



 本文详细介绍了Scrapy,一个基于Twisted的异步处理框架,用于高效抓取结构化数据。重点讲解了项目结构、自定义爬虫的创建过程,以及如何解析网页、提取数据和使用pipelines持久化数据。
本文详细介绍了Scrapy,一个基于Twisted的异步处理框架,用于高效抓取结构化数据。重点讲解了项目结构、自定义爬虫的创建过程,以及如何解析网页、提取数据和使用pipelines持久化数据。
scrapy
Scrapy是一个基于Twisted的异步处理框架,是纯Python实现的爬虫框架,是提取结构性数据而编写的应用框架,其架构清晰,模块之间的耦合程度低,可扩展性极强,我们只需要少量的代码就能够快速抓取数据。
爬虫框架
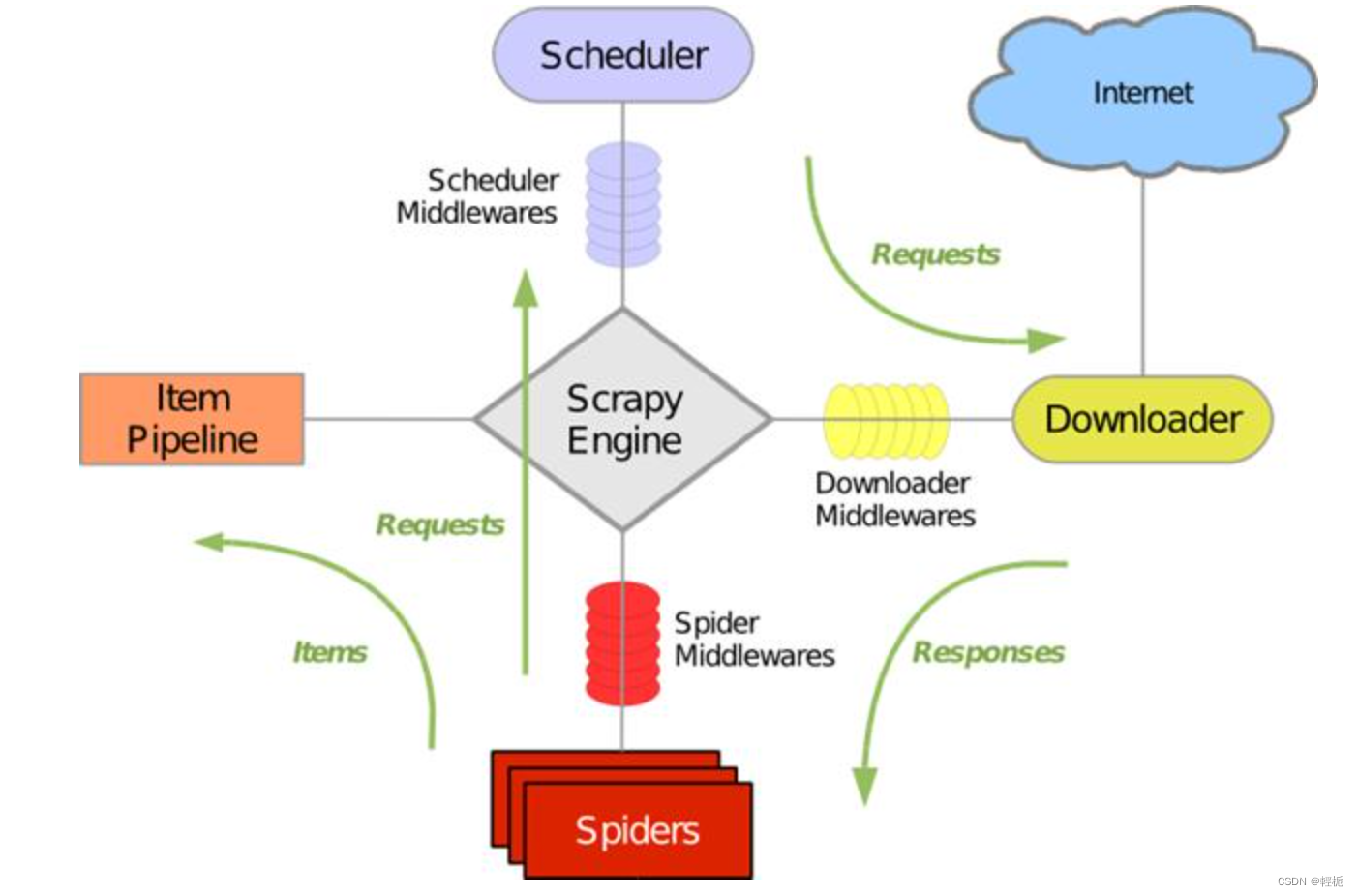
scrapy框架之间的逻辑如图(Engine引擎是整个框架的核心):
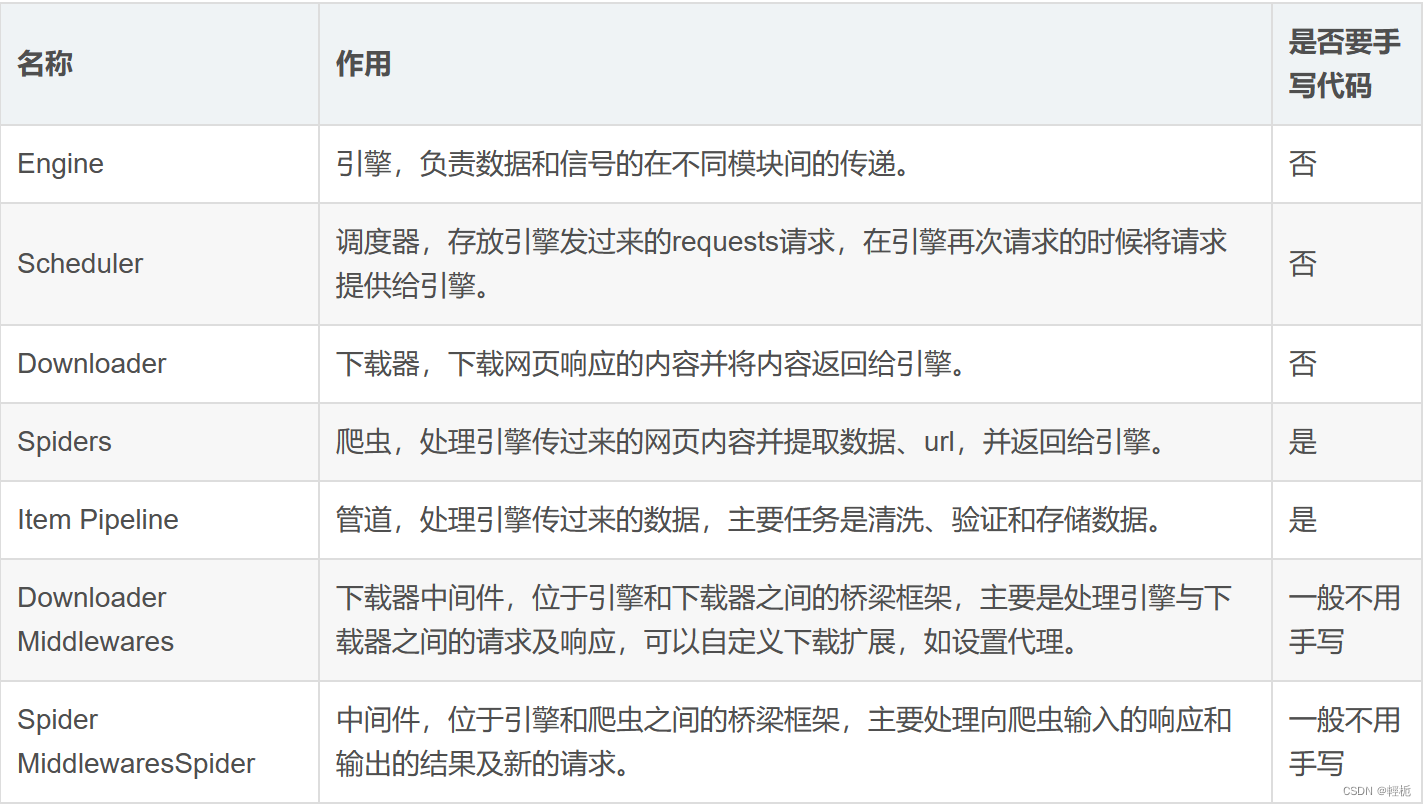
注意:这些模块部分只有Spiders和Item Pipeline需要我们自己手写代码,其他的大部分都不需要。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
开始创建一个爬虫项目:
scrapy startproject <Scrapy项目名>创建一个抓取数据catchdata的项目:

项目结构如图:
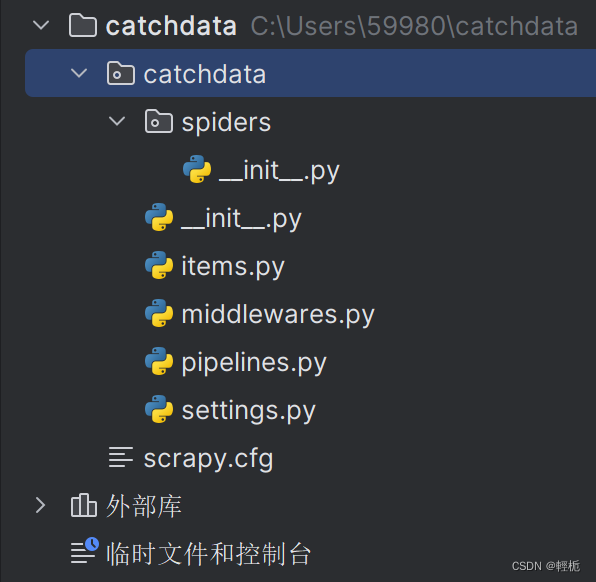
其中:spiders:存放spiders的文件夹;
items.py:Items的定义,定义爬取的数据结构;
middlewares.py:项目中间件文件,定义爬取时的中间件;
pipelines.py:项目管道文件,定义数据管道;
settings:项目设置文件;
scrapy.cfg:Scrapy部署配置文件。
创建爬虫文件
要进行爬虫还需要进行创建爬虫的子项目(以爬取雪球股票数据为例,东方财富是用js写的,爬不了)。需要进入spiders子目录并运行下面命令:
cd catchdata/catchdata/spiders
scrapy genspider <爬虫名字> <允许爬取的域名> # 域名是去掉https://的网址,如:xueqiu.com现在项目结构变成:
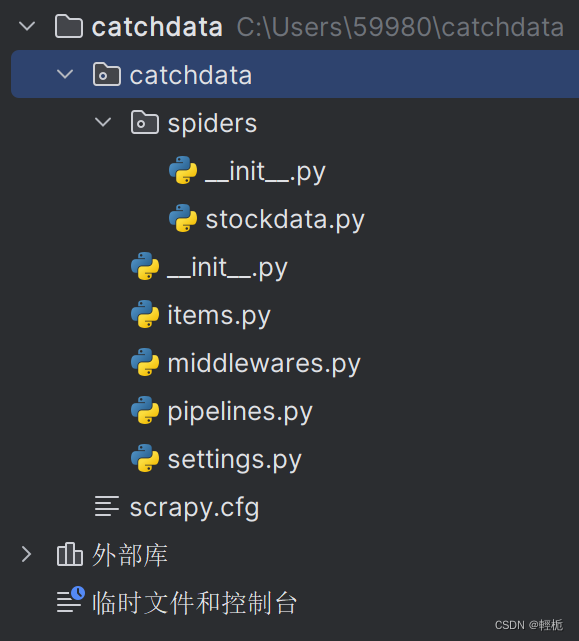
对应的文件内容为:
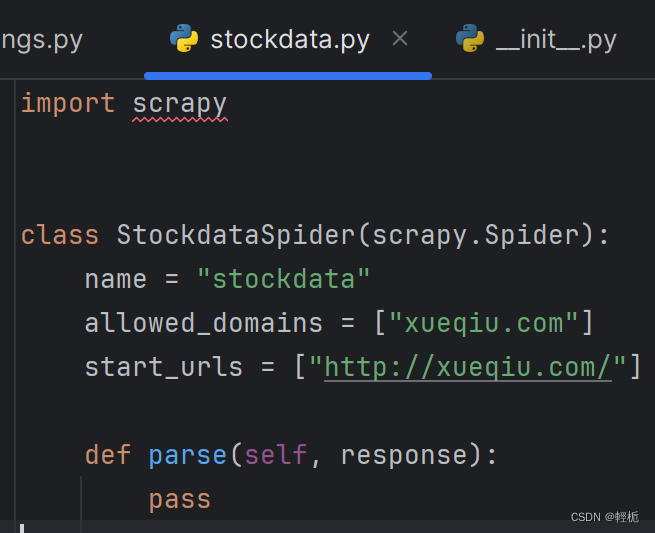
其中:
class StockdataSpider()是自定义spider类,继承自scrapy.Spider
name是定义此爬虫名称的字符串,每个项目唯一的名字,用来区分不同的Spider,启动爬虫时使用scrapy crawl +该爬虫名字;
allowed_domains是允许爬取的域名,防止爬虫爬到其他网站;
start_urls是最开始爬取的url;
parse()方法是负责解析返回响应、提取数据或进一步生成要处理的请求,注意:不能修改这个方法的名字。
parse()提取数据并启动爬虫
大致了解了stockdata.py文件内容后,接下来我们需要了解所爬取网页的结构(一个是对应的网页结构,第二个是对应的数据):
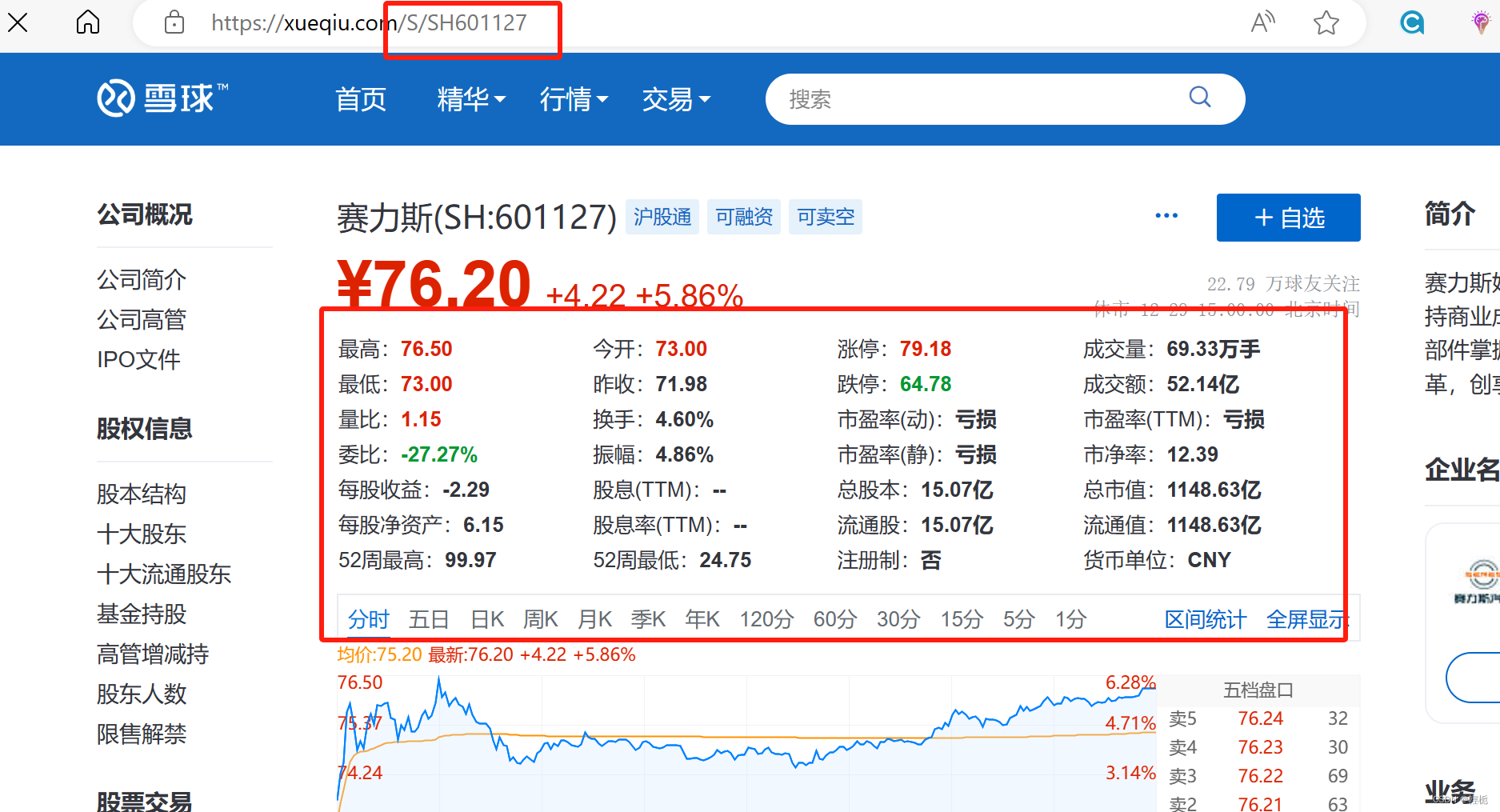
分析网页的网址,发现都是在/S/后加上股票代码,于是我们使用的网址为:URL:https://xueqiu.com/S/ + 股票代码
这里新建一个parse_stock(self, response)的函数用于获得股票信息:
import scrapy
import re
from bs4 import BeautifulSoup
class StockdataSpider(scrapy.Spider):
name = "stockdata"
allowed_domains = ["xueqiu.com"]
start_urls = ["http://xueqiu.com/"]
def parse(self, response):
url = 'https://xueqiu.com/S/' + 'SH601127'#赛力斯
yield scrapy.Request(url, callback=self.parse_stock)
def parse_stock(self, response):
pass
yield作用:在完成这个这个语句(scrapy.Request)后,冻结这个函数(parse),并将结果返回,之后回调这个函数,便会执行接下来的操作(访问下一个网页)。它很像迭代器。
之后进入该网页找到你所需要提取文本和数据的对应元素:(Ctrl+U查看赛力斯行情网页源码,用Ctrl+F对源码进行关键字查询)

获取股票代码在这里用Re正则表达式:
name = re.search(r'<div class="stock-name">(.*?)</div>', response.text).group(1)其中:response为parse函数的传入参数,利用response的text方法,可以获得网页返回的页面(unicode字符串)。
新建一个字典变量item用来存储股票信息:
item={}
item.update({'股票名称': name.__str__()})
获得股票关键信息对源码进行查找分析有一句代码为:
