







最近在搞一些重检测的东西,所以打算整理一些加入重检测环节的目标跟踪论文!
最后更新时间:20201130
代码和结果:https://github.com/foolwood/DaSiamRPN
大多数Siamese跟踪方法只能将前景从非语义的背景中区分出来,而背景中的一些部分可能成为干扰项。
作者的三点贡献:
1、分析了常规的Siamese跟踪算法中使用的特征,并提出非语义背景训练数据和语义干扰项训练数据的不平衡是网络学习的一大阻碍;
2、作者提出了Distractor-aware Siamese Region Proposal网络(DaSiamRPN),在离线训练阶段学习干扰项感知特征,在在线跟踪的推理过程中抑制干扰项;
3、引入local-to-global搜索区域策略,实现长时跟踪,可以很好应对out-of-iew和full occlusion情况。
传统Siamese网络的特征和缺点:

Siamese网络以度量学习(metric learning)为核心,目的是学习一个能够最大化不同类别物体之间的inertia(如何翻译?求指教!)和最小化同类物体间inertia的空间。如Fig1所示,在SiamFC和SiamRPN算法中,背景中差别较大的物体和一些完全不相关的物体分数很高。SiamFC的表达用于训练数据中类别的判别学习。在SiamFC和SiamRPN中,成对的训练数据来自同一视频的不同帧,对于搜索区域,非语义的背景占据主体,而语义实体和干扰项占比很小。样本的不均衡分布使得模型难以学习到实例级别的表达,只能学习前景和背景的差别。
在inference阶段,利用最近邻算法找寻搜索区域内最相似的物体,然而第一帧中标注的背景信息却被忽略了。如Fig1(e)所示,加入背景信息可以很好的增强判别能力。
干扰项感知的训练:
作者提出一系列办法来增强所学特征的泛化能力并消除训练数据的不均衡分布。
- 多种类的正样本对可以增强泛化能力
原始的SiamFC是在ILSVRC视频检测数据集上训练的,该数据集包含4000个逐帧标注的视频。SiamRPN使用包含200,000个视频每30帧标注的Youtube-BB数据集。在上述两种方法中,训练数据的目标对来自同一视频的不同帧。然而,这两个数据集包含的目标种类较少(VID:20种,Youtube-BB:30种),不足以为Siamese跟踪训练高质量和泛化能力强的特征。此外,SiamRPN中的bounding box regression分支可能会在遇到新种类时得到较差的预测结果。由于标注数据集非常耗时耗力,作者利用ImageNet Detection和COCO Detection数据集来扩大正样本对的种类。如Fig2(a)所示,通过数据增强方法(平移、缩放、灰度化等),检测数据集中的静止图像可用于生成训练用的图像对。

- 语义负样本对可以增强判别能力
作者将SiamFC和SiamRPN判别能力弱归结于两种层级的样本不均衡分布。
1、稀少的语义负样本对
由于背景占据了SiamFC和SiamRPN训练数据的主体,大部分负样本是非语义的(非语义就是指它不是一个独立的目标,只是背景的一部分,个人理解,有错误请指教),并且很容易被分类。也就是说,SiamFC和SiamRPN学习前景和背景的差别,并且由于大量简单负样本的存在,语义目标间的loss没有发挥作用(这里感觉翻译的不好)。
2、同类干扰项的不均衡
同类干扰项常在跟踪过程中作为难例样本。
本文将语义负样本对加入训练过程中,所构建的负样本对包含同类和不同类的目标。不同类别的负样本对可以帮助跟踪器避免在out-of-view和full occlusion场景中漂移到任意目标上,相同类别的负样本让跟踪器关注细粒度的表达。负样本如Fig2(b)(c)所示。
- 为视觉跟踪定制的高效数据增强方法
除了常见的平移、尺度变换、光照变换方法,利用网络的前几层引入运动模糊。
干扰项感知增量学习:

之前所提出的方法确实可以在离线训练过程中提升判别能力。然而,区分两个具有相似属性的目标仍然很难,如Fig.3a所示。SiamFC和SiamRPN使用余弦窗来抑制干扰。当目标的运动是杂乱的时候,效果就无法保证了。大多数基于Siamese网络的方法在fast motion和background clutter情况中表现较差。总之,潜在的缺点是由通用表达域和具体目标域之间的不匹配导致的。在本节中,作者提出干扰项感知模块来将通用表达转换到视频域。 From general to specific!
Siamese跟踪器学习相似性度量,从而在嵌入空间
![]() 中比较样本图
中比较样本图和候选图
:
![]()
其中 表示两个特征图间的互相关,
![]() 表示在各个位置都相等的偏差。与样本最相似的目标将会被选为最终的目标。
表示在各个位置都相等的偏差。与样本最相似的目标将会被选为最终的目标。
为了充分利用标签信息,我们将难例样本(干扰项)引入到相似性度量中。在DaSiamRPN中,非极大值抑制(NMS)方法被用于选择每帧中的潜在干扰项,因此我们会获得干扰项集合
![]() ,其中
,其中 是设定的阈值,
是
帧中选定的目标,该集合的数量为
![]() 。在每一帧中,我们首先获得
。在每一帧中,我们首先获得个proposal,然后利用NMS来去除冗余的proposal,分数最高的proposal将被选为目标
。剩下的proposal中,分数超过阈值的将被选为干扰项。
在这之后,我们引入一个干扰感知目标函数来重新排名与样本 相似的proposals
![]() 。最终被选定的目标为
。最终被选定的目标为 :
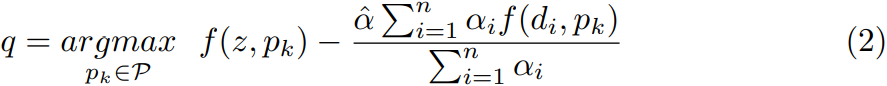
权重因子控制干扰项学习的影响,权重因子
控制每个干扰项
的影响。值得注意的是计算复杂度和内存使用量增加了
倍。由于公式(1)中的互相关操作是线性的,我们利用该属性来加速干扰感知目标函数:

这使得DaSiamRPN可以跑出和SiamRPN相匹敌的速度。同时该算法以学习率学习目标模板和干扰项模板。
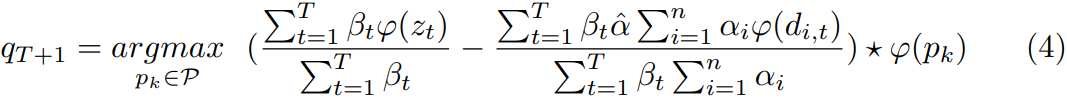
干扰项已知的跟踪器可以将现存的相似性度量方法(general)适用于一个新的域(specific)。权重因子可以被看作稀疏正则化的对偶变量,样本和干扰项可以被看作相关滤波器中的正、负样本。实际上, 作者建立了在线分类器模型,因此比只使用一般的相似性度量方法的算法效果好。
将DaSiamRPN用于长时跟踪:

除了短时跟踪中的挑战,长时跟踪中往往还有严重的out-of-view和full occlusion挑战,如Fig.4所示。当目标重新出现在视野中时,短时跟踪(SiamRPN)中的搜索区域不能包含目标,跟踪失败。作者提出一种简单有效的切换方法,实现短时跟踪和失败情况的切换。在失败情况下,一种迭代的局部到全局搜索策略被用于重检测目标。
为了实现切换,我们需要明确跟踪失败的起始帧和结束帧。由于干扰项感知的训练和推理能获得高质量的检测分数,因此可以被用于表明跟踪结果的质量。Fig.4展示了SiamRPN和DaSiamRPN的检测分数和相应的跟踪重叠度。SiamRPN的检测分数不具有指明意义,因为它在out-of-view和full occlusion情况下仍然很高。也就是说,在这些挑战下,SiamRPN往往找寻任意目标,这就导致跟踪漂移。DaSiamRPN的检测分数能够表明跟踪的状态。
在失败情况下,我们通过从局部到全局策略来逐渐扩大搜索区域。当跟踪失败时,搜索区域的大小以恒定步长迭代增长。如Fig.4所示,从局部到全局的搜索区域包含着目标,从而恢复正常跟踪。值得注意的是本文的算法采用bounding box回归方法来检测目标,放弃了耗时的图像金字塔方法。DaSiamRPN在长时跟踪基准上可以跑到110FPS。
实验结果:
为了保证公平的比较,所有跟踪结果都是官方实现提供的。
详情见论文。。。















 1935
1935











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









