






前面谈到了简单的一个示例代码,实际上里面的策略源码和模型回测源码都需要好好了解,他这个回测系统和我之前用到的回测策略代码有不一样的地方,量化策略掌握源码是基本的技能。
Qlib内置了A股、美股两个市场的历史数据,上一篇文章也谈到过,可以通过运行如下的脚本把数据自动获取到本地。
# get 1d data
python -m qlib.run.get_data qlib_data --target_dir ~/.qlib/qlib_data/cn_data --region cn
# get 1min data
python -m qlib.run.get_data qlib_data --target_dir ~/.qlib/qlib_data/cn_data_1min --region cn --interval 1min而且支持从yahoo finance对数据进行日更,使用的脚本在scripts/data_collector。
但我们希望使用ETF做投资,那么就需要自己来扩展数据源。Qlib提供了相应的工具scripts/dump_bin.py
dump_bin是把csv格式的数据转换为qlib的格式,这样qlib就可以使用。
#注意要修改成自己的路径
python scripts/dump_bin.py dump_all --csv_path ~/.qlib/csv_data/my_data --qlib_dir ~/.qlib/qlib_data/my_data --include_fields open,close,high,low,volume,factor
#--csv_path指定本地路径上csv目录
#--qlib_dir是qlib的数据目录
#--include_fields 包含的字段,OHLCV 好理解,就是常规的价量数据,factor是复权因子,通常factor = adjusted_price / original_priceQlib内置的数据采集里,已经支持了采集基金数据,是网上收集公募基金的数据,由于我们量化仅需要ETF的数据,所以可以从三方下载对应数据(简单写了一个脚本拉取基金数据的历史数据):
import akshare as ak
fund_inner = ak.fund_exchange_rank_em()
for i in range(len(fund_inner['基金代码'])):
fund_hist = ak.fund_etf_hist_em(symbol=fund_inner['基金代码'][i], period="daily", start_date=fund_inner['成立日期'][i], end_date="20231231", adjust="hfq")
fund_hist.rename(columns={'日期':'date','开盘':'open','收盘':'close','最高':'high','最低':'low','成交量':'volume'}, inplace=True)
name = 'C:/Users/59980/funddata/'+ fund_inner['基金代码'][i] + '.csv'
fund_hist.to_csv(name,index = False)然后使用前面提及的dump_bin工具,可以把这个csv目录转为qlib可以使用的数据存储格式。
python C:\Users\59980\qlib\scripts\dump_bin.py dump_all --csv_path C:\Users\59980\funddata --qlib_dir ~/.qlib/qlib_data/fund_data --date_field_name date --include_fields open,close,high,low,vol
需要注意的点:bin转换默认需要一个date字段,如果csv里的字段名称不一样,可以使用—date_field_name来指定。Include_fields是默认要处理的字段,比如你的csv里有PE,PB可以在这里指定。运行之后的结果为:
数据的加载与使用按照下面方式操作:
在qlib.qlib子文件夹下创建一个文件(如fundceshi.py),内容如下:
import qlib
from qlib.config import REG_CN
from qlib.data import D
import matplotlib.pyplot as plt
class QlibMgr:
#初始化要加载数据的目录
def __init__(self):
provider_uri = "~/.qlib/qlib_data/fund_data" # target_dir
qlib.init(provider_uri=provider_uri, region=REG_CN)
#加载数据
def load_df(self,instruments,fields,start_time,end_time):
df = D.features(instruments, fields, start_time=start_time,end_time=end_time, freq='day')
return df
#实例化,这里要确认好起止日期内对应的基金有数据,后面其他股票也可按照这种方式加载进qlib平台进行回测
fun = QlibMgr()
df = fun.load_df(instruments=['159503'], fields=['$close'], start_time='2023-07-01', end_time='2023-12-31')