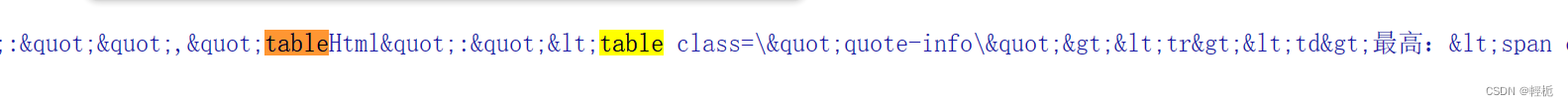
这个就是我们要获取信息对应的表格,用正则表达式提取:

tableHtml = re.search(r'"tableHtml":"(.*?)",', response.text).group(1)
#group(1)表示获得"tableHtml":"(.*?)",中括号内的HTML内容。
soup = BeautifulSoup(tableHtml, "html.parser")
table = soup.table
#接下来用BeautifulSoup库来解析这段HTML代码
#股票信息的标签格式为:例如:<td>最高:<span class=\"stock-rise\">76.50</span></td>
for i in table.find_all("td"):
line = i.text
l = line.split(":")#这里的冒号为中文的冒号(:)!!!而不是英文的(:)
item.update({l[0].__str__(): l[1].__str__()})#将信息用字典格式保存起来
在parse_stock()方法中提取响应数据,具体代码如下所示:
def parse_stock(self, response):
item = {}
if response == "":
exit()
try:
name = re.search(r'<div class="stock-name">(.*?)</div>', response.text).group(1)
item.update({'股票名称': name.__str__()})
tableHtml = re.search(r'"tableHtml":"(.*?)",', response.text).group(1)
soup = BeautifulSoup(tableHtml, "html.parser")
table = soup.table
for i in table.find_all("td"):
line = i.text
l = line.split(":")#这里的冒号为中文的冒号(:)!!!而不是英文的(:)
item.update({l[0].__str__(): l[1].__str__()})
#yield item
print(item)
except:
print("error")
在命令行里面输入:
scrapy crawl stockdata
结果会出现很多日志如:

在settings.py文件任意一行添加以下代码,就可以屏蔽log日志并设置User-Agent代理,代码如下所示:
LOG_LEVEL="WARNING"
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0'
最后结果如图:

stockdata.py里面内容如下:
import scrapy
import re
from bs4 import BeautifulSoup
class StockdataSpider(scrapy.Spider):
name = "stockdata"
allowed_domains = ["xueqiu.com"]
start_urls = ["http://xueqiu.com/"]
def parse(self, response):
url = 'https://xueqiu.com/S/' + 'SH601127'#赛力斯
yield scrapy.Request(url, callback=self.parse_stock)
def parse_stock(self, response):
item = {}
if response == "":
exit()
try:
name = re.search(r'<div class="stock-name">(.*?)</div>', response.text).group(1)
item.update({'股票名称': name.__str__()})
tableHtml = re.search(r'"tableHtml":"(.*?)",', response.text).group(1)
soup = BeautifulSoup(tableHtml, "html.parser")
table = soup.table
for i in table.find_all("td"):
line = i.text
l = line.split(":") # 这里的冒号为中文的冒号(:)!!!而不是英文的(:)
item.update({l[0].__str__(): l[1].__str__()})
# yield item
print(item)
except:
print("error")
更进一步的,从东方财富获取股票代码再从雪球获取数据:
import scrapy
import re
from bs4 import BeautifulSoup
class StockdataSpider(scrapy.Spider):
name = "stockdata"
# allowed_domains = ["xueqiu.com"]
# start_urls = ["http://xueqiu.com/"]
start_urls = ['http://quote.eastmoney.com/stock_list.html']
