







第四章、集合
1.常见集合及其特点

2.集合概念
对象的容器、实现了对多个对象进行操作的方法,可实现数组的(CRUD)
注意:
CRUD:create(创建-增加)、update(更新-修改)、retrieve(接收-查询)、delete(删除)。
2.1集合和数组的区别
- 数组长度固定,集合长度不固定
- 数组可以存储基本数据类型、集合还可以存储引用数据类型
3.Coolection集合体系
3.1 Collection父接口
特点:代表一组任意类型的接口,无序、无下标、本能重复。返回的是Object对象
常用的方法:
| 方法摘要 | 方法描述 |
|---|---|
boolean | add(Object obj) // 添加一个对象 |
boolean | addAll(Collection c) // 将指定 collection 中的所有对象都添加到此 collection 中(可选操作)。 |
void | clear() // 清空集合, 移除此 collection 中的所有对象(可选操作)。 |
boolean | contains(Objec o) // 如果此 collection 包含指定的元素,则返回 true。检查此集合中是否含有o对象 |
boolean | equals(Object o) // 比较此 collection 与指定对象是否相等。比较刺激和是否与指定对象相等 |
boolean | isEmpty() // 如果此 collection 不包含元素,则返回 true。判断集合是否为空 |
boolean | remove(Object o) //从此 collection 中移除指定对象的单个实例,如果存在的话(可选操作)。移除集合中的o对象 |
int | size() // 返回此 collection 中的对象数。 |
Object[] | toArray() // 返回包含此 collection 中所有对象的数组。将集合转化成数组。 |
Collection接口的详解*
实际上集合类似于数组,数组可以做的操作,集合也可以去做,只不过集合里存放的是对象,而数组里存放的是数据
Colletion集合的操作
- 添加元素——add(Object o)方法,如果要打印集合中的对象,可以直接打印,也可以调用toString方法来打印。
public class CollectionMethodTest {
@org.junit.Test
public void main() {
Collection collection = new ArrayList(); //通过ArrayList实现
//添加元素
System.out.println("=======add添加元素======");
collection.add("苹果");
collection.add("西瓜");
collection.add("梨");
collection.add("香蕉");
collection.add("香蕉"); // 由于是通过ArrayList来实现Collection。所以允许重复
System.out.println(collection.size());//4
String str1 = collection.toString(); //转化成String类型
System.out.println(str1 instanceof String); //true
System.out.println("删除之前:"+str1);
Object o1 = collection;
System.out.println(o1 instanceof Object); //true
System.out.println("删除之前:" + o1);//[苹果, 西瓜, 梨, 香蕉]
}
}
- 删除元素——remove()
//删除元素
System.out.println("=======remove删除元素======");
collection.remove("香蕉");
System.out.println(collection.size()); //3
System.out.println("删除之后:" + collection); //删除之后:[苹果, 西瓜, 梨]
- 遍历集合元素——两种方式
- 增强for循环遍历结合
//遍历元素
/**
* 使用增强for循环遍历
*/
System.out.println("=======使用增强for循环遍历======");
for (Object o : collection) {
System.out.println(o);
}
- 使用iteration遍历集合(迭代器是一种专门用来遍历集合的一种方式)
iteration中的三个方法
- hasNext():判断集合中是否有下一个对象,返回布尔类型的值
- next():返回迭代的下一个元素。
- remove(Object o):从迭代器指向的 collection 中移除迭代器返回的最后一个元素(可选操作)。
注意:在迭代其中迭代元素的时候不能使用remove(Object o)方法,否则报错,错误类型ConcurrentModificationException异常
System.out.println("=======使用迭代器遍历集合======");
/**
* 使用迭代器遍历集合(迭代器是一种专门用来遍历集合的一种方式)
* hasNext() 判断是否有下一个
* next() 返回迭代的下一个元素。
* remove() 从迭代器指向的 collection 中移除迭代器返回的最后一个元素(可选操作)。
*/
Iterator iterator = collection.iterator();