# print(df.columns)
# print(df.index)
# print(df.head(3))
se = df.loc['159503']['$close']
se.plot()
plt.show()
运行后得到的结果为:
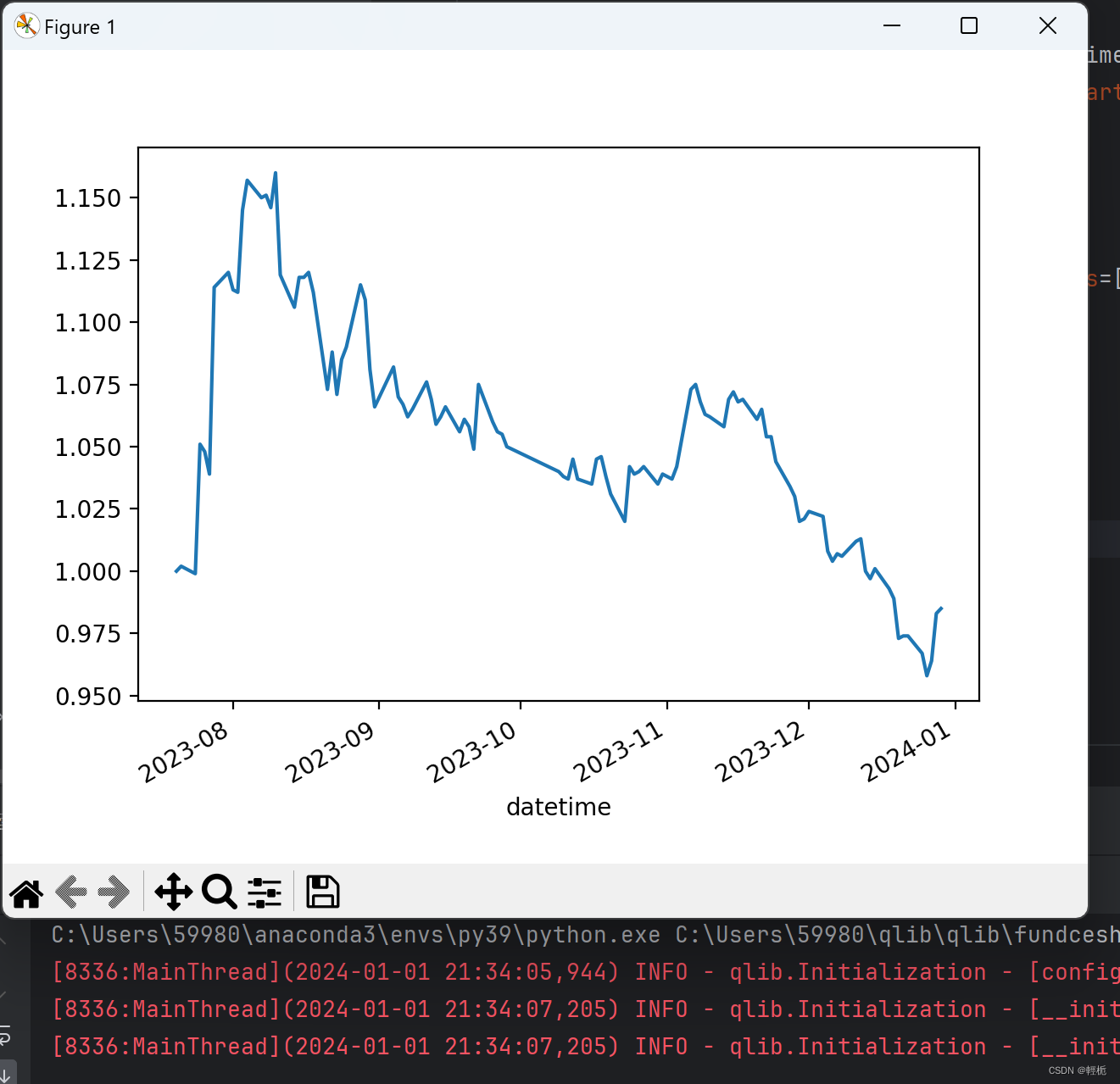
后面对数据的使用,计算指标,可视化都可以按照自己的意愿展开。Qlib是一个设计完整但松耦合的框架,这一点非常好。比如一个常见的回测框架Backtrader,你要扩展自己的东西,非常难。
学会将数据加载进qlib后,接下来使用Qlib进行数据标注与自定义指标计算。
数据标注:我们已经加载的OHLCV数据,并进行了时间序列相关分析,要从价量数据里进一步计算特征,传统技术分析指标,如均线、MACD,RSI,布林带都是衍生指标,也是特征之一。传统量化系统,需要自己写指标公式或者借助Talib这样的工具包。这对于传统技术分析,指标比较少,通常就2-3个是比较容易实现和管理的。但对于机器学习,我们可以同步计算上百个特征,那么如果有这种方式就难以管理了。
Qlib内置了表达式引擎,可以通过'$high-$low',这样的表达式来计算衍生指标。更复杂的指标,比如计算MACD:
MACD_EXP = '(EMA($close,12) - EMA($close,26))/$close - EMA((EMA($close,12) - EMA($close,26))/$close,9)/$close'$close是取dataframe里已有的字段,EMA是表达式引擎内置的函数。Qlib的表达式引擎里预置了很多常用的,时间序列计算的有效函数。
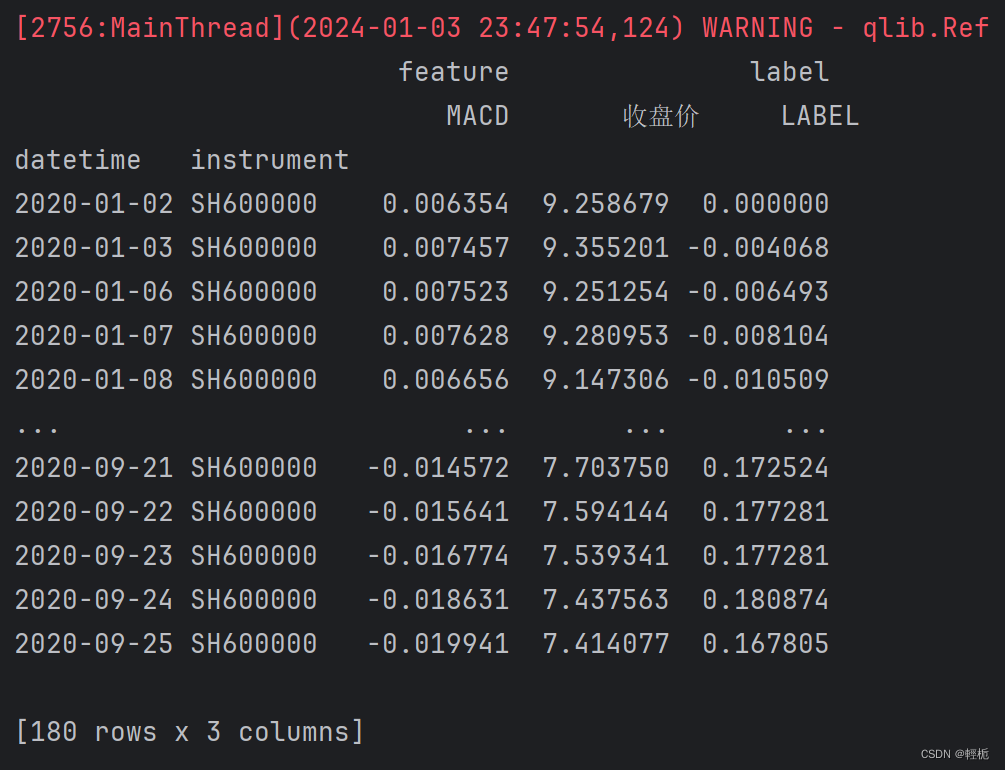
from qlib.data.dataset.loader import QlibDataLoaderQlibDataloader比D.features更高层的API,用法类似,定义fields就是原始字段及衍生的表达式,而且可以定义labels。
Label是机器学习的标签,Ref($close,-2)是T+2的收盘价,这里使用的label是T+2天的收益率,也就是未来2天的收益率——这是考虑A股市场T+1的机制,在T+1天买入,T+2天卖出。
具体代码为:
import qlib
qlib.init()
from multiprocessing import freeze_support
from qlib.data.dataset.loader import QlibDataLoader
if __name__ == '__main__':
freeze_support()
MACD_EXP = '(EMA($close, 12) - EMA($close, 26))/$close - EMA((EMA($close, 12) - EMA($close, 26))/$close, 9)/$close'
fields = [MACD_EXP,'$close'] # MACD
names = ['MACD','收盘价']
labels = ['Ref($close, -2)/Ref($close, -1) - 1'] # label
label_names = ['LABEL']
data_loader_config = {"feature": (fields, names),"label": (labels, label_names)}
data_loader = QlibDataLoader(config = data_loader_config)
df = data_loader.load(instruments='csi300', start_time='2020-01-01', end_time='2020-12-31')
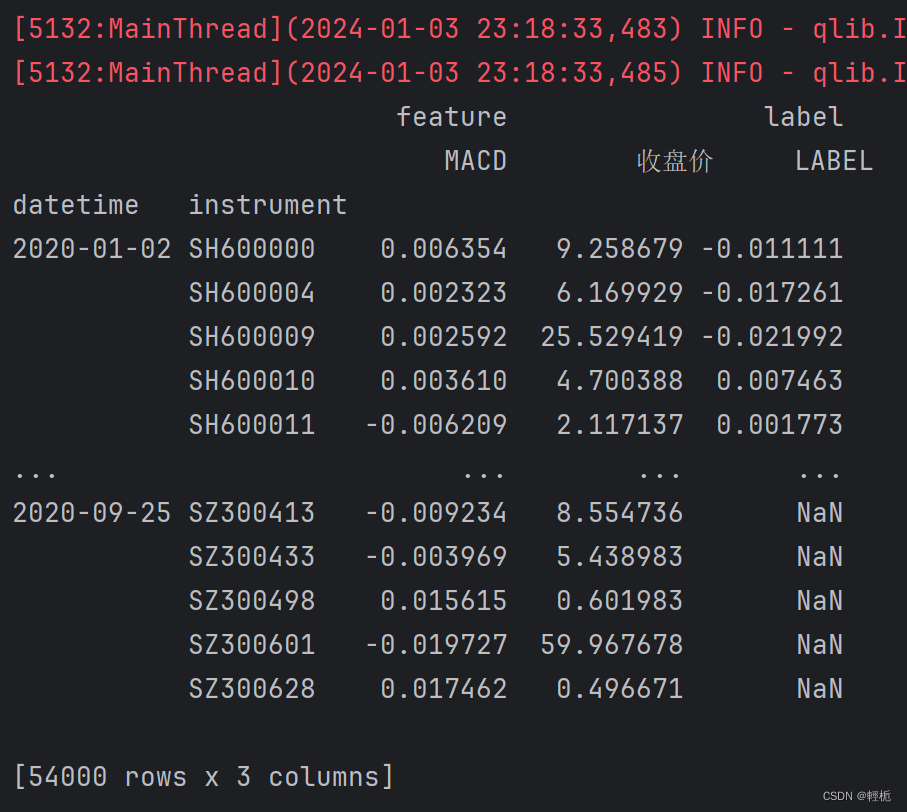
print(df)首先导入qlib进行初始化,然后导入多线程包(不然会有大量警告报错),导入 QlibDataLoader 类用于加载 Qlib 中用于训练或测试模型的数据。MACD_EXP定义好技术指标,fields定义用于训练或测试的特征字段,赋列标题,labels定义标签表达式用于训练或测试的目标变量。它根据前两个收盘价计算股票的回报率。然后加载配置文件,在加载数据时到路径qlib_data\cn_data\instruments下查看有哪些数据txt可以使用,其次起止时间不要太窄(在这里可以查看源码逻辑和数据集所在时间段,看了好久才弄明白),最后就可以显示数据了:
内置指标体系与自定义指标计算
其实Qlib内置了两个指标体系, Alpha158和Alpha360: 158和360分别是指标的数量:
from qlib.contrib.data.handler import Alpha158
if __name__ == '__main__':
freeze_support()
data_handler_config = {"start_time": "2016-01-01", "end_time": "2020-08-01","fit_start_time": "2016-01-01","fit_end_time": "2018-12-31","instruments": "csi300"}
h = Alpha158(**data_handler_config)
# get all the columns of the data
print(h.get_cols())