# def parse(self, response):
# url = 'https://xueqiu.com/S/' + 'SH601127'#赛力斯
# yield scrapy.Request(url, callback=self.parse_stock)
# Parse(StockSpider类中的函数)
def parse(self, response):
for href in response.css('a::attr(href)').extract():
try:
stock = re.search(r"[s][hz]\d{6}", href).group(0)
stock = stock.upper()
url = 'https://xueqiu.com/S/' + stock
yield scrapy.Request(url, callback=self.parse_stock)
except:
continue
def parse_stock(self, response):
item = {}
if response == "":
exit()
try:
name = re.search(r'<div class="stock-name">(.*?)</div>', response.text).group(1)
item.update({'股票名称': name.__str__()})
tableHtml = re.search(r'"tableHtml":"(.*?)",', response.text).group(1)
soup = BeautifulSoup(tableHtml, "html.parser")
table = soup.table
for i in table.find_all("td"):
line = i.text
l = line.split(":") # 这里的冒号为中文的冒号(:)!!!而不是英文的(:)
item.update({l[0].__str__(): l[1].__str__()})
yield item
# print(item)
except:
print("error")
在parse写完后,需要将数据存入文件。通过scrapy的pipelines结构将字典数据存入文件。
在这里原来的类基础上新增几个函数,用来将获得到的股票信息存入文件中:
class CatchdataPipeline:
def open_spider(self,spider):#使用爬虫时
self.f = open('XueQiuStock.txt','w')#打开文件
def close_spider(self,spider):#爬虫结束时
self.f.close()#关闭文件
def process_item(self, item, spider):#处理item
try:
line = str(dict(item)) + '\n'
self.f.write(line)
except:
pass
return item如果你在pipelines文件里是新建的类,没有使用pipelines自带的类,故需要修改setting配置文件,使我们的程序能够找到我们编写的stockPipeline,正常保存文件。找到其中的ITEM_PIPELINES,默认为被注释掉的,需要手动去除,或直接添加。
(PS:修改settings.py的CONCURRENT_REQUESTS属性可以修改scrapy的并发数量,默认16)
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 32完成之后便可以进行爬虫。如果没有出现对应文件可以用以下命令:
scrapy crawl stockdata -o stockdata.csv结果为:
内容为:

----------------------------------------------------------------------------------------------------------------------------
这里介绍翻页和数据传输到pipelines通道部分,有些重复步骤就不写了。
可以参考:Python爬虫——Scrapy框架(附有实战)_scrapy爬虫案例python-CSDN博客
requests
Requests 是一个设计简单而优雅的 HTTP 库。requests 库是一个原生的 HTTP 库,比 urllib3 库更为容易使用。requests 库发送原生的 HTTP 1.1 请求,无需手动为 URL 添加查询串, 也不需要对 POST 数据进行表单编码。相对于 urllib3 库, requests 库拥有完全自动化 Keep-alive 和 HTTP 连接池的功能。requests 库包含的特性如下。
❖ 1Keep-Alive & 连接池
❖ 国际化域名和 URL
❖ 带持久 Cookie 的会话
❖ 浏览器式的 SSL 认证
❖ 自动内容解码
❖ 基本 / 摘要式的身份认证
❖ 优雅的 key/value Cookie
❖ 自动解压
❖ Unicode 响应体
❖ HTTP(S) 代理支持
❖ 文件分块上传
❖ 流下载
❖ 连接超时
❖ 分块请求
❖ 支持 .netrc