while (iterator.hasNext()) {
String str = (String)iterator.next(); //强转为字符 或者对应的对象类型
System.out.println(str);
/**
* 在迭代的过程中,不能使用迭代器的删除方法
*/
// collection.remove(str); //java.util.ConcurrentModificationException 不允许并发修改异常
}
- 判断对象是否存在于该集合中——contains(Object o)
//判断
System.out.println("=====判断是否存在======");
System.out.println(collection.contains("西瓜"));
Collection 的使用
Collection的使用步骤
-
创建Collection对象
-
实例化添加对象
-
添加对象到Collection集合中(初始化集合)
-
执行操作
-
添加集合中的对象
-
删除集合中的对象 1、remove(object o) 2、clear()
- remove💩:是删除指定的对象
clear:删除集合中存储对象的地址、本身的对象并没有删除,还在内存中。
-
遍历集合中的对象 1、forEach 2、collection.iterator
collection.iterator:见上
-
`判断集合指定的对象是否存在于集合中contains()
-
判断集合元素是否为空 isEmpty()
-
3.2 List子接口
List接口的特点*
- 有序*:添加的顺序和遍历的顺序一致
- 有下标*
- 元素可重复*
List常用的特有方法
| 方法摘要 | 方法描述 |
|---|---|
void | add(int index,Object o) //在index位置插入对象o |
bollean | addAll(int index,Collection c) // 将一个集合中的元素添加到刺激和中的index位置 |
Object | get(int index) // 返回集合中的指定位置元素 |
List | subList(int fromIndex,int toIndex) // 返回fromIndex和toIndex之间的集合元素。 |
Object | get(int index) // 返回列表中指定位置的对象 |
ListIterator<Object> | listiterator(int index) |
ListIterator 中的九个方法
注意:在使用listIterator遍历数组的时候,既可以在迭代元素的时候删除元素,也可以添加元素,并不会报ConcurrentModificationException异常
- add(Object o):将指定的元素插入列表(可选操作)
- hasNext():以正向遍历列表时,如果列表迭代器有多个元素,则返回true
- hasPrevious():如果以逆向遍历列表,列表迭代器有多个元素,则返回true
- next():返回列表中的下一个元素
- nextIndex():返回对next的后续调用的所返回的元素的索引
- previous():返回列表中前一个元素
- previousIndex():返回对previous的后续待用的所返回的元素的索引
- remove():从列表中移除由next或者previous返回的最后的一个元素
- set(object o):用来指定替换next或者previous返回的最后一个元素(可选操作)
List子接口的使用*
类似于Collection接口的使用 步骤参照Collection的使用步骤上文
- 创建List对象,通过ArrayList实现
public class ListTest {
public static void main(String[] args) {
//创建集合 通过实现类来完成
List list = new ArrayList();
}
}
- 往List集合中添加对象元素
//添加元素
list.add("打篮球");
list.add("踢足球");
list.add("打排球");
list.add("打桌球");
list.add("扔飞碟");
System.out.println("list中删除之前的元素个数:"+list.size());
- 删除List集合中的元素
//删除元素 通过remove
list.remove(4); //可以通过下标实现删除,也可以通过具体对象参数
System.out.println("list中删除之后的元素个数:"+list.size()); //3
-
遍历集合中的对象
4中方法- For循环,由于List是有下标的,所以可以通过For循环遍历。通过get(i)获取元素
//遍历 /** * for循环遍历list集合 */ System.out.println("==========3.1 for循环遍历结合=========="); for (int i = 0; i < list.size(); i++) { //通过get(i)方法来遍历list数组 System.out.println(list.get(i)); }- forEach增强For循环
/** * forEach遍历list集合 */ System.out.println("=======3.2 forEach遍历list集合======="); for (Object o : list) { System.out.println(o); }- iterator迭代器循环遍历