# fetch all the labels
print(h.fetch(col_set="label"))
# fetch all the features
print(h.fetch(col_set="feature"))结果如图:

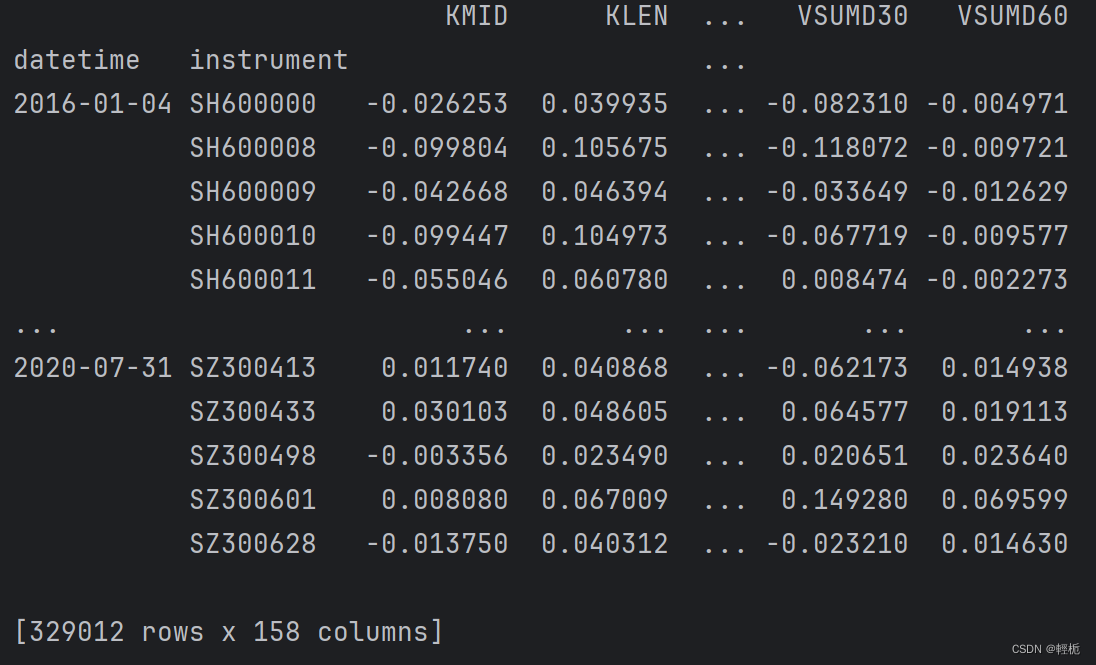
查看源码发现它们使用一个类来实现,都继承了DataHandlerLP,需要实现两个函数,一个是定义feature,另一个是label,目前我也不太了解原理,大致实现过程:
class Alpha360(DataHandlerLP):
def get_label_config(self):
return (["Ref($close, -2)/Ref($close, -1) - 1"], ["LABEL0"])
def get_feature_config(self):
pass先简单了解一下它的实现就好,做主动投资,还是从最简单的动量策略入手,走通整个循环,如下是Qlib支持的运算符号。
OpsList = [Ref,Max,Min,Sum,Mean,Std,Var,Skew,Kurt,Med,Mad,Slope,Rsquare,Resi,Rank,Quantile,Count,EMA,WMA,Corr,Cov,Delta,Abs,Sign,Log,Power,Add,Sub,Mul,Div,Greater,Less,And,Or,Not,Gt,Ge,Lt,Le,Eq,Ne,Mask,IdxMax,IdxMin,If]过去5天的动量标签为:Ref($close,0)/Ref($close,5)-1,非常方便的就把相应的特征指标计算出来,把数据做好标注。这样就得到了一个完整的数据集用于机器学习训练,结果如图:
一个典型的机器学习驱动的量化模型会分成如下几个主要步骤:
首先是基本数据加载,从价量的角度看就是OHLCV等数据;
其次是数据标注,计算因子和label;
然后把数据分割成训练集和测试集选择合适的模型,并配置适当的参数进行模型训练。
最后利用模型数据样本外数据进行回测,得到回测结果。对回测结果进行可视化。
上述过程熟悉过后,学习仓位分析和模型分析。
仓位分析包含以下几个模块:
report_graph
score_ic_graph
cumulative_return_graph
risk_analysis_graph
rank_label_graph模型分析只有一个模块:模型性能分析。
model_performance_graph源代码路径是:import qlib.contrib.report as qcr
##---------------------------------------------------------------------------------------------------------------##
介绍策略之前需要先看一下因子构建部分,因子模型是量化投资中一种重要的研究方法,它通过收集和分析一系列的因子(或特征)来预测资产的未来表现。
首先数据初始化:在Python中运行Qlib程序前,需要首先初始化运行环境,命令为qlib.init:
import qlib
from qlib.config import REG_CN
from qlib.data import D
from qlib.contrib.data.handler import Alpha158
data_uri = "~/.qlib/qlib_data/cn_data"
#1.初始化并获取日历
qlib.init(provider_uri=data_uri, region=REG_CN)再获取交易日期和全部股票代码:
# 获取交易日历
tradedate = D.calendar(start_time='2020-01-01', end_time='2023-12-31',freq='day')
print(tradedate[:1])
#2.获取所有证券代码
instruments = D.instruments(market='all')
stock_list = D.list_instruments(instruments=instruments,start_time='2020-01-01',end_time='2023-12-31',as_list=True)
#展示后5个股票代码
print(stock_list[-2:])
接着获取字段数据:调用qlib.data.features模块可以获取指定股票指定日期指定字段数据,例如下图展示获取(SH000300)在2020-01-01~2023-12-31日频后复权收盘价和成交量:
#3.获取指定股票指定日期指定字段数据
features_df = D.features(instruments=['SH000300'],fields=['$close',' $volume'],start_time='2020-01-01', end_time='2023-12-31',freq='day')
print(features_df.head())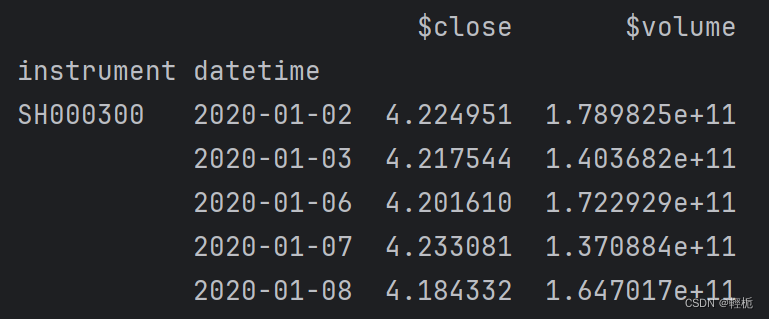
然后构建股票池:使用qlib.data.filter.NameDFilter命令进行股票名称静态筛选,参数name_rule_re为纳入股票代码的正则表达式,如HK[0-9!]表示以HK开头,后续为数字或感叹号的股票代码,感叹号代表目前已退市股票。其次,使用qlib.data.filter.ExpressionDFilter命令进行股票因子表达式的动态筛选,参数rule_expression为入选的因子表达式,如$close>=1代表收盘价应大于等于1元。随后,通过qlib.data.instruments命令的参数filter_pipe,将两个筛选条件组装到一起:
if __name__=='__main__': # 一定要加这一行
# 股票名称静态筛选
from qlib.data.filter import NameDFilter, ExpressionDFilter
# 静态Filter:深交所A股
nameDFilter = NameDFilter(name_rule_re='SZ[0-9!]')
# 动态Filter:后复权价格大于等于5元
expressionDFilter = ExpressionDFilter(rule_expression='$close>=5')
# 按以上两个过滤条件获取新的股票代码集
instruments = D.instruments(market='all', filter_pipe=[nameDFilter, expressionDFilter])
stock_list = D.list_instruments(instruments=instruments, start_time='2020-01-01', end_time='2023-12-31', as_list=True)
# 展示条件过滤后的5个股票代码
print(stock_list[-2:])再构建因子:Qlib提供Alpha158和Alpha360两类量价因子库,用户也可根据需要自定义因子库。源码位于qlib/contrib/data/handler.py,主要包括四个:
配置文件对应的代码说明如下:
def parse_config_to_fields(config):
#create factors from config
config = {
'kbar': {}, # whether to use some hard-code kbar features
'price': { # whether to use raw price features
'windows': [0, 1, 2, 3, 4], # use price at n days ago
'feature': ['OPEN', 'HIGH', 'LOW'] # which price field to use
},
'volume': { # whether to use raw volume features
'windows': [0, 1, 2, 3, 4], # use volume at n days ago
},
'rolling': { # whether to use rolling operator based features
'windows': [5, 10, 20, 30, 60], # rolling windows size
'include': ['ROC', 'MA', 'STD'], # rolling operator to use
#if include is None we will use default operators
'exclude': ['RANK'], # rolling operator not to use
}
}其中参数data_handler_config相当于配置文件,字典类型,用来定义完整数据起止日期(start_time和end_time),拟合数据起止日期(fit_start_time和fit_end_time),股票池(instruments)等。
拟合数据起止日期区间应为完整数据起止日期数据的子集。
拟合数据日期(训练和验证集)和余下日期(测试集)在数据预处理的方式上有所不同。
生成Alpha158因子调用qlib.contrib.data.handler模块下的Alpha158类,具体命令为:
from qlib.contrib.data.handler import Alpha158
h = Alpha158(**data_handler_config)执行上述指令后,程序将计算从start_time至end_time的当期因子值和下期收益,分别作为后续AI模型训练的特征和标签。
代码中使用了两个处理器,infer_processors用于模型预测,learn_processors用于模型训练。
infer_processors = check_transform_proc(infer_processors, fit_start_time, fit_end_time)
learn_processors = check_transform_proc(learn_processors, fit_start_time, fit_end_time)计算代码如下:
"""
Qlib提供Alpha158和Alpha360两类量价因子库,
用户也可根据需要自定义因子库。源码位于qlib/contrib/data/handler.py,主要包括四个类:
Alpha360(DataHandlerLP)、Alpha360vwap(Alpha360)
Alpha158(DataHandlerLP)、Alpha158vwap(Alpha360)
"""
# 计算从start_time至end_time的当期因子值和下期收益,分别作为后续AI模型训练的特征和标签
if __name__=='__main__':
instruments = D.instruments(market='all')