pip install requests # 安装import requests
# 发送一个get请求
url = 'http://www.tipdm.com/tipdm/index.html' # 生成get请求
rqg = requests.get(url)
# 查看结果类型
print('查看结果类型:', type(rqg))
# 查看状态码
print('状态码:',rqg.status_code)
# 查看编码
print('编码 :',rqg.encoding)
# 查看响应头
print('响应头:',rqg.headers)
# 打印查看网页内容
print('查看网页内容:',rqg.text)
"""
查看结果类型:<class ’requests.models.Response’>
状态码:200
编码 :ISO-8859-1
响应头:{’Date’: ’Mon, 18 Nov 2019 04:45:49 GMT’, ’Server’: ’Apache-Coyote/1.1’, ’
Accept-Ranges’: ’bytes’, ’ETag’: ’W/"15693-1562553126764"’, ’Last-Modified’: ’
Mon, 08 Jul 2019 02:32:06 GMT’, ’Content-Type’: ’text/html’, ’Content-Length’: ’
15693’, ’Keep-Alive’: ’timeout=5, max=100’, ’Connection’: ’Keep-Alive’}
"""requests基本请求:
requests.get("http://httpbin.org/get") #GET请求
requests.post("http://httpbin.org/post") #POST请求
requests.put("http://httpbin.org/put") #PUT请求
requests.delete("http://httpbin.org/delete") #DELETE请求
requests.head("http://httpbin.org/get") #HEAD请求
requests.options("http://httpbin.org/get") #OPTIONS请求
使用Request发送GET请求
HTTP中最常见的请求之一就是GET 请求,了解利用requests构建GET请求的方法。
GET 参数说明:get(url, params=None, **kwargs):
❖ URL: 待请求的网址
❖ params :(可选)字典,列表为请求的查询字符串发送的元组或字节
❖ **kwargs: 可变长关键字参数
首先,构建一个最简单的 GET 请求,请求的链接为 http://httpbin.org/get ,该网站会判断如果客户端发起的是 GET 请求的话,它返回相应的请求信息,如下就是利用 requests构建一个GET请求
import requests
r = requests.get(http://httpbin.org/get)
print(r.text)
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.24.0",
"X-Amzn-Trace-Id": "Root=1-5fb5b166-571d31047bda880d1ec6c311"
},
"origin": "36.44.144.134",
"url": "http://httpbin.org/get"
}
返回结果中包含请求头、URL 、IP 等信息。那么,对于 GET 请求,如果要附加额外的信息,可以发送带 headers 的请求。
带 headers 的请求
import requests
response = requests.get(’https://www.zhihu.com/explore’)
print(f"当前请求的响应状态码为:{response.status_code}")
print(response.text)
## 返回码:400说明我们请求失败了,因为知乎已经发现我们是一个爬虫,因此需要对浏览器进行伪装,添加对应的 UA 信息。heafers可以进入任意一个网页F12检查选取网络查看任意一个url查看。
import requests
headers = {"user-agent": ’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit
/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36’}
response = requests.get(’https://www.zhihu.com/explore’, headers=headers)
print(f"当前请求的响应状态码为:{response.status_code}")
# print(response.text)
这种伪装浏览器的方法是最简单的反反爬措施之一。
GET 参数说明:携带请求头发送请求的方法
requests.get(url, headers=headers)-headers 参数接收字典形式的请求头
-请求头字段名作为 key ,字段对应的值作为 value
在使用搜索的时候经常发现 url 地址中会有一个 ‘?‘ ,那么该问号后边的就是请求参数,又叫做查询字符串!
