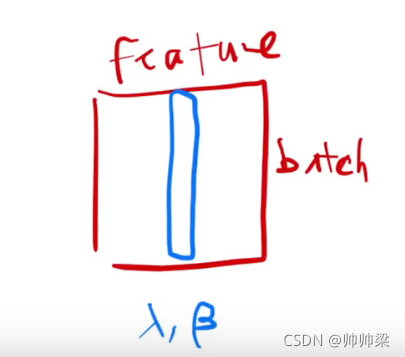
就是把每个列,变成我们的均值为0,方差为1的向量。列使我们的特征(fiature)。
LayerNorm
就是对每一个样本进行操作,上面那个是对每一个特征进行操作

蓝色是batch,黄色是layernormal
在时序中,我们的样本长度可能发生变化,
解码器
解码器:解码器也由n = 6个相同的层组成。除每个编码器层中的两个子层外,解码器还插入第三个子层,该子层对编码器堆栈的输出执行多头注意。与编码器类似,我们在每个子层周围使用剩余连接,然后进行层归一化。我们还修改了解码器堆栈中的自注意子层,以防止位置注意到后续位置。(保证t时间,看不到t时间以后的那些输入)这种掩蔽,加上输出嵌入被一个位置偏移的事实,确保了positionican的预测只依赖于小于i位置的已知输出。
3.2 注意力
注意函数可以描述为将查询和一组键-值对映射到输出,其中查询、键、值和输出都是向量。输出是作为值的加权和计算的(也就是输出的维度和我的value的维度是一样的),其中分配给每个值的权重是通过查询与相应键的兼容性函数(相似度)计算的。
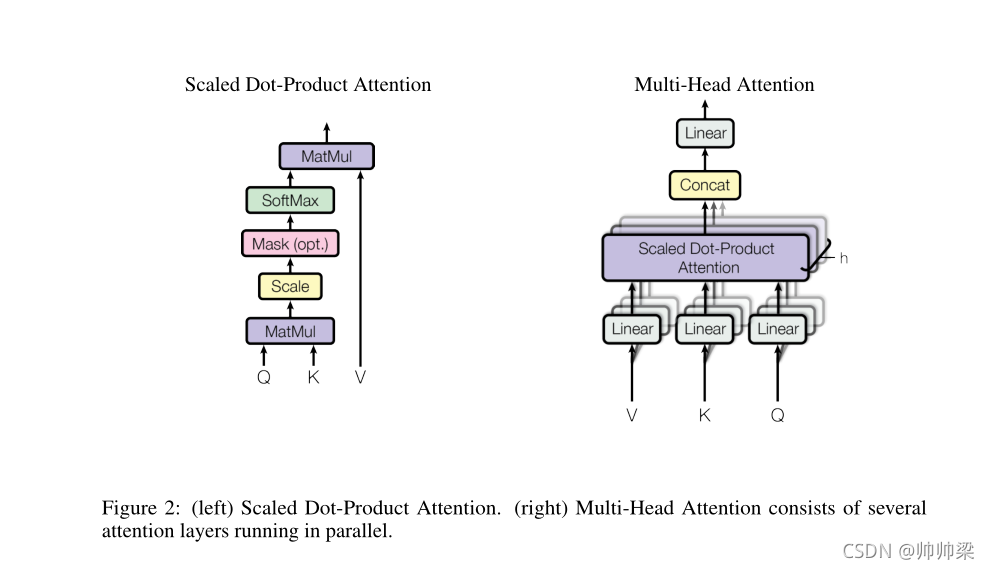
(左)缩放点积注意。(右)多头注意由几个平行运行的注意层组成。
左: Q和K先点积,然后除以我们的dkd_kdk,mask是为了防止我们在t时间看到以后时间的东西,然后softmax,然后跟我们的V相乘,最后输出。
(mask:也就是我们QtQ_tQt时刻,我们对于所有的K依然是计算的,但是对于Kt−1K_{t-1}Kt−1之后的那些数,我们替换成一个非常大的负数,这样我们在softmax后就会变成0,也就是只有前面那些值出效果)
为啥不直接置0
Scaled Dot-Product Attention
输入包括维度dk的查询和键(queries and keys 是等长的),输出 的维度是dvd_vdv。我们计算查询与所有键的点积(内积,内积的值越大,相似度越高),每个键除以√dk,并应用softmax函数获得值的权重。