stock_list = D.list_instruments(instruments=instruments,
start_time='2020-01-01',
end_time='2023-11-30',
as_list=True)
# 设置日期、股票池等参数
data_handler_config = {
"start_time":"2020-01-01",
"end_time":"2023-11-30",
"fit_start_time":"2020-01-01",
"fit_end_time":"2023-06-30",
"instruments":instruments
}
h =Alpha158(**data_handler_config)
# 获取列名(因子名称)
print(h.get_cols())跑出来的因子对应的算子计算公式在handler.py中可以看到。
#获取T日每只股票的标签数据(收益,及涨幅)
# 默认参数下,股票t日的标签对应t+2日收盘价相对于t+1日收盘价的涨跌幅,相当于t日收盘后发信号,t+1日收盘时刻开仓,t+2日收盘时刻平仓。
Alpha158_df_label = h.fetch(col_set="label")
print(Alpha158_df_label) # [676964 rows x 1 columns] 标签为 LABEL0 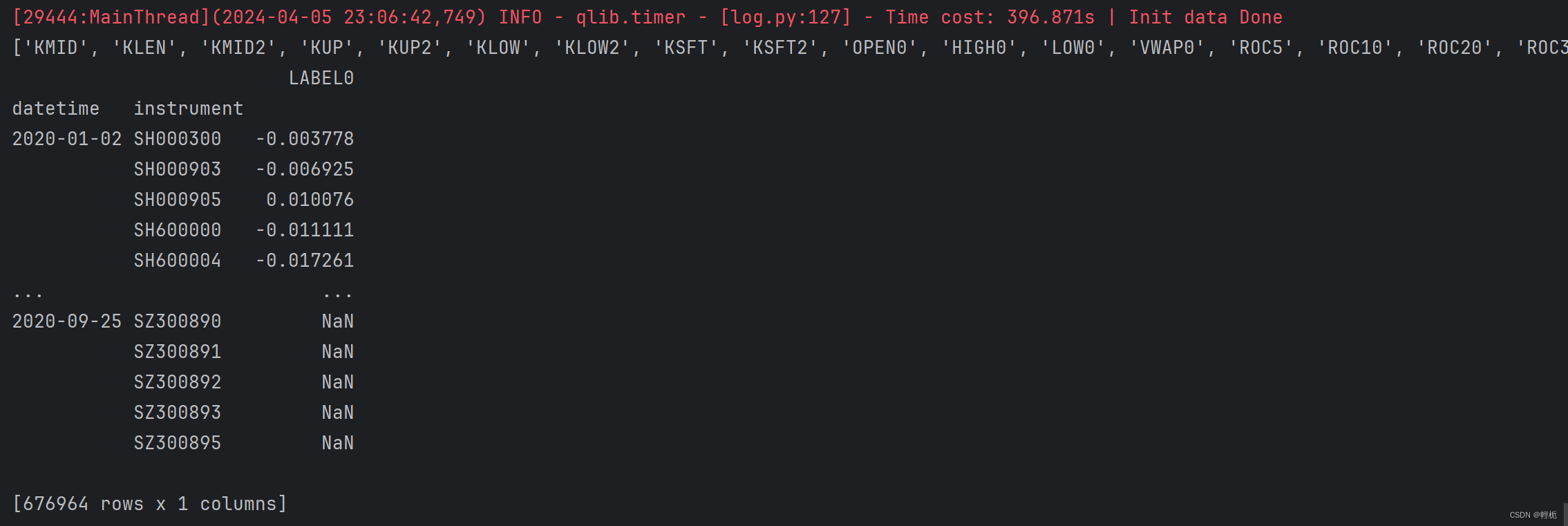
#获取T日每只股票的特征(因子值)值
# 获取T日每只股票的特征(因子值)值
Alpha158_df_feature = h.fetch(col_set="feature")
print(Alpha158_df_feature) # [676964 rows x 158 columns] 共计158个因子值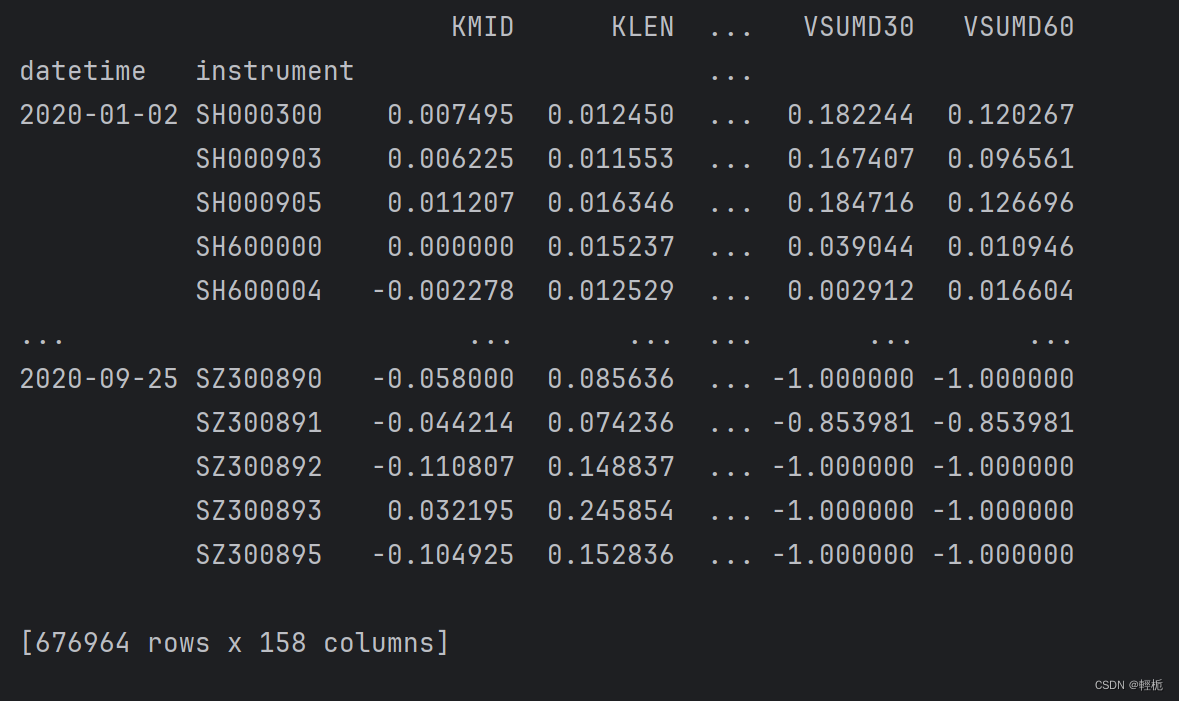
##---------------------------------------------------------------------------------------------------------------##
从一个完整的策略进行分析:提前安装好 pip install nbformat==5.10.4
策略思路:TopkDropout策略,基本原理:每日等权持有topk=50只股票,同时每日卖出持仓股票中最新预测收益最低的n_drop=5只股票,买入未持仓股票中最新预测收益最高的n_drop=5只股票。策略参数有:
# 参数说明
"strategy": {
"class": "TopkDropoutStrategy", # 策略名称
"module_path": "qlib.contrib.strategy.signal_strategy", # 策略所在路径
"kwargs": { # TopkDropout 策略参数
"model": model, # 模型
"dataset": dataset, # 数据集
"topk": 50, # 每日持仓股票
"n_drop": 5, # 每日换仓股票
}
}首先数据准备:
import qlib
import pandas as pd
from qlib.constant import REG_CN
from qlib.utils import exists_qlib_data, init_instance_by_config
from qlib.workflow import R
from qlib.workflow.record_temp import SignalRecord, PortAnaRecord # **
# record_temp方法核心功能为产生和保存特定的记录
from qlib.utils import flatten_dict
from qlib.contrib.report import analysis_model, analysis_position # 仓位分析
if __name__=='__main__':
#1.初始化并获取日历
data_uri = "~/.qlib/qlib_data/cn_data"
qlib.init(provider_uri=data_uri, region=REG_CN)
market = "csi100" # 股票池
benchmark = "sh000300" # 比较基准模型训练:数据集和模型参数初始化->初始模型和数据集实例->model.fit(dataset)->
模型参数说明:
"model": {
"class": "LGBModel", # 模型名称是LGBmodel
"module_path": "qlib.contrib.model.gbdt", # AI模型所在路径
"kwargs": { # LGBmodel的超参
"loss": "mse", # 损失函数,此处设置为均方误差
"colsample_bytree": 0.8879, # 列采样比列
"learning_rate": 0.0421, # 学习率
"subsample": 0.8789, # 行采样比例
"lambda_l1": 205.6999, # L1正则化惩罚系数
"lambda_l2": 580.9768, # L2正则化惩罚系数
"max_depth": 8, # 最大树深
"num_leaves": 210, # 最大叶子节点数
"num_threads": 20, # 最大并行线程数
}
}数据集参数说明:
"dataset": {
"class": "DatasetH", # 数据集名称