通常情况下我们不会只访问基础网页,特别是爬取动态网页时我们需要传递不同的参数获取 不同的内容;GET 传递参数有两种方法,可以直接在链接中添加参数或者利用 params 添加参数。
带参数的请求
在 url 携带参数
直接对含有参数的url发起请求
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit
/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
url = ’https://www.baidu.com/s?wd=python’
response = requests.get(url, headers=headers)
通过 params 携带参数字典
1.构建请求参数字典
2.向接口发送请求的时候带上参数字典,参数字典设置给 params
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# 这是目标url
# url = ’https://www.baidu.com/s?wd=python’
# 最后有没有问号结果都一样
url = ’https://www.baidu.com/s?’
# 请求参数是一个字典 即wd=python
kw = {’wd’: ’python’}
# 带上请求参数发起请求,获取响应
response = requests.get(url, headers=headers, params=kw)
print(response.content)
通过运行结果可以知道,请求的链接自动被构造成了:
http://httpbin.org/get?key2=value2&key1=value1另外,网页的返回类型实际上是str类型,但是它很特殊,是 JSON格式的。所以,如果想直接解析返回结果,得到一个字典格式的话,可以直接调用json() 方法。示例如下:
import requests
r = requests.get("http://httpbin.org/get")
print( type(r.text))
print(r.json())
print(type(r.json()))
< class ’str’ >
{ ’args’ : {}, ’headers’ : { ’Accept’ : ’*/*’ , ’Accept-Encoding’ : ’gzip, deflate’ , ’Host’’httpbin.org’ , ’User-Agent’ : ’python-requests/2.24.0’ , ’X-Amzn-Trace-Id’ : ’Root=1-5fb5b3f9-13f7c2192936ec541bf97841’ }, ’origin’ : ’36.44.144.134’ , ’url’ : ’http://httpbin.org/get’ }
< class ’dict’ >
可以发现,调用 json() 方法,就可以将返回结果是JSON格式的字符串转化为字典。但需要注意的是,如果返回结果不是 JSON 格式,便会出现解析错误,抛出 json.decoder.JSONDecodeError异常。
补充内容,接收字典字符串都会被自动编码发送到 url ,如下:
import requests
headers = {’User-Agent’: ’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36’}
wd = ’张三同学’
pn = 1
response = requests.get(’https://www.baidu.com/s’, params={’wd’: wd, ’pn’: pn},
headers=headers)
print(response.url)
# 输出为:https://www.baidu.com/s?wd=%E9%9B%A8%E9%9C%93%E5%90%8C%E5%AD%A6&pn=1
# 可见 url 已被自动编码
在Headers参数中携带cookie
网站经常利用请求头中的 Cookie 字段来做用户访问状态的保持,那么我们可以在 headers 参数中添加 Cookie ,模拟普通用户的请求。
Cookies 的获取:为了能够通过爬虫获取到登录后的页面,或者是解决通过 cookie 的反爬,需要使用 request 来处理 cookie 相关的请求:
import requests
url = ’https://www.baidu.com’
req = requests.get(url)
print(req.cookies)
# 响应的cookies
for key, value in req.cookies.items():
print(f"{key} = {value}")
# <RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
# BDORZ = 27315首先调用 cookies 属性即可成功得到 Cookies ,可以发现它是 RequestCookieJar 类型。然后用 items() 方法将其转化为元组组成的列表,遍历输出每一个 Cookie 的名称和值,实现 Cookie 的遍历解析。
带上 cookie 、 session 的好处 :能够请求到登录之后的页面。