/** * iterator遍历list集合 */ System.out.println("=======3.4 iterator遍历list集合======="); Iterator iterator = list.iterator(); while (iterator.hasNext()) { String s = (String) iterator.next(); System.out.println(s); }- ListIterato列表迭代器循环遍历
/** * listIterator遍历list集合 */ System.out.println("=======3.3.1 正向listIterator遍历list集合======="); ListIterator listIterator = list.listIterator(); //正向遍历 while (listIterator.hasNext()) { String s = (String) listIterator.next(); System.out.println(s); } System.out.println("=======3.3.1 逆向listIterator遍历list集合======="); //逆向遍历 while (listIterator.hasPrevious()) { String s1 = (String) listIterator.previous(); System.out.println(s1); } -
判断元素是否存在该集合中
/**
* 判断
*/
System.out.println(list.contains("打排球"));//true
- 判断集合中元素是否为空
/**
*判空判断isEmpty
*/
System.out.println(list.isEmpty()); //false
- 获取元素的下标
/**
* 获取元素位置
*/
System.out.println(list.indexOf("打排球"));//2 第三个位置
装箱与拆箱
装箱:自动将基本数据类型转化为其包装类
//自动装箱
Integer total = 99;
拆箱:自动将其包装类拆解成基本数据类型
//自动拆箱
int totalNum = total;//total是int的包装类 [见上装箱代码]
可以看出拆箱过程正好是装箱过程的逆过程。
必须注意,装箱转换和拆箱转换必须遵循类型兼容原则。应尽量避免装箱
我们之所以研究装箱和拆箱,是因为装箱和拆箱会造成相当大的性能损耗(相比之下,装箱要比拆箱性能损耗大),性能问题主要体现在执行速度和字段复制上。因此我们在编写代码时要尽量避免装箱和拆箱,常用的手段为:
使用重载方法。为了避免装箱,很多FCL(Framework Class Library,即Framework类库。)提供许多重载方法
使用泛型。他的主要目的
就是避免值类型和引用类型之间的装箱和拆箱。我们常用的集合类都有泛型的版本,比如ArrayList对应着泛型的 List如果在项目中一个值类型变量需要多次拆装箱,那么可以将这个变量提出来在前面显式装箱
int j = 3; ArrayList a = new ArrayList(); for (int i = 0; i < 100; i++){ a.Add(j); } // 可以修改为: int j = 3; object ob = j; ArrayList a = new ArrayList(); for (int i = 0; i < 100; i++){ a.Add(ob); }
需要拆箱操作和装箱操作的包装类有哪些?【详见下】
List接口的实现类*
- ArrayList*
重点- 数组结构实现,查询快,增删慢;
- JDK1.2版本,运行效率快,线程不安全,不同步。
与LinkedList的区别 - 允许为空
- 有序
- 可重复
- LinkList*
- 双向链表结构实现,增删快,查询慢。
- 允许为空
- 有序
- 可重复
- 线程不安全 ,不同步。
- Vector(基本不用了)
- 数组结构实现,查询快。增删慢;
- JDK1.0版本,运行效率慢,线程安全。
同步(安全)与 不同步(不安全)
同步: 就相当于起床,要先穿衣服,再穿鞋,再洗漱;是按一定顺序的,你做一件事的时候就不能做另一件事。
相当于串行,安全
异步: 就相当于你吃饭和看电视这两件事情是可以一起进行的,能够节约时间,提高效率。
相当于并行,不安全
1.2.2.4.1 ArrayList的具体使用
- 实例化对象【通过List或者ArrayList】
- 添加元素add()方法
- 删除操作remove()或者clear()方法
- 通过重写equals方法来实现
remove(new Students("王五",23));的删除操作
- 通过重写equals方法来实现
@Override
public boolean equals(Object obj) {
//1、判断是不是同一个对象
if (this == obj) {
return true;
}
//2、判断是否为空
if (obj == null) {
return false;
}
//3、判断是否是Student2类
if (obj instanceof Student2) {
Student2 s = (Student2)obj;
//4、比较属性
if (this.name.equals(s.getName()) && this.age == s.getAge()) {
return true;
}
}
//5、不满足就返回false
return false;
}
-
遍历操作- for循环
- foreach增强for循环
- iterator迭代器
- listIterator列表迭代器
-
判断contains()和isEmpty()方法
-