"module_path": "qlib.data.dataset", # 数据集所在路径
"kwargs": { # DatasetH模型参数
"handler": { # 因子库参数
"class": "Alpha158", # 因子库名称,此处使用qlib自带的Alpha158
"module_path": "qlib.contrib.data.handler", # 因子库路径
"kwargs": data_handler_config, # Alpha158的参数
},
"segments": { # 时间区间划分参数
"train": ("2008-01-01", "2014-12-31"), # 训练集
"valid": ("2015-01-01", "2016-12-31"), # 验证集
"test": ("2017-01-01", "2020-08-01"), # 测试集
},
},
}
# 其中data_handler_config参数:
data_handler_config = {
"start_time": "2008-01-01",
"end_time": "2020-08-01",
"fit_start_time": "2008-01-01",
"fit_end_time": "2014-12-31",
"instruments": market,
}接着训练模型:在这里要依次定义好策略模型、数据集、数据处理方式配置以及仓位分析的配置:
# 划分数据集
data_handler_config = {
"start_time": "2008-01-01",
"end_time": "2020-08-01",
"fit_start_time": "2008-01-01",
"fit_end_time": "2014-12-31",
"instruments": market,
}
# 定义回测任务
task = {
"model": {
"class": "LGBModel",
"module_path": "qlib.contrib.model.gbdt",
"kwargs": {
"loss": "mse",
"colsample_bytree": 0.8879,
"learning_rate": 0.0421,
"subsample": 0.8789,
"lambda_l1": 205.6999,
"lambda_l2": 580.9768,
"max_depth": 8,
"num_leaves": 210,
"num_threads": 10,
},
},
"dataset": {
"class": "DatasetH",
"module_path": "qlib.data.dataset",
"kwargs": {
"handler": {
"class": "Alpha158",
"module_path": "qlib.contrib.data.handler",
"kwargs": data_handler_config,
},
"segments": {
"train": ("2008-01-01", "2014-12-31"),
"valid": ("2015-01-01", "2016-12-31"),
"test": ("2017-01-01", "2020-08-01"),
},
},
},
}
# model initiaiton
model = init_instance_by_config(task["model"])
dataset = init_instance_by_config(task["dataset"])
# PortAnaRecord:config内要有strategy,executor和backtest的参数设置
"""
PortAnaRecord继承于父类ACRecordTemp,在.generate()函数中加入了Automatically Checking步骤,这个步骤不仅可以防止重复地生成和保存artifact,具体参考源吗
"""
port_analysis_config = {
# 策略执行器
"executor": {
"class": "SimulatorExecutor",
"module_path": "qlib.backtest.executor",
"kwargs": {
"time_per_step": "day", # 回测频率
"generate_portfolio_metrics": True,
},
},
# 策略
"strategy": {
"class": "TopkDropoutStrategy",
"module_path": "qlib.contrib.strategy.signal_strategy",
"kwargs": {
"model": model,
"dataset": dataset,
"topk": 50, # 选择得分前50的股票作为投资组合
"n_drop": 5, # 每个投资周期去除的股票
},
},
# 回测
"backtest": {
"start_time": "2017-01-01",
"end_time": "2020-08-01",
"account": 100000000, # 初始资金
"benchmark": benchmark, # 基准,这里设置为benchmark=csi100
"exchange_kwargs": {
"freq": "day", # 日频交易
"limit_threshold": 0.095, # 最多移动多少比例
