







掌握cache,对写出高效能代码,以及优化Linux系统的性能是至关重要的。
L1 cache的icache(指令)和dcache(数据)是分离的,这样可以实现指令和数据的并行访问,CPU可以同时load指令和数据。
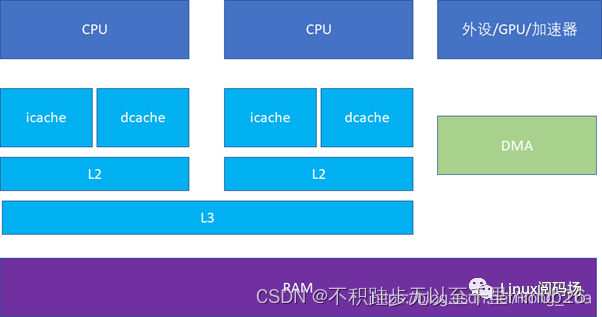
CPU 各level cache典型分布是这样的,比如多个core共享一个L3。

L2cache通常被称为 MLC (MiddleLevel Cache), L3cache通常被称为 LLC(Last LevelCache)。
系统中应该尽可能追求cache的命中率高,以避免延迟, 最好是低级cache的命中率越高越好。
CACHE 的组织
现代的cache基本按照这个模式来组织:SET、WAY、TAG、INDEX,这几个概念是理解Cache的关键。
SET、WAY、TAG、INDEX
16KB 的cache是 4way 的话,每个set包括 4*64B ,则整个cache分为 16KB/64B/4 = 64set,也即2的6次方。
当CPU从cache里面读数据的时候,它会用地址位的BIT6-BIT11来寻址set,BIT0-BIT5是cacheline内的offset。
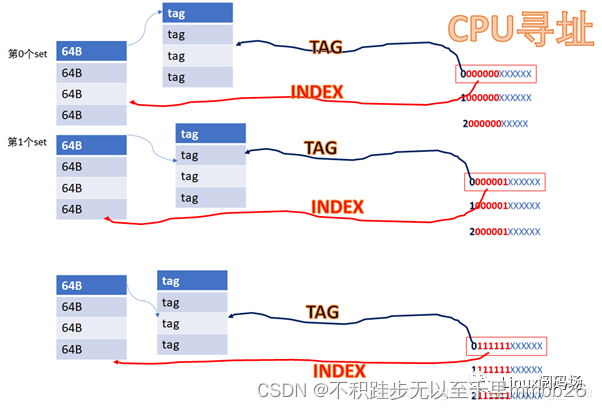
由于它们红色的6位都相同,所以他们全部都会找到第0个set的cacheline。第0个set里面有4个way,之后硬件会用地址的高位如0,1,YYYY作为tag,去检索这4个way的tag是否与地址的高位相同,而且cacheline是否有效,如果tag匹配且cacheline有效,则cache命中。
所以地址YYYYYY 000000XXXXXX全部都是找第0个set,YYYYYY000001XXXXXX全部都是找第1个set,YYYYYY111111XXXXXX全部都是找第63个set。每个set中的4个way,都有可能命中。
中间红色的位就是INDEX,前面YYYY这些位就是TAG。
具体的实现可以是用虚拟地址或者物理地址的相应位做TAG或者INDEX。
如果用虚拟地址做TAG,我们叫VT;
如果用物理地址做TAG,我们叫PT;
如果用虚拟地址做INDEX,我们叫VI;
如果用物理地址做INDEX,我们叫PI。
工程中碰到的cache可能有这么些组合:VIVT、VIPT、PIPT。
VIVT、VIPT、PIPT
具体的实现可以是用虚拟地址或者物理地址的相应位做TAG或者INDEX。
如果用虚拟地址做TAG,我们叫VT;
如果用物理地址做TAG,我们叫PT;
如果用虚拟地址做INDEX,我们叫VI;
如果用物理地址做INDEX,我们叫PI。
VIVT的硬件实现开销最低,但是软件维护成本高;PIPT的硬件实现开销最高,但是软件维护成本最低;VIPT介于二者之间,但是有些硬件是VIPT,但是behave
as PIPT,这样对软件而言,维护成本与PIPT一样。
在VIVT的情况下,CPU发出的虚拟地址,不需要经过MMU的转化,直接就可以去查cache。
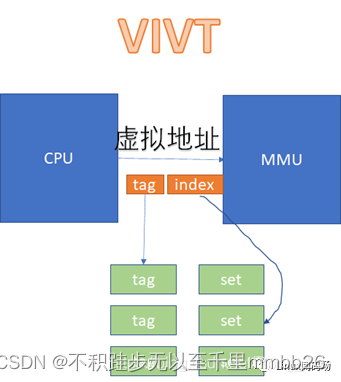