带上 cookie 、 session 的弊端:一套 cookie 和 session 往往和一个用户对应请求太快,请求次数太多,容易被服务器识别为爬虫。
不需要 cookie 的时候尽量不去使用 cookie 但是为了获取登录之后的页面, 我们必须发送带有 cookies 的请求 我们可以直接用 Cookie 来维持登录状态 , 下面以知乎为例来说明。首先登录知乎,将 Headers 中的 Cookie 内容复制下来。
➢ 从浏览器中复制 User-Agent 和 Cookie
➢ 浏览器中的请求头字段和值与 headers 参数中必须一致
➢ headers 请求参数字典中的 Cookie 键对应的值是字符串
# 不携带cookies的请求
import requests
import re
headers = {"user-agent": ’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit
/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36’}
response = requests.get(’https://www.zhihu.com/creator’, headers=headers)
data = re.findall(’CreatorHomeAnalyticsDataItem-title.*?>(.*?)</div>’,response.text)
print(response.status_code)
print(data)
# 200
# []携带后
import requests
import re
# 构造请求头字典
headers = {
# 从浏览器中复制过来的User-Agent
"user-agent": ’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (
KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36’,
# 从浏览器中复制过来的Cookie
"cookie": ’xxx这里是复制过来的cookie字符串’}
# 请求头参数字典中携带cookie字符串
response = requests.get(’https://www.zhihu.com/creator’, headers=headers)
data = re.findall(’CreatorHomeAnalyticsDataItem-title.*?>(.*?)</div>’,response.text)
print(response.status_code)
print(data)
cookies 参数的使用:headers参数中携带cookie ,也可以使用专门的cookies参数。
❖ 1. cookies 参数的形式:字典
cookies = “cookie 的 name”:“cookie 的 value”
➢ 该字典对应请求头中 Cookie 字符串,以分号、空格分割每一对字典键值对
➢ 等号左边的是一个 cookie 的 name ,对应 cookies 字典的 key
➢ 等号右边对应 cookies 字典的 value
❖ 2.cookies 参数的使用方法
response = requests.get(url, cookies)
❖ 3. 将 cookie 字符串转换为 cookies 参数所需的字典:
cookies_dict = { cookie . split ( ’=’ ) [ 0 ]: cookie . split ( ’=’ ) [- 1 ] for cookie in
cookies_str . split ( ’; ’ ) }
❖ 4. 注意:cookie 一般是有过期时间的,一旦过期需要重新获取
response = requests.get(url, cookies)
import requests
import re
url = ’https://www.zhihu.com/creator’
cookies_str = ’复制的cookies’
headers = {"user-agent": ’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit
/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36’}
cookies_dict = {cookie.split(’=’, 1)[0]:cookie.split(’=’, 1)[-1] for cookie in
cookies_str.split(’; ’)}
# 请求头参数字典中携带cookie字符串
resp = requests.get(url, headers=headers, cookies=cookies_dict)
data = re.findall(’CreatorHomeAnalyticsDataItem-title.*?>(.*?)</div>’,resp.text)
print(resp.status_code)
print(data)
POST请求
代理的使用——proxies 参数