"deal_price": "close", # 收盘价买入
"open_cost": 0.0005, # 开仓手续费
"close_cost": 0.0015, # 清仓手续费
"min_cost": 5, # 最小交易费用
},
},
}进行训练:模型按设置的参数进行训练直到验证分数50轮内没有提高,在所有训练结果中会显示分数最高一轮的训练参数值和最好的验证参数值。
with R.start(experiment_name="train_model"):
R.log_params(**flatten_dict(task))
model.fit(dataset) #拟合模型
R.save_objects(trained_model=model)
rid = R.get_recorder().id # 最好的训练参数值和最好的验证参数值
结果如下:
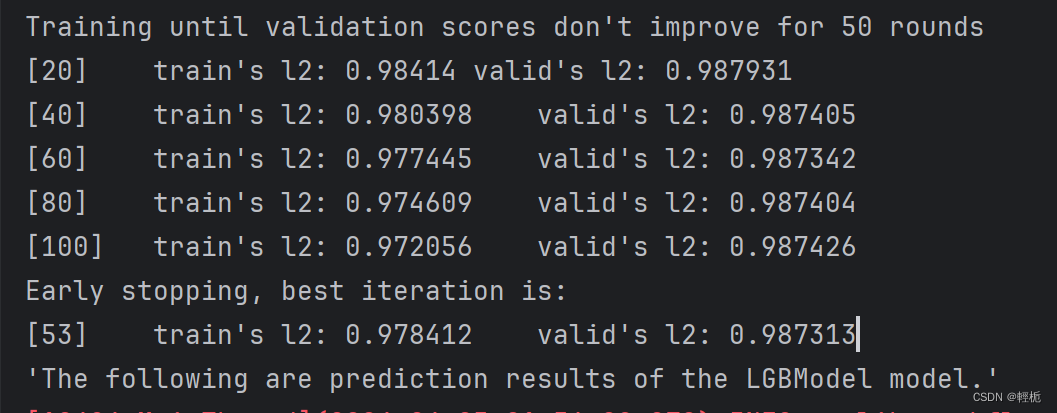
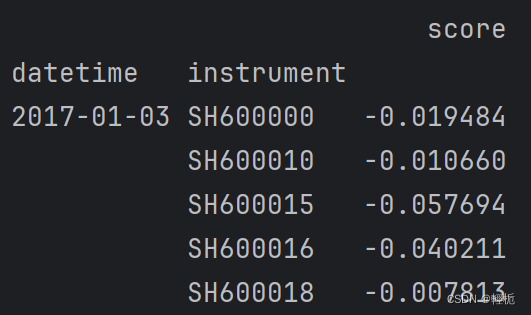
模型预测值结果:(这个就是我们后面仓位分析所需要的pred.pkl 文件)
调用qlib.workflow模块正式进行回测,获取上步模型训练值记录,并通过load_object读取:
# 使用之前训练使用的rid拿到recorder
recorder = R.get_recorder(recorder_id=rid, experiment_name="train_model")
# 拿到之前训练好的模型
model = recorder.load_object("trained_model")
使用SignalRecord,针对测试集数据,使用训练完的模型生成预测值:
# 生成预测结果:pred.pkl, label.pkl
recorder = R.get_recorder()
ba_rid = recorder.id # 记录当前Experiment生成的Recorder的id,方便之后使用
sr = SignalRecord(model, dataset, recorder)
sr.generate()
使用PortAnaRecord,对预测结果进行策略回测,如下图中使用了Qlib内置的TopKDropout策略,计算策略回测的绩效指标:
# 利用上边生成的结果生成回测结果与分析
par = PortAnaRecord(recorder, port_analysis_config, "day")
par.generate()回测结果及绩效指标如下,区分为扣不扣税费:
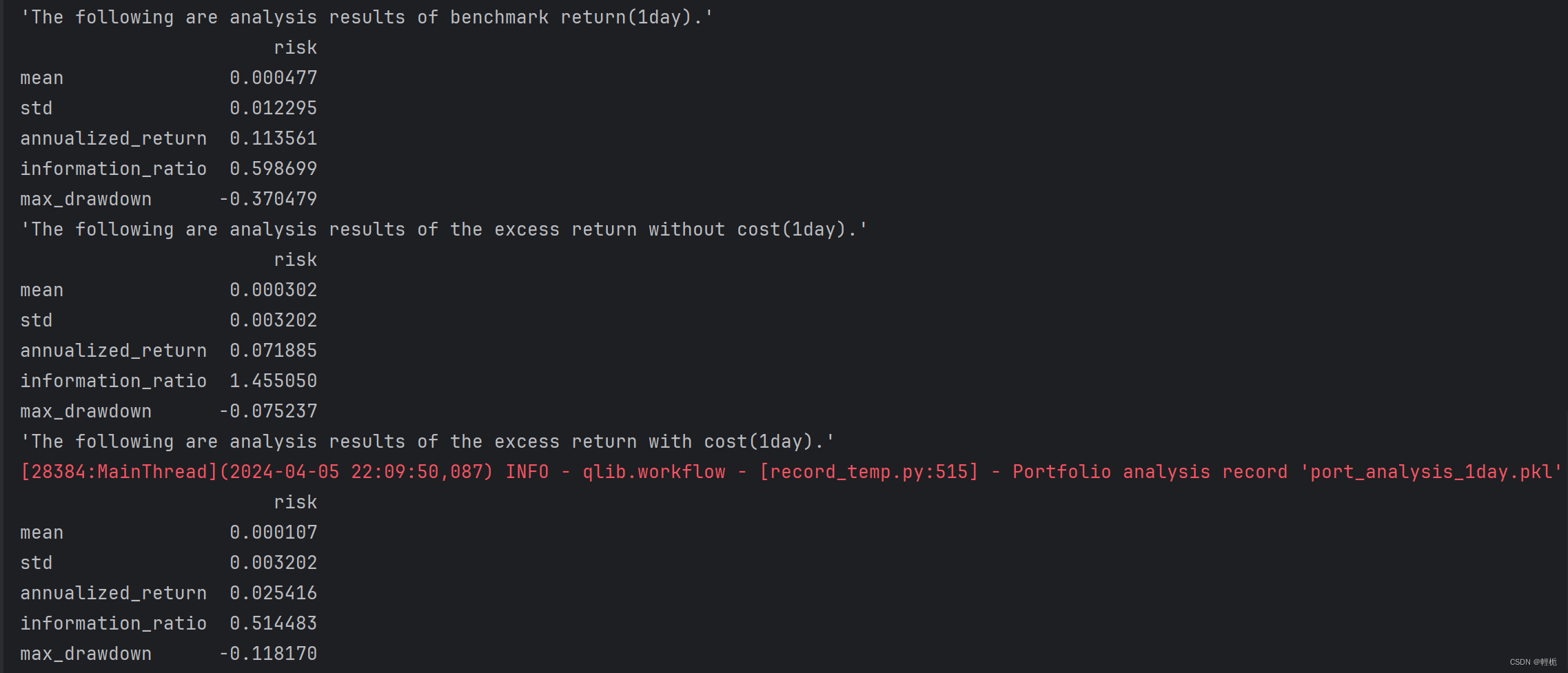
前面的回测结果都以pkl文件格式存储的,所以先加载相关回测结果文件:存储路径一般都在.qlib/examples/mlruns:
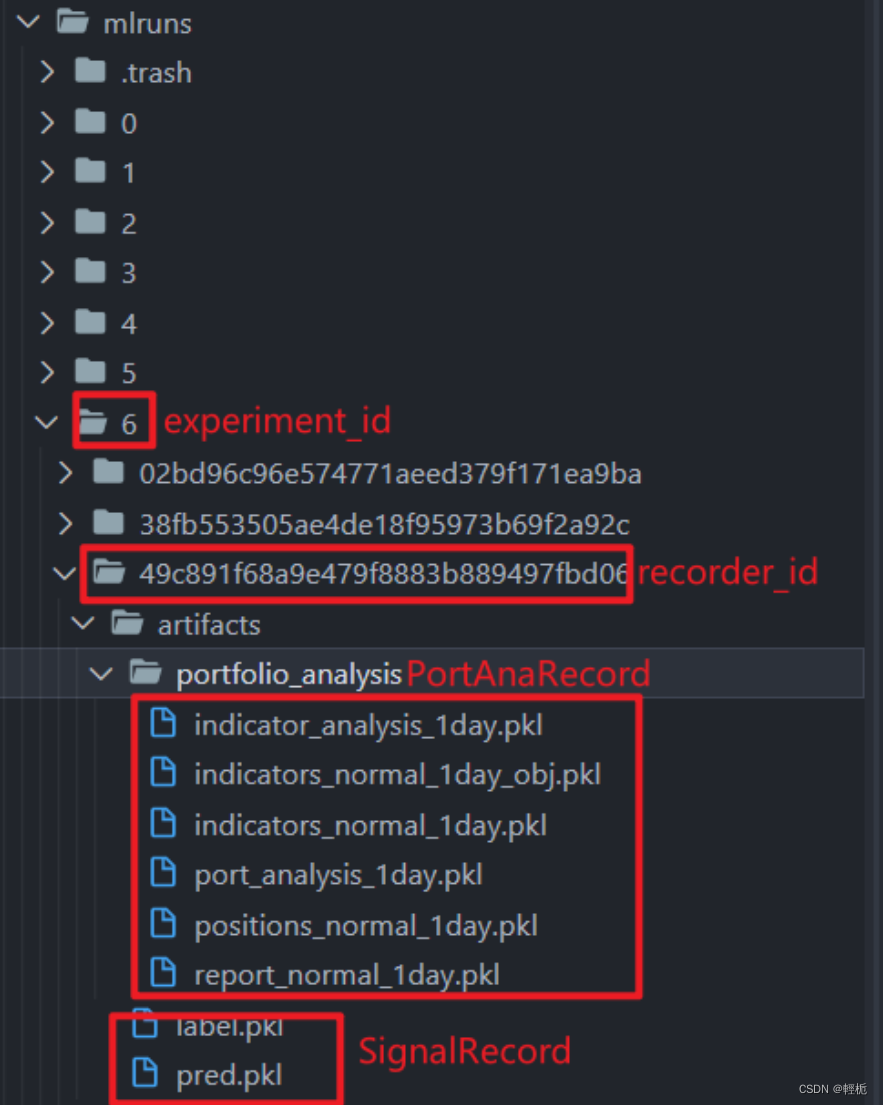
在完成加载后,我们就可以开始画图,Qlib中画图使用的是当红的数据可视化库Plotly,产生的图片都是可交互的,load上一步生成的.pkl文件为:
recorder = R.get_recorder(recorder_id=ba_rid, experiment_name="backtest_analysis")
pred_df = recorder.load_object("pred.pkl")
report_normal_df = recorder.load_object("portfolio_analysis/report_normal_1day.pkl")
positions = recorder.load_object("portfolio_analysis/positions_normal_1day.pkl")
analysis_df = recorder.load_object("portfolio_analysis/port_analysis_1day.pkl")
# AnalysisPosition持仓分析,分report和 risk analysis两部分。
print(report_normal_df.head())打印结果为:(看源码画图传参是个DataFrame)
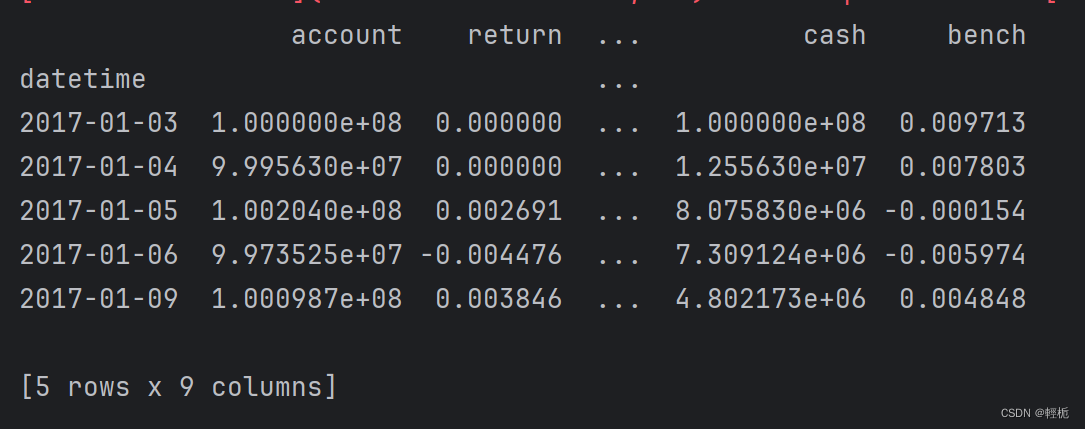
正常情况出图应该为:
报告收益率:
analysis_position.report_graph(report_normal_df) # Report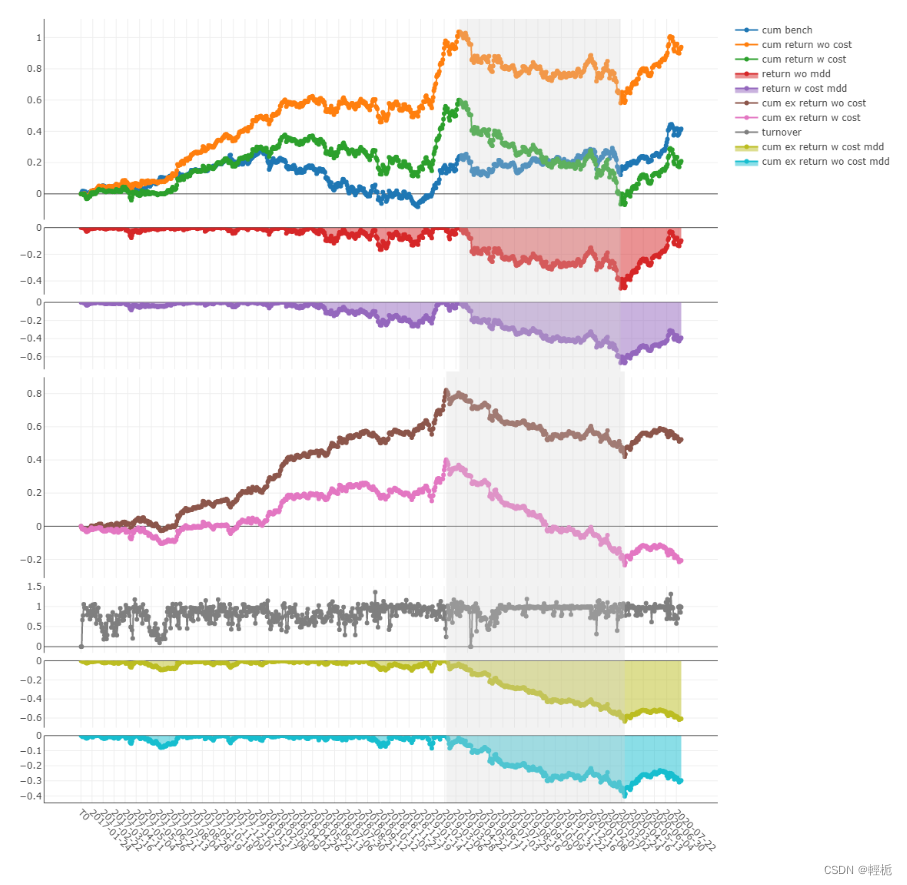
我这边显示不了,只能用matplotlib或者seaborn画图:(当然也可以选择其他列画图,画的效果很抽象就不做评价了),[qlib默认是向ipython notebook绘图的,如果当前不是ipython notebook环境,直接返回的是plotly.graph_objs._figure.Figure对象]
plot部分画图:
df = report_normal_df
plt.plot(df.index, df['account'], label='Account')
plt.plot(df.index, df['bench'], label='Benchmark')
plt.xlabel('Date')
plt.ylabel('Value')
plt.title('Account and Benchmark Return')
plt.legend()
plt.show()
# 绘制现金列的柱状图
plt.bar(df.index, df['cash'])