在实践中,我们同时对一组查询计算注意力功能,并将其打包成一个矩阵q。键和值也被打包到matricesKandV中。我们计算输出矩阵为:
query可以写成一个矩阵, key 也可以写成一个矩阵

两个矩阵内积,得到的就是n*m的矩阵,每一行,就图中蓝色的,就是我们的一个query对所有key的内积值。然后每一行softmax。

当dk值较小时,这两种机制的表现相似,但当dk(也就是向量比较长的时候)值较大时,加性注意优于点积注意。我们怀疑当dk的值很大时,点积的大小就会变大,将softmax函数推到具有极小梯度的区域4。为了抵消这个效应,我们将点积乘以1√dk
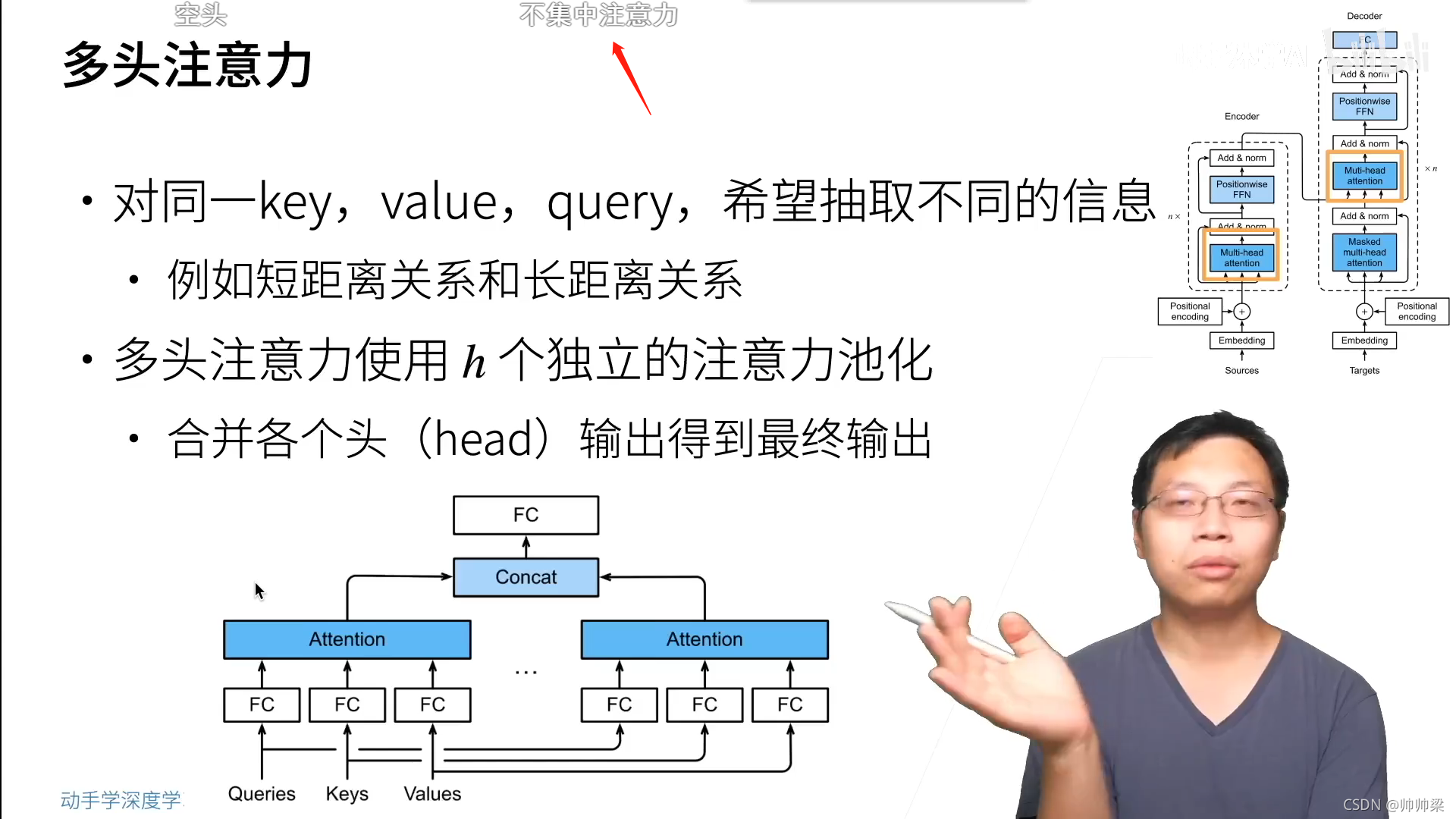
Multi-Head Attention
我们发现,与其使用模型维度的键、值和查询来执行单一的注意功能,不如分别用不同的、学习过的线性投影来线性投影查询、键和值时间。在这些查询、键和值的每个投影版本上,我们然后并行地执行注意功能,生成dv维的输出值。将它们连接起来并再次进行投影,得到最终的值,如图2所示。
三个多头注意力的具体解释
- 在“编码器-解码器注意”层中,查询来自前面的解码器层,而内存键和值来自编码器的输出。这使得译码器中的每个位置都可以参加输入序列中的所有位置。
- 编码器包含自我注意层。在自我注意层中,所有的键、值和查询都来自同一个地方,在本例中,是编码器中前一层的输出。编码器中的每个位置都可以对应上一层的所有位置。
- 类似地,解码器中的自我注意层允许解码器中的每个位置关注解码器中直到并包括该位置的所有位置。我们需要防止解码器中的信息流向左,以保持自回归特性。我们通过屏蔽(设置为−∞)softmax输入中对应非法连接的所有值来实现缩放点积注意。
我们的编码器输入有三个值,分别是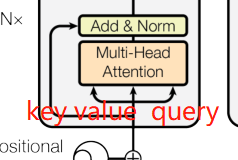