对于某些网站,在测试的时候请求几次,能正常获取内容。但是一旦开始大规模爬取,对于大规模且频繁的请求,网站可能会弹出验证码,或者跳转到登录认证页面,更甚者可能会直接封禁客户端的 IP ,导致一定时间段内无法访问。
那么,为了防止这种情况发生,我们需要设置代理来解决这个问题,这就需要用到 proxies 参数。可以用这样的方式设置:
proxy代理参数通过指定代理ip ,让代理ip对应的正向代理服务器转发我们发送的请求,那么我们首先来了解一下代理ip以及代理服务器。
使用代理的过程
1.代理 ip 是一个 ip ,指向的是一个代理服务器
2.代理服务器能够帮我们向目标服务器转发请求
正向代理和反向代理
前边提到 proxy 参数指定的代理 ip 指向的是正向的代理服务器,那么相应的就有反向服务器;现在来了解一下正向代理服务器和反向代理服务器的区别。
❖ 从发送请求的一方的角度,来区分正向或反向代理
❖ 为浏览器或客户端(发送请求的一方)转发请求的,叫做正向代理
-浏览器知道最终处理请求的服务器的真实 ip 地址,例如 VPN
❖ 不为浏览器或客户端(发送请求的一方)转发请求、而是为最终处理请求的服务器转发请求的,叫做反向代理
-浏览器不知道服务器的真实地址,例如nginx。
代理 ip(代理服务器)的分类
❖ 根据代理 ip 的匿名程度,代理 IP 可以分为下面三类:
➢ 透明代理 (Transparent Proxy) :透明代理虽然可以直接“隐藏”你的 IP 地址,但是还是可以查到你是谁。
目标服务器接收到的请求头如下:
REMOTE_ADDR = Proxy IP
HTTP_VIA = Proxy IP
HTTP_X_FORWARDED_FOR = Your IP➢ 匿名代理 (Anonymous Proxy) :使用匿名代理,别人只能知道你用了代理,无法知道你是谁。
目标服务器接收到的请求头如下:
REMOTE_ADDR = proxy IP
HTTP_VIA = proxy IP
HTTP_X_FORWARDED_FOR = proxy IP➢ 高匿代理 (Elite proxy 或 High Anonymity Proxy) :高匿代理让别人根本无法发现你是在用代理,所以是最好的选择。** 毫无疑问使用高匿代理效果最好 ** 。
目标服务器接收到的请求头如下:
REMOTE_ADDR = Proxy IP
HTTP_VIA = not determined
HTTP_X_FORWARDED_FOR = not determined❖ 根据网站所使用的协议不同,需要使用相应协议的代理服务。
从代理服务请求使用的协议可以分为:
➢ http 代理:目标 url 为 http 协议
➢ https 代理:目标 url 为 https 协议
➢ socks 隧道代理(例如 socks5 代理)等:
✾ 1. socks 代理只是简单地传递数据包,不关心是何种应用协议( FTP 、 HTTP 和HTTPS 等)。
✾ 2. socks 代理比 http 、 https 代理耗时少。
✾ 3. socks 代理可以转发 http 和 https 的请求
proxies 代理参数的使用
为了让服务器以为不是同一个客户端在请求;为了防止频繁向一个域名发送请求被封 ip ,所以需要使用代理 ip
response = requests . get ( url , proxies = proxies )
proxies 的形式:字典
proxies = {
" http ": " http :// 12.34.56.79: 9527 ",
" https ": " https :// 12.34.56.79: 9527 ",
}
注意:如果 proxies 字典中包含有多个键值对,发送请求时将按照 url 地址的协议来选择使用相应的代理ip
import requests
proxies = {
"http": "http://124.236.111.11:80",
"https": "https:183.220.145.3:8080"}
req = requests.get(’http://www.baidu.com’,proxies =proxies)
req.status_code
selenium
实际上是web自动化测试工具,能够通过代码完全模拟人使用浏览器自动访问目标站点并操作来进行web测试。
python+selenium:通过python+selenium结合来实现爬虫十分巧妙。
由于是模拟人的点击来操作,所以实际上被反爬的概率将大大降低。
selenium能够执行页面上的js,对于js渲染的数据和模拟登陆处理起来非常容易。
该技术也可以和其它技术结合如正则表达式,bs4,request,ip池等。
当然由于在获取页面的过程中会发送很多请求,所以效率较低,爬取速度会相对慢,建议用于小规模数据爬取。
#selenium安装,直接通过pip安装即可,导入
pip3 install selenium
from selenium import webdriver浏览器驱动安装
链接: CNPM Binaries Mirror
只需要在上面链接内下载对应版本的驱动器,并放到python安装路径的scripts目录中即可。如果全部都是虚拟环境创建的python不可行,最好安装一个实体版本的python。注意驱动和浏览器版本是向下兼容,驱动要高于浏览器版本。
模拟浏览器操作
browser = webdriver.Chrome() # 打开浏览器