查询indexof()方法
ArrayList 源码分析
DEFAULT_CAPACITY = 10 默认容量
注意:如果没有向集合中添加任何,容量为0,当添加任意一个元素的时候,容量变成10,add()方法的自动扩容,每次扩容是原来的1.5倍。核心copyofelementData 存放元素的数组size 实际大小 初始是0add()方法
第一步: public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!! elementData[size++] = e; return true; } 第二步: private void ensureCapacityInternal(int minCapacity) { ensureExplicitCapacity(calculateCapacity(elementData, minCapacity)); } 第三步: private static int calculateCapacity(Object[] elementData, int minCapacity) { if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { return Math.max(DEFAULT_CAPACITY, minCapacity); } return minCapacity; } 第四步: private void ensureExplicitCapacity(int minCapacity) { modCount++; // overflow-conscious code if (minCapacity - elementData.length > 0) grow(minCapacity); } 第五步【核心代码】:实现自动扩容 private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); }
1.2.2.4.2 LinkList的具体使用
底层是双向链表

- 创建集合(LinkedList()对象)
LinkedList linklist = new LinkedList();
- 增加元素到集合中add(),addAll()
//添加元素
Student2 s1 = new Student2("刘德华", 23);
Student2 s2 = new Student2("郭富城", 25);
Student2 s3 = new Student2("梁朝伟", 21);
//添加元素
linkedList.add(s1);
linkedList.add(s2);
linkedList.add(s3);
linkedList.add(s3); // 可以重复
linkedList.add(null); // 可以为空
linkedlist.addAll(Object o) //添加o里的所有元素到linkedlist集合中
- 删除元素remove(),removeAll(),clear()
linkedList.remove(new Student2("梁朝伟", 21)); // 要想这样写必须重写equals方法
linkedlist.remove(s2);
-
遍历集合对象 for循环、foreach循环、iterator迭代器、listIterator列表迭代器【[同上](4. 遍历集合中的对象`)】
-
查询 indexof(Object o):如果查到返回下标,否则返回-1
//查询
System.out.println(linkedList.indexOf(s2));
- 判断 isEmpty()、contains()、containsAll()同上
LinkedList 源码分析
size = 0 //链表默认大小为0 Node<E> first //指向头节点 起始状态为null Node<E> last //指向尾节点 起始状态为nulladd()方法
核心代码
第一步: void linkLast(E e) { final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null); last = newNode; if (l == null) first = newNode; else l.next = newNode; size++; modCount++; } 第二步: private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }注意:每一个节点都是一个节点对象
1.2.3 Set 子接口
1.2.3.1 Set 子接口的特点*
- 无序:无需的意思是集合是否可重复
无序-不可重复 - 无下标
- 不可重复
- 最多包含一个NULL空
1.2.3.2 Set 接口的方法
1.2.3.3 Set接口的实现类
- HashSet();线程不安全
- TreeSet();线程不安全
1.2.3.3.1 HashSet 【重点】实现类
- 基于HashCode实现元素不重复
- 当存入元素的哈希码相同时,会调用
equals进行确认,如果结果为true,则拒绝后者存入
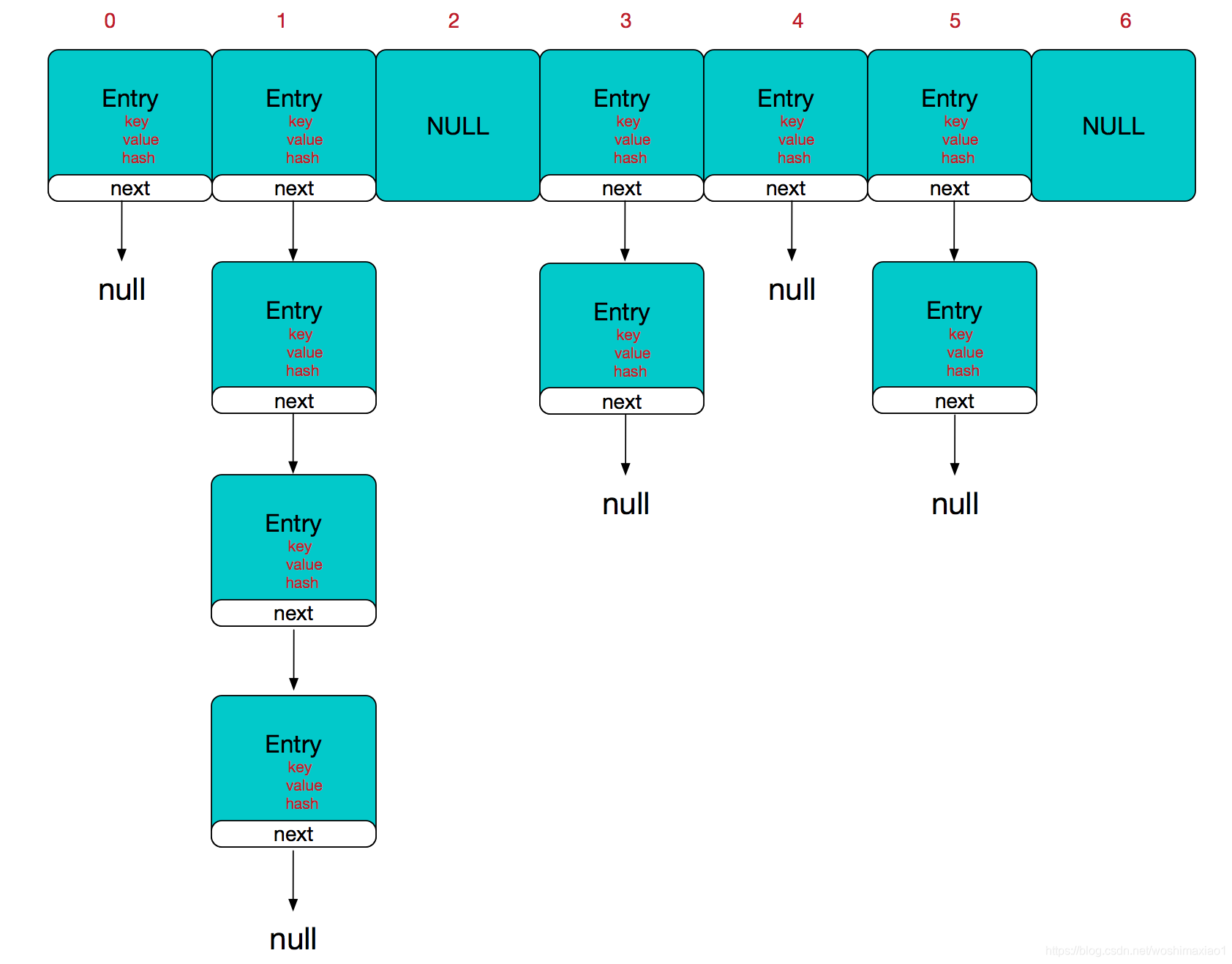
存储结构:数组+链表+红黑树
存储过程(重要依据)
- 根据hashCode计算保存的位置,如果位置为空,直接保存,若不为空,则执行第二步
- 再执行equals方法,如果equals为true,则认为是重复,否则形成链表
存储特点
- 基于HashCode计算元素的存放位置
- 利用31这个质数,减少散列冲突
- 31提高执行效率 31*i-(i<<5)-i转为移位操作