而在VIPT和PIPT的场景下,都涉及到虚拟地址转换为物理地址后,再去比对cache的过程。VIPT如下:
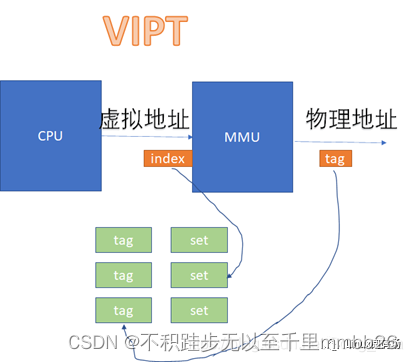
PIPT如下:
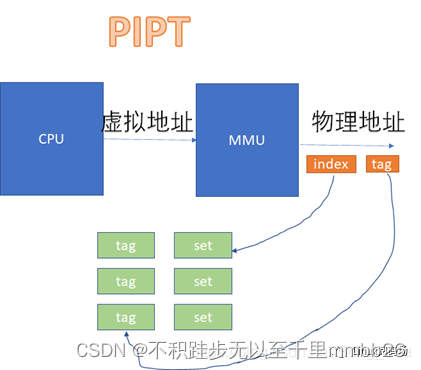
从图上看起来,VIVT的硬件实现效率很高,不需要经过MMU就可以去查cache了。不过,对软件来说,这是个灾难。因为VIVT有严重的歧义和别名问题。
歧义:一个虚拟地址先后指向两个(或者多个)物理地址
别名:两个(或者多个)虚拟地址同时指向一个物理地址
Cache别名问题
这里我们重点看别名问题。比如2个虚拟地址对应同一个物理地址,基于VIVT的逻辑,无论是INDEX还是TAG,2个虚拟地址都是可能不一样的(尽管他们的物理地址一样,但是物理地址在cache比对中完全不掺和),这样它们完全可能在2个cacheline同时命中。
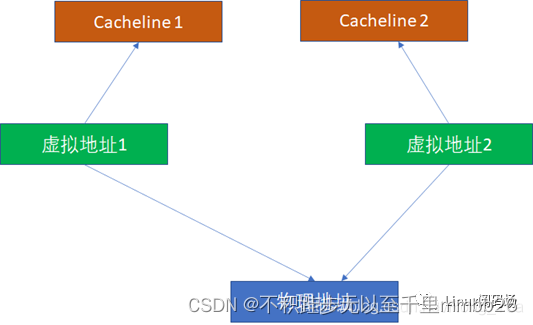
由于2个虚拟地址指向1个物理地址,这样CPU写过第一个虚拟地址后,写入cacheline1。CPU读第2个虚拟地址,读到的是过时的cacheline2,这样就出现了不一致。所以,为了避免这种情况,软件必须写完虚拟地址1后,对虚拟地址1对应的cache执行clean,对虚拟地址2对应的cache执行invalidate。
而PIPT完全没有这样的问题,因为无论多少虚拟地址对应一个物理地址,由于物理地址一样,我们是基于物理地址去寻找和比对cache的,所以不可能出现这种别名问题。
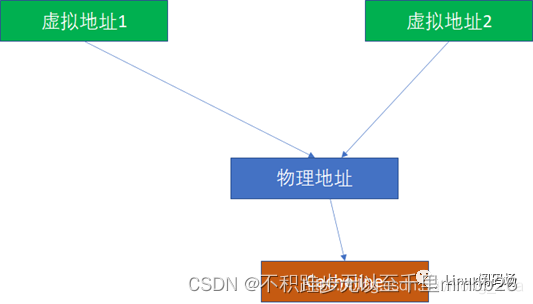
那么VIPT有没有可能出现别名呢?答案是有可能,也有可能不能。 如果VI恰好对于PI,就不可能,这个时候,VIPT对软件而言就是PIPT了:
VI=PI
PT=PT
那么什么时候VI会等于PI呢?这个时候我们来回忆下虚拟地址往物理地址的转换过程,它是以页为单位的。假设一页是4K,那么地址的低12位虚拟地址和物理地址是完全一样的。回忆我们前面的地址:
YYYYY000000XXXXXX
其中红色的000000是INDEX。在我们的例子中,红色的6位和后面的XXXXXX(cache内部偏移)加起来正好12位,所以这个000000经过虚实转换后,其实还是000000的,这个时候
VI=PI ,VIPT没有别名问题。
我们原先假设的cache是:16KB大小的cache,假设是4路组相联,cacheline的长度是 64字节
,这样我们正好需要红色的6位来作为INDEX。但是如果我们把cache的大小增加为32KB,这样我们需要
32KB/4/64B=128=2^7,也即7位来做INDEX。
YYYY0000000XXXXXX
这样VI就可能不等于PI了,因为红色的最高位超过了2^12的范围,完全可能出现如下2个虚拟地址,指向同一个物理地址:
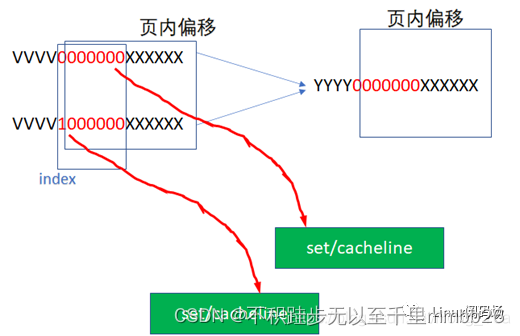
这样就出现了别名问题,