driver.maximize_window() # 最大化窗口
browser.minimize_window() # 最小化窗口
url='https://www.bilibili.com/v/popular/rank/all'#以该链接为例
browser.get(url)#访问相对应链接
browser.close#关闭浏览器
数据定位——web定位
#find_elements_by_xxx的形式是查找到多个元素(当前定位方法定位元素不唯一)
#结果为列表
browser.find_element_by_id('')# 通过标签id属性进行定位
browser.find_element_by_name("")# 通过标签name属性进行定位
browser.find_elements_by_class_name("")# 通过class名称进行定位
browser.find_element_by_tag_name("")# 通过标签名称进行定位
browser.find_element_by_css_selector('')# 通过CSS查找方式进行定位
browser.find_element_by_xpath('')# 通过xpath方式定位
#在chrome中可以通过源代码目标元素右键--Copy--Copy XPath/Copy full XPath
browser.find_element_by_link_text("")# 通过搜索 页面中 链接进行定位
browser.find_element_by_partial_link_text("")# 通过搜索 页面中 链接进行定位 ,可以支持模糊匹配
常用工具:辅助爬虫/降低反爬
加快网页加载速度(不加载js,images等)
options = webdriver.ChromeOptions()
prefs = {
'profile.default_content_setting_values': {
'images': 2,
'permissions.default.stylesheet':2,
'javascript': 2
}
}
options.add_experimental_option('prefs', prefs)
browser = webdriver.Chrome(executable_path='chromedriver.exe', chrome_options=options)
异常捕捉
from selenium.common.exceptions import NoSuchElementException
网页等待加载
由于网速的问题等,进入该网址后页面还没加载出来需要等待,这是最大的问题,有些网页需要等待十几秒才能加载,有些很快,一般设置time.sleep(10)很费时间,这里用到
selenium自带的加载方式
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载
wait=WebDriverWait(browser,10) #显式等待:指定等待某个标签加载完毕
wait1=browser.implicitly_wait(10) #隐式等待:等待所有标签加载完毕
wait.until(EC.presence_of_element_located((By.CLASS_NAME,'tH0')))
在输入框中输入数据
ele = driver.find_element_by_id("kw") # 找到id为kw的节点
ele.send_keys("名称") # 向input输入框输入名称
#也可以driver.find_element_by_id("kw").send_keys("名称")
网页点击(如点击下一页,或者点击搜索)
ele = driver.find_element_by_id("kw") # 找到id为kw的节点
ele.send_keys("数学") # 向input输入框输入数据
ele = driver.find_element_by_id('su') # 找到id为su的节点(百度一下)
ele.click() # 模拟点击
打印网页信息
print(driver.page_source) # 打印网页的源码
print(driver.get_cookies()) # 打印出网页的cookie
print(driver.current_url) # 打印出当前网页的url
切换iframe
有时候会碰到网页用iframe来作为文档框架
driver.switch_to.frame("iframe的id")
网页滚动(更像真人)
# 1.滚动到网页底部
js = "document.documentElement.scrollTop=800"
# 执行js
driver.execute_script(js)
# 滚动到顶部
js = "document.documentElement.scrollTop=0"
driver.execute_script(js) # 执行js
随机等待几秒再操作(更像真人)
import time
import random
time.sleep(random.randint(0,2))

















 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