但是这里是 我们同样一个东西,复制了三下,也就是一个数据,及当作key,也当作value,也当作query。这就是我们说的自注意力机制,
第三个已经不再是自注意力了,key和value来自于编码器的输出,quert来自于下一个解码器的下一个attention的输入,编码器最后一层的输出就是n个长度为d的向量,
这个attention干的事情实际上就是去有效的把你想要的东西拎出来。也就是根据你解码器的输入的不一样,我们去编码器里面挑选我关注的东西出来。
Position-wise Feed-Forward Networks
也就是一个完全的全连接层,他就是一个MLP,他就是把一个MLP对每一个词作用一次,然后对每一个词作用的是同一个MLP,这就是Position-wise的意思。说白了就是MLP只是作用在最后一个维度。
输入是长为n的向量,经过attention,得到同样长度的输出,最简单的attention就是对你的输入进行一个加权和,然后通过MLP,每一个点得到一个输出,然后得到的整体就是我们transformer的输出,attention的作用,就是把你序列中有价值的信息提取出来。
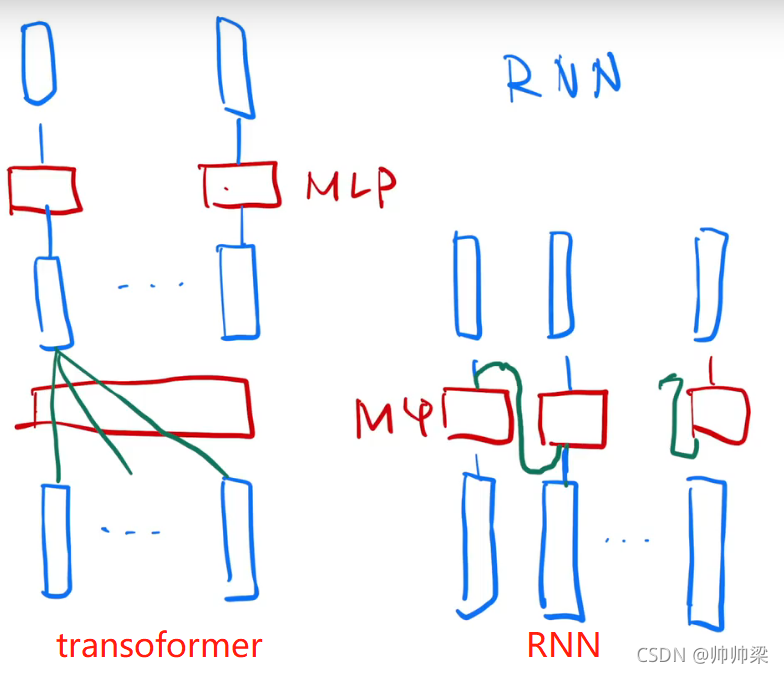
在后面可以分开做,是因为在之前attention的时候,信息已经汇聚完成了。
Embeddings and Softmax
输入是一个个词,也就是我们的token,我需要把他映射成一个向量,enbadding就是给定一个词,我是用一个长度为d的向量来表示它。
Positional Encoding
因为attention是没有时序信息的,我们的输出是value的一个加权和,也就是我给定一句话,我把序列打乱,我出来的结果都是一样的,attention就是我在我的输入里面加入我的时序信息,这个东西就是Positional Encoding

















 1646
1646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