我们在工程里,可能可以通过一些办法避免这种别名问题,比如软件在建立虚实转换的时候,把虚实转换往213而不是212对齐,让物理地址的低13位而不是低12位与物理地址相同,这样强行绕开别名问题,下图中,2个虚拟地址指向了同一个物理地址,但是它们的INDEX是相同的,这样VI=PI,就绕开了别名问题。这通常是PAGE
COLOURING技术中的一种技巧。
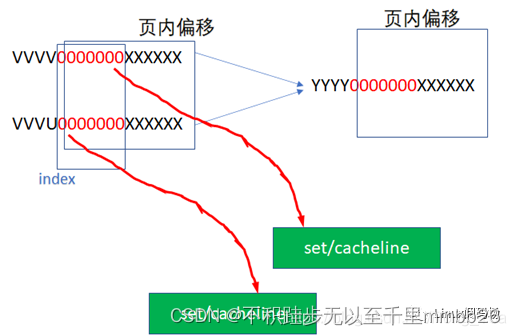
如果这种PAGE
COLOURING的限制对软件仍然不可接受,而我们又想享受VIPT的INDEX不需要经过MMU虚实转换的快捷?有没有什么硬件技术来解决VIPT别名问题呢?确实是存在的,现代CPU很多都是把L1
CACHE做成VIPT,但是表现地(behave as)像PIPT。这是怎么做到的呢?
这要求VIPT的cache,硬件上具备alias detection的能力。比如,硬件知道YYYY 0000000 XXXXXX既有可能出现在第
0000000 ,又可能出现在 1000000
这2个set,然后硬件自动去比对这2个set里面是否出现映射到相同物理地址的cacheline,并从硬件上解决好别名同步,那么软件就完全不用操心了。
下面我们记住一个简单的规则:
对于VIPT,如果cache的size除以WAY数,小于等于1个page的大小,则天然VI=PI,无别名问题;
对于VIPT,如果cache的size除以WAY数,大于1个page的大小,则天然VI≠PI,有别名问题;这个时候又分成2种情况:
硬件不具备alias detection能力,软件需要pagecolouring;
硬件具备alias detection能力,软件把cache当成PIPT用。
比如cache大小64KB,4WAY,PAGE SIZE是4K,显然有别名问题;这个时候,如果cache改为16WAY,或者PAGE
SIZE改为16K,不再有别名问题。
CACHE 的一致性
Cache的一致性有这么几个层面
1.一个CPU的icache和dcache的同步问题
2.多个CPU各自的cache同步问题
3.CPU与设备(其实也可能是个异构处理器,不过在Linux运行的CPU眼里,都是设备,都是 DMA )的cache同步问题
cache中的映射
1. 直接映射
一个内存地址能被映射到的Cache line是固定的。就如每个人的停车位是固定分配好的,可以直接找到。缺点是:因为人多车位少,很可能几个人争用同一个车位,导致Cache淘汰换出频繁,需要频繁的从主存读取数据到Cache,这个代价也较高。
2. 全相联映射
主存中的一个地址可被映射进任意cache line,问题是:当寻找一个地址是否已经被cache时,需要遍历每一个cache line来寻找,这个代价很高。就像停车位可以大家随便停一样,停的时候简单,找车的时候需要一个一个停车位的找了。
主存中任何一块都可以映射到Cache中的任何一块位置上。
全相联映射方式比较灵活,主存的各块可以映射到Cache的任一块中,Cache的利用率高,块冲突概率低,只要淘汰Cache中的某一块,即可调入主存的任一块。但是,由于Cache比较电路的设计和实现比较困难,这种方式只适合于小容量Cache采用。