- 当存入的元素的哈希值相同时,回调用equals进行确认,如果为true,则拒绝后者存入
1.2.3.3.2 TreeSet实现类
存储结构:红黑树(二叉排序树+颜色)
存储特点
- 基于排列顺序实现元素的不重复
- 实现SortedSet接口,对集合的元素进行自动排序
- 元素对象的类型必须与Compareable接口一致,指定排序规则
- 通过comparableTo方法确定是否重复为重复元素
问题
public class treeSet1 {
public static void main(String[] args) {
TreeSet<Person> People = new TreeSet<>();
Person person1 = new Person("张三", 23);
Person person2 = new Person("昭武", 45);
Person person3 = new Person("刘能", 22);
Person person4 = new Person("谢广坤", 21);
People.add(person1); //ClassCastException Person cannot be cast to java.lang.Comparable
People.add(person2);
People.add(person3);
People.add(person4);
System.out.println(People.size());
}
}
注意:要想实现对treeSet中存储自定义类型的数据,必须要实现Comapareable接口,compareTo方法返回值=0,认为是重复元素
方法一:
第一步:实现comparable接口
public class Person implements Comparable<Person>
第二步:重写CompareTo方法
//先按姓名比,再按年龄比
@Override
public int compareTo(Person o) {
int n1 = this.getName().compareTo(o.getName());
int n2 = this.getAge() - o.getAge();
return n1 == 0 ? n2 : n1;
}
方法二(建议使用):
第一步:书写封装类 封装类正常写,不需要实现接口。
省略(要书写标准的JavaBean)
第二步:创建一个实现类,去实现Compartor接口
第三步:重写int compare(T o1,T o2) 方法
1、按照年龄排序
public class ComparatorByAge implements Comparator<Students> {
@Override
public int compare(Students o1, Students o2) {
return o1.getAge()-o2.getAge(); //升序
// return o2.getName()-o1.getAge();//降序
}
}
2、按照体重排序
public class ComparatorByWighet implements Comparator<Students> {
@Override
public int compare(Students o1, Students o2) {
return o1.getWeight()-o2.getWeight();//升序
// return o2.getWeight()-o2.getWeight(); //降序
}
}
第三步:通过Collections.sort()按照自定义的规则排序
补充:TreeSet 集合的使用Comparator 实现定制的比较(比较器)
//重写Comapre方法 //创建集合 TreeSet<Person> persons = new TreeSet<>(new Comparator<Person>() { @Override public int compare(Person o1, Person o2) { //自定义比较规则:先比年龄,后比姓名 int n1 = o1.getAge() - o1.getAge(); int n2 = o1.getName().compareTo(o2.getName()); return n1 == 0 ? n2 : n1; } });
二、Map
2.1 Map体系结构

2.1.1 Map集合实现类的存储特点
常见的Collection集合实现类的特点
类型 线程是否安全 允许为空 允许重复 有序(有无下标) 使用情况 HashMap 线程不安全 键和值都可以为空 键可以重复,值不能重复 键是无序的 HashTable 线程安全 键和值都不可以为空 键可以重复,值不能重复 无序 TreeMap 线程不安全 键可以重复,值不能重复 可以实现排序(Comparable接口)
1.1 集合概念
2.1.2 Map父接口
特点
存储一对数据(Key—Value),无序、无下标、键不可以重复、值可以重复。
方法
| 方法摘要 | 方法描述 |
|---|---|
Value | put(K key,V value) // 添加一个对象到集合中,关联键值。key重复覆盖原值 |
Object | get(object key) // 根据键获取值 |
Set(Key) | keySet(K) // 返回所有的key的set集合。 |
Collection<V> | values() // 返回此映射中包含的值的 Collection 集合。 |
Set<Map.Entry<K,V>> | Map.Entry(K,V) 返回此映射中包含的映射关系的 Set 视图。 |
操作
- 创建Map集合:Map<k,v> map = new Map<>();