plt.xlabel('Date')
plt.ylabel('Cash')
plt.title('Cash')
plt.show()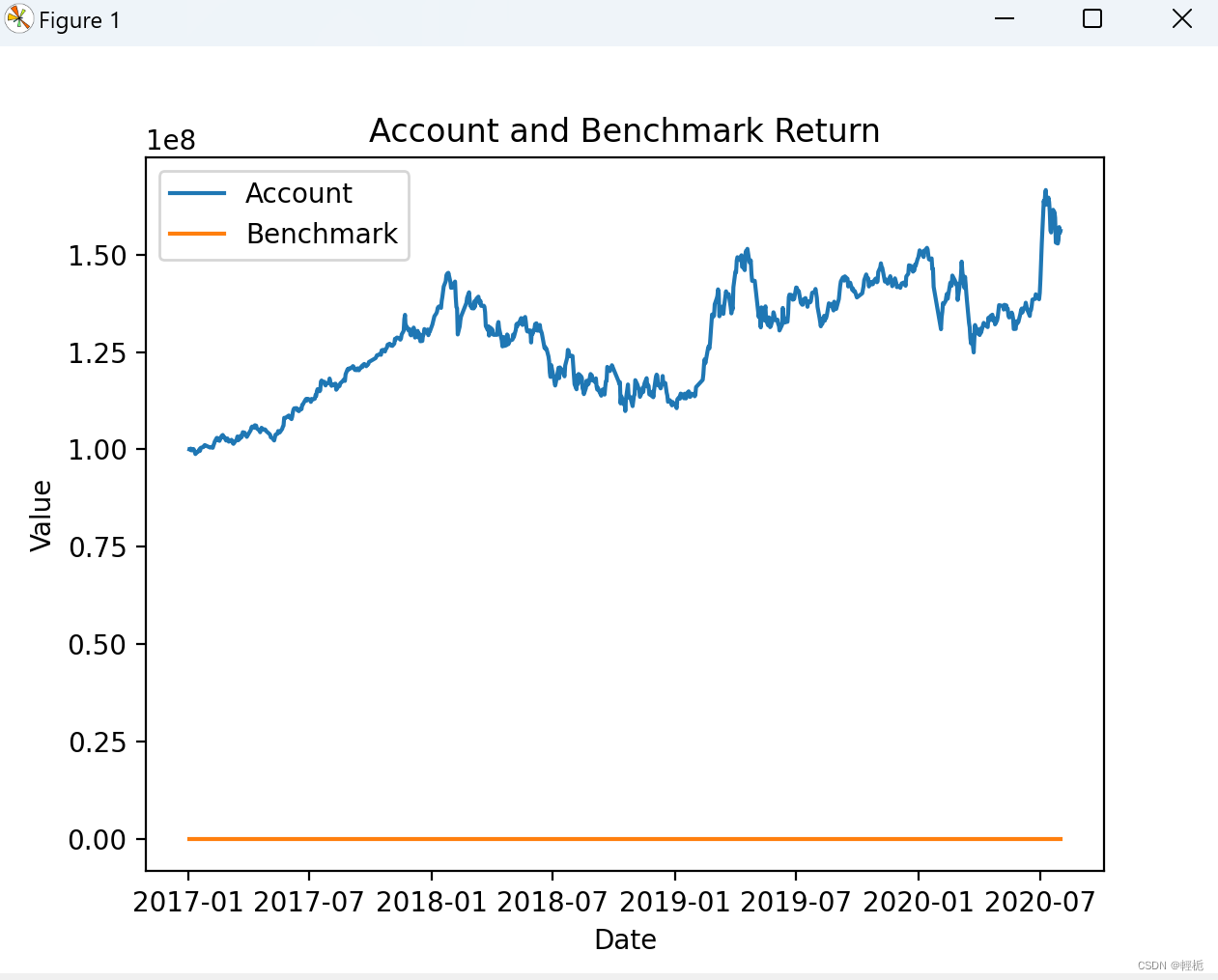
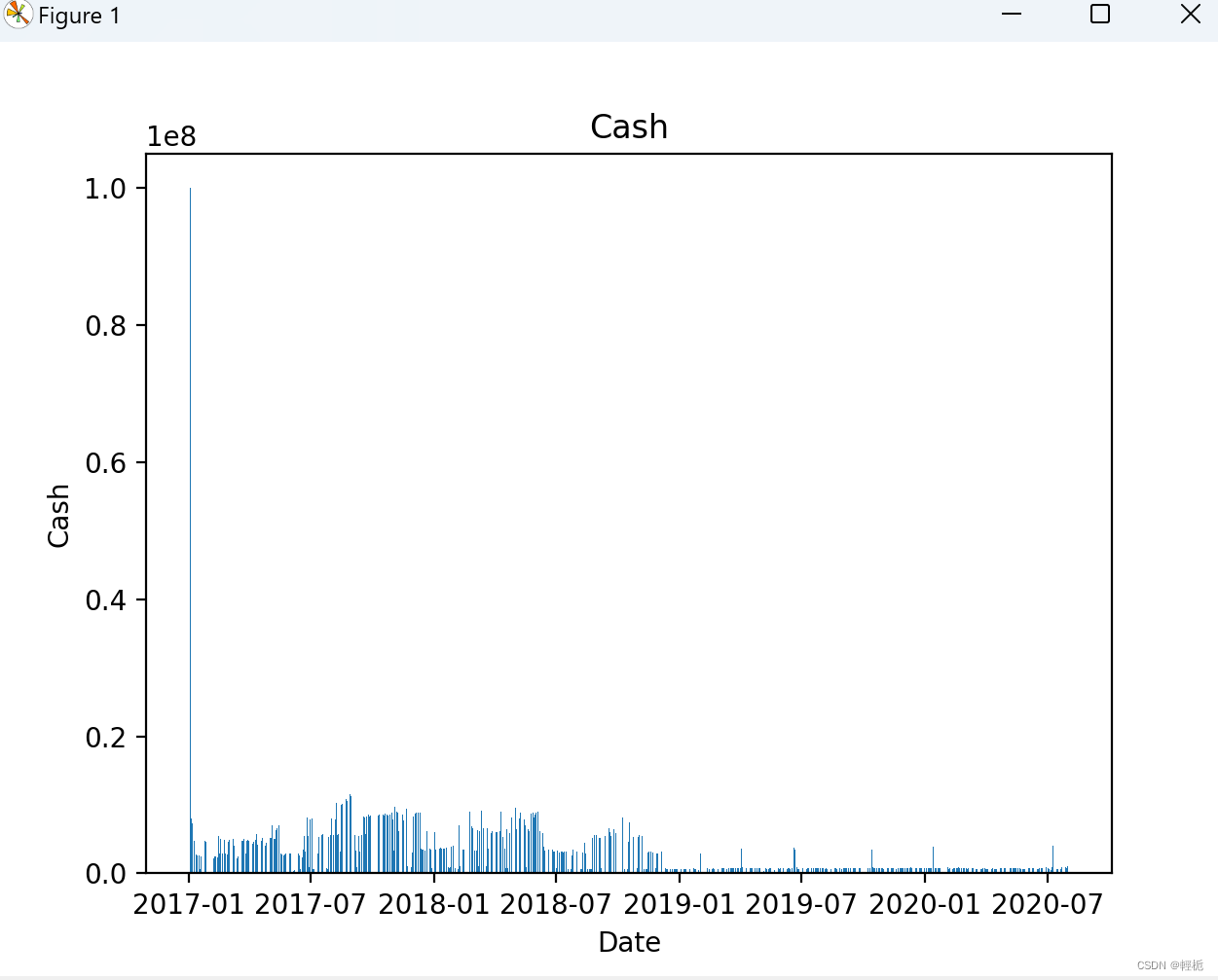
报告风险:
analysis_position.risk_analysis_graph(analysis_df, report_normal_df) # risk analysis
label_df = dataset.prepare("test", col_set="label")
label_df.columns = ["label"]
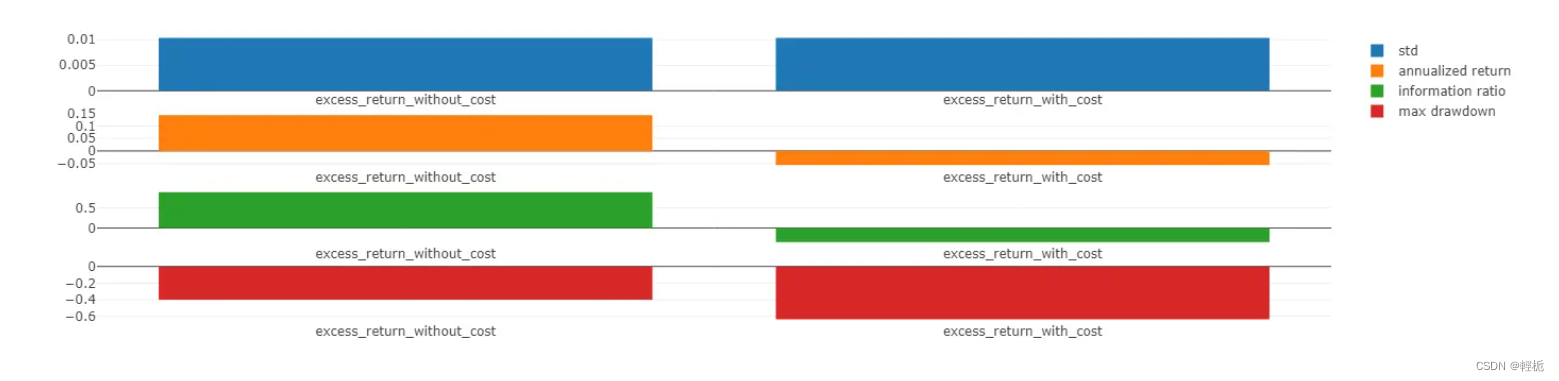
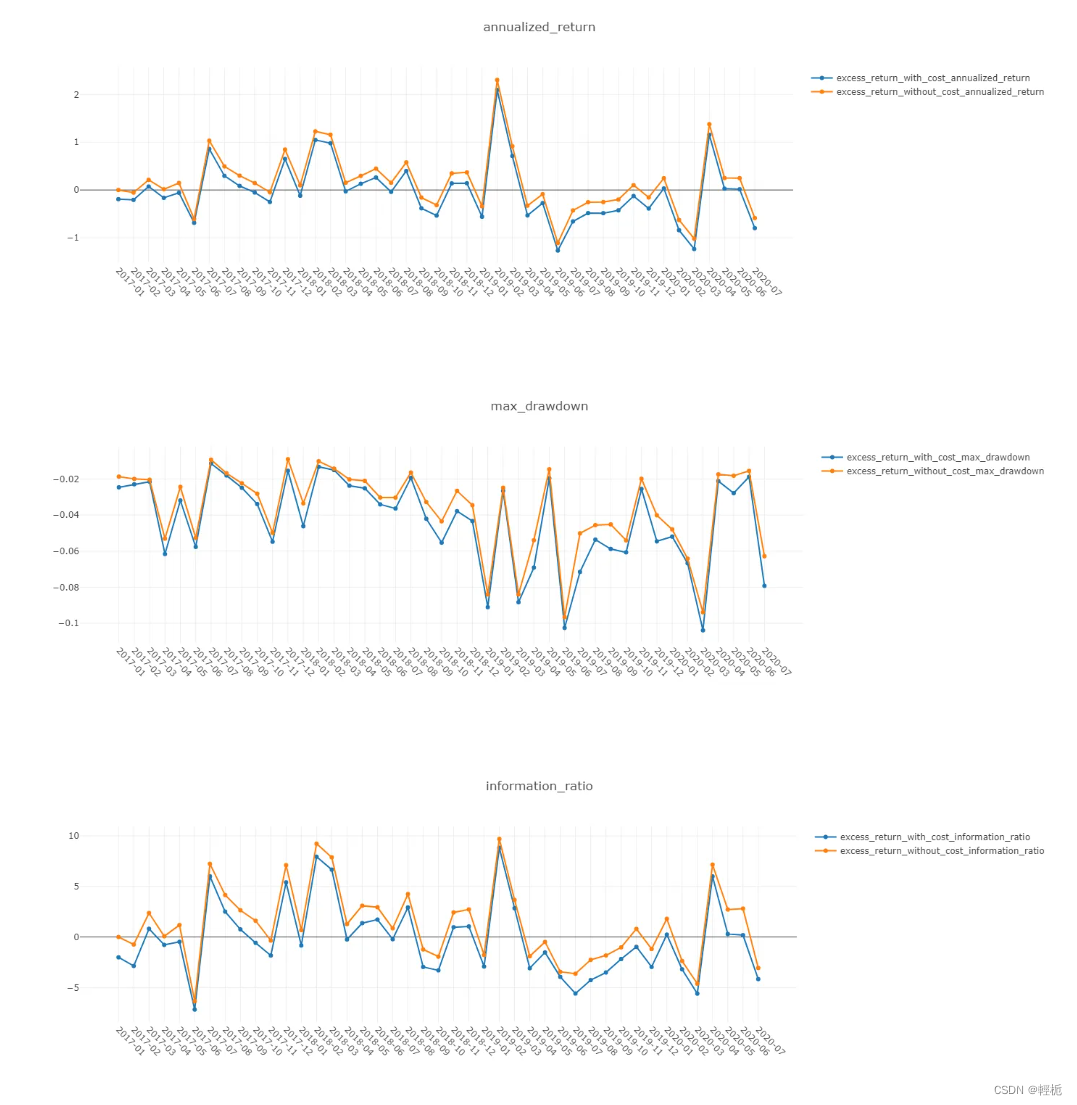
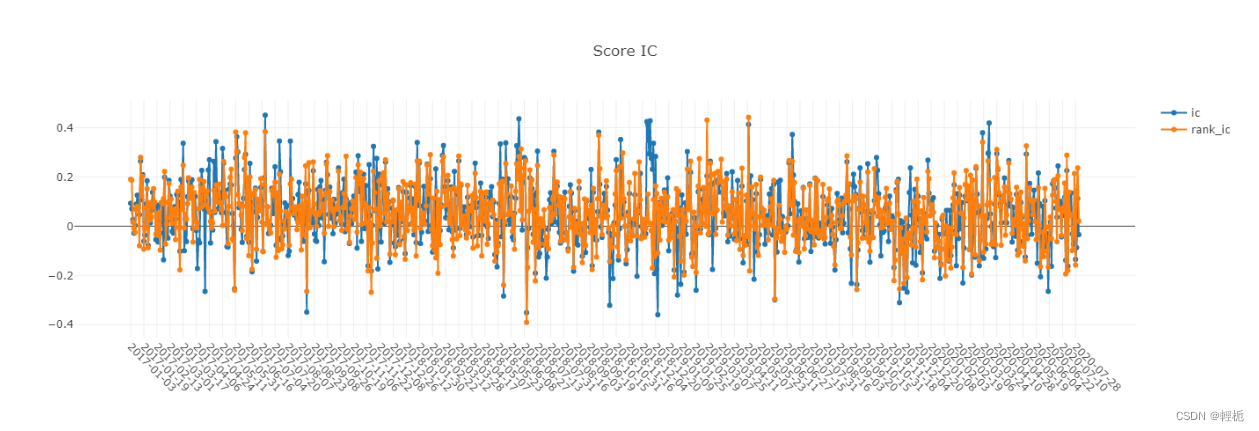
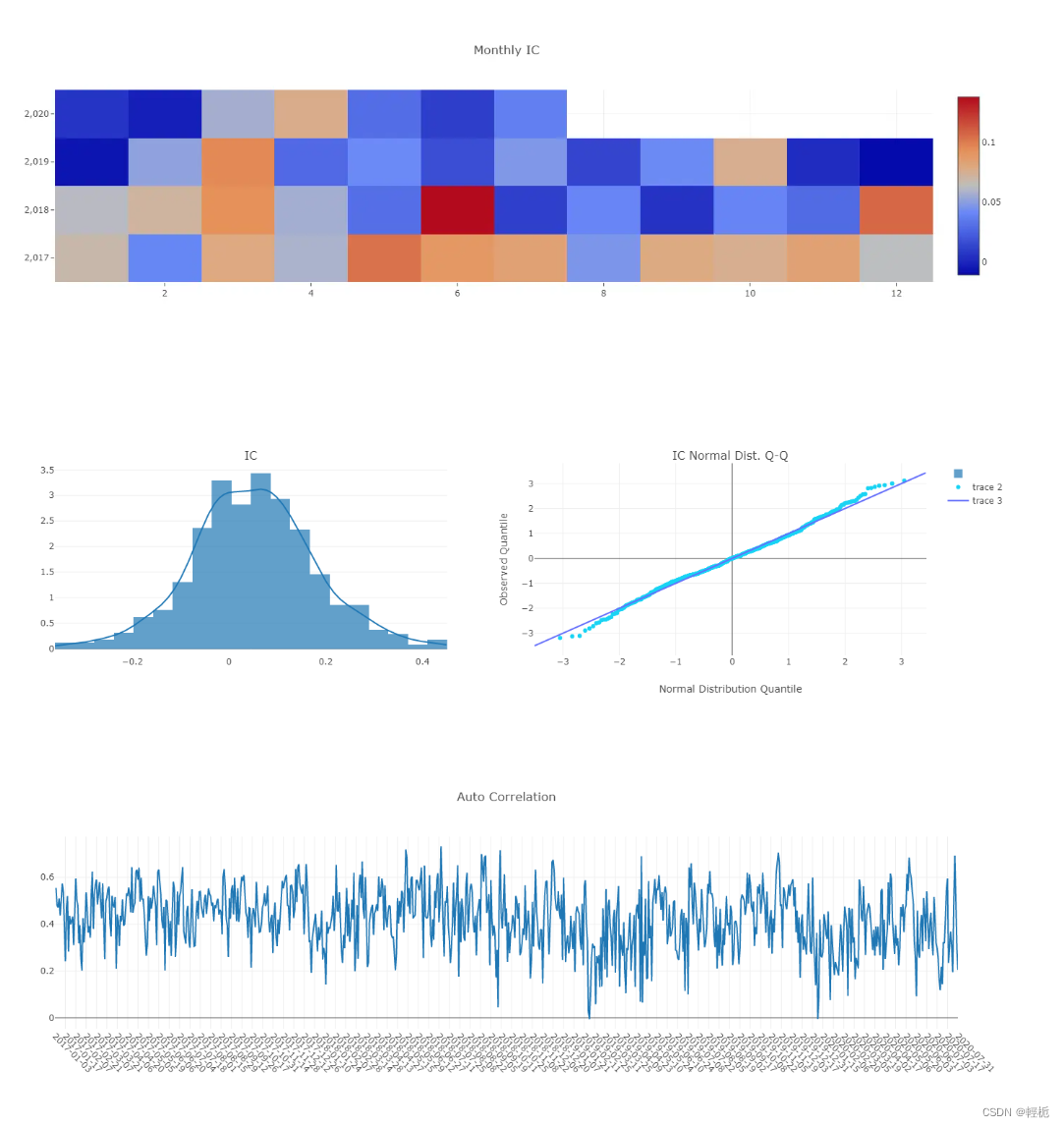
报告IC值:信息系数(Information Coefficient),因子值与下期收益率的截面相关系数,通过 IC 值可以判断因子值对下期收益率的预测能力。
# IC值: score IC
pred_label = pd.concat([label_df, pred_df], axis=1, sort=True).reindex(label_df.index)
analysis_position.score_ic_graph(pred_label)
报告模型性能表现:
# model performance
analysis_model.model_performance_graph(pred_label)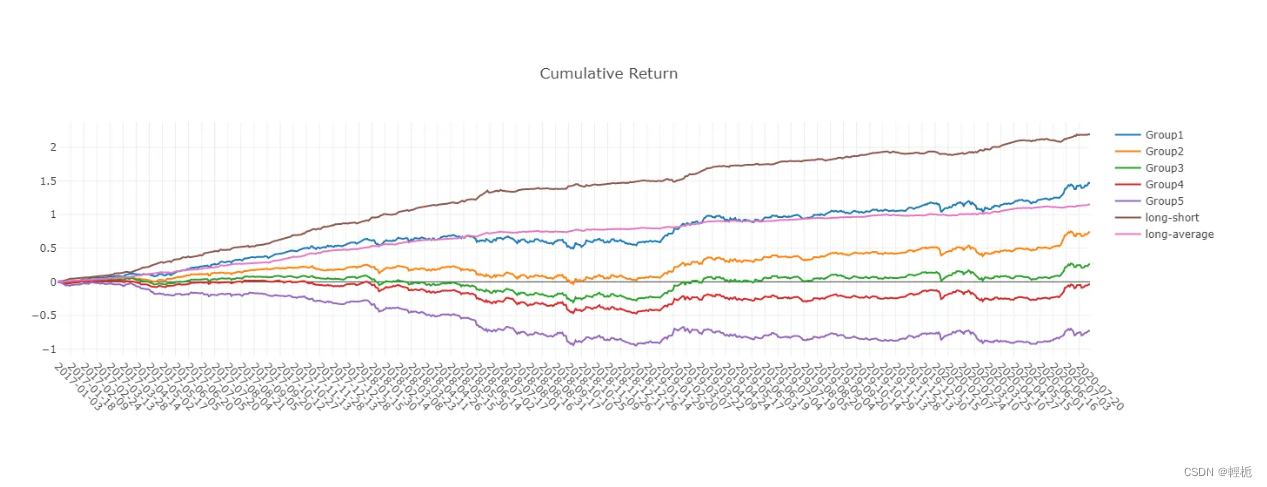
从数据库里面导入数据整理成qlib格式形式:
在terminal里面:
python scripts/dump_bin.py dump_all --csv_path ~/.qlib/qlib_data/my_data --qlib_dir ~/.qlib/qlib_data/my_data --symbol_field_name stock_code --date_field_name date --include_fields open,close,high,low,volume在py里面即可运行:
import qlib
from qlib.config import REG_CN
from qlib.data import D
import matplotlib.pyplot as plt
from multiprocessing import freeze_support
from qlib.data.dataset.loader import QlibDataLoader
qlib.init()
class QlibMgr:
def __init__(self):
provider_uri = "~/.qlib/qlib_data/my_data" # target_dir
qlib.init(provider_uri=provider_uri, region=REG_CN)
def load_df(self,features,fields,start_time,end_time):
df = D.features(features, fields, start_time=start_time,end_time=end_time, freq='day')
return df
if __name__ == '__main__':
freeze_support()
MACD_EXP = '(EMA($close, 12) - EMA($close, 26))/$close - EMA((EMA($close, 12) - EMA($close, 26))/$close, 9)/$close'
fields = [MACD_EXP,'$close'] # MACD
names = ['MACD','收盘价']
labels = ['Ref($close,0)/Ref($close,5)-1'] # label
label_names = ['LABEL']
data_loader_config = {"feature": (fields, names),"label": (labels, label_names)}
data_loader = QlibDataLoader(config = data_loader_config)
# df = data_loader.load(instruments='csi100', start_time='2020-01-01', end_time='2020-12-31')
# print(df)
fun = QlibMgr()
df = fun.load_df(features=['stocks_202404061413'], fields=['$close'], start_time='2016-01-01', end_time='2024-12-31')
se = df.loc['stocks_202404061413']['$close']
se.plot()
plt.show()
















 1418
1418

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