3. 组相联映射
组相联映射实际上是直接映射和全相联映射的折中方案,其组织结构如图(3)所示。
主存和Cache都分组,主存中一个组内的块数与Cache中的分组数相同,组间采用直接映射,组内采用全相联映射。也就是说,将Cache分成2u组,每组包含2v块,主存块存放到哪个组是固定的,至于存到该组哪一块则是灵活的。即主存的某块只能映射到Cache的特定组中的任意一块。主存的某块b与Cache的组k之间满足以下关系:k=b%(2^u).
icache、dcache同步 - 指令流( icache )和数据流( dcache )
先看一下 ICACHE 和 DCACHE 同步问题。由于程序的运行而言, 指令流的都流过icache ,而指令中涉及到的数据流经过dcache 。所以对于自修改的代码(Self-Modifying Code)而言,比如我们修改了内存p这个位置的代码(典型多见于JIT
compiler),这个时候我们是通过store的方式去写的p,所以新的指令会进入dcache。但是我们接下来去执行p位置的指令的时候,icache里面可能命中的是修改之前的指令。
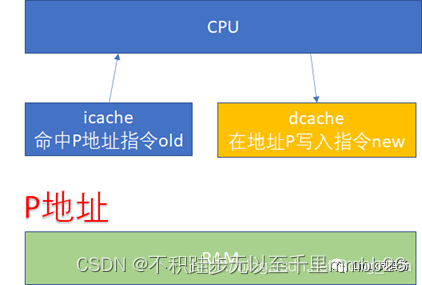
所以这个时候软件需要把dcache的东西clean出去,然后让icache invalidate,这个开销显然还是比较大的。
但是,比如ARM64的N1处理器,它支持硬件的icache同步,详见文档:The Arm Neoverse N1 Platform: Building Blocks for the Next-Gen Cloud-to-Edge Infrastructure SoC

特别注意画红色的几行。软件维护的成本实际很高,还涉及到icache的invalidation向所有核广播的动作。
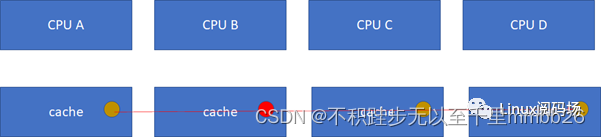
接下来的一个问题就是多个核之间的cache同步。下面是一个简化版的处理器,CPU_A和B共享了一个L3,CPU_C和CPU_D共享了一个L3。实际的硬件架构由于涉及到NUMA,会比这个更加复杂,但是这个图反映层级关系是足够了。

比如CPU_A读了一个地址p的变量?CPU_B、C、D又读,难道B,C,D又必须从RAM里面经过L3,L2,L1再读一遍吗?这个显然是没有必要的,在硬件上,cache的snooping控制单元,可以协助直接把CPU_A的p地址cache拷贝到CPU_B、C和D的cache

这样A-B-C-D都得到了相同的p地址的棕色小球。
假设CPU B这个时候,把棕色小球写成红色,而其他CPU里面还是棕色,这样就会不一致了:
这个时候怎么办?这里面显然需要一个 协议,典型的多核cache同步协议有MESI和MOESI。MOESI相对MESI有些细微的差异,不影响对全局的理解。
剩余部分有时间继续学习。。。
学习wiki:
深入理解CPU cache:组织、一致性(同步)、编程














 1339
1339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