- 添加元素:put(k,v)
- 删除:remove(Object K)、remove(Object K,Object V)
- 遍历【重点】
//1、keySet遍历
// Set<String> strings = map.keySet();
System.out.println("=========增强for循环==========");
for (String string : map.keySet()) {
String s = map.get(string);
System.out.println(string + "--------" + s);
// System.out.println(s);
}
System.out.println("=========通过迭代器==========");
Iterator<String> iterator = map.keySet().iterator();
while (iterator.hasNext()) {
//获取到值
String s = map.get(iterator.next());
System.out.println(iterator.next() + "--------" + s);
// System.out.println(iterator.next());
}
//使用entrySet
System.out.println("=========使用entrySet==========");
Set<Map.Entry<String, String>> entries = map.entrySet();
for (Map.Entry<String, String> entry : entries) {
//获取Map集合里的键
String key = entry.getKey();
//获取Map集合里的值
String value = entry.getValue();
System.out.println(key+"-----"+value);
}
2.2 Map的实现类
2.2.1 HashMap
2.2.1.1 特点:基于Hash表(数组+链表+红黑树)
- JDK1.2以后,线程不安全,
- 运行效率高,且无序
允许NULL作为key或者values- 键不可重复,值可以重复
2.2.2 TreeMap
2.2.2.1 特点:基于红黑树(二叉排序树)
- 线程不安全
- 无序
- 不允许重复
- 键不允许为NULL
2.2.3 Hashtable
2.2.3.1 特点:基于Hash表
- 线程安全
- 运行效率慢
不允许为NULL作为key或者Value- 不允许重复
注意:
有一种自由的遍历方法Enumeration遍历集合 Enumeration返回的是值得枚举
2.2.3.2 Properties:HashTable的子类
2.2.3.2.1 特点
类表示了一个持久的属性集。Properties 可保存在流中或从流中加载。
【要求key和value都是String类型。常用来配置文件的读取】
三、Collections工具类
3.1 Collections概念
集合工具类,定义了除了存取以外的集合常用的方法
3.2 Collections方法
public static void reverse(List<?> list) //反转集合中的元素
public static void sort(List<?> list) //升序排序集合中的元素
public static void shuffle(List<?> list) //打乱随机重置集合中的元素
public static void binarySearch(List<?> list) //二分查找集合中的元素,前提是有序的
//sort排序
Collections.sort(list);
System.out.println("排序之后:" + list);
//binarySearch()先排序才能二分查找 返回值=位置 找到了,返回-1(负数) 未找到
int i = Collections.binarySearch(list, 12);
System.out.println(i);
int i2 = Collections.binarySearch(list, 32);
System.out.println(i2);
//copy()复制
List<Integer> list1 = new ArrayList<>();
for (int j = 0; j < list.size(); j++) {
list1.add(0);
}
Collections.copy(list1, list);
System.out.println("复制之后的list1集合:" + list1.toString()); //IndexOutOfBoundsException 直接操作会下标越界
//反转
Collections.reverse(list);
System.out.println("反转之后的集合:" + list.toString());
//打乱操作
Collections.shuffle(list);
System.out.println("打乱之后的集合:" + list.toString());
注意:
- 使用binarySearch()方法的时候必须要进行sort()方法的排序
- 使用copy()方法的时候必须要先利用原集合进行对新集合的创建长度
- 数组转集合的时候,转化后的集合是一个受限的集合,不能进行删除和添加操作
















 805
805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











