







02.Python代码Pandas - Series全系列分享(使用.特点.说明.取值.函数)
提示:帮帮志会陆续更新非常多的IT技术知识,希望分享的内容对您有用。本章分享的是pandas的使用语法。前后每一小节的内容是存在的有:学习and理解的关联性,希望对您有用~
python语法-pandas第二节 :Series全系列分享(使用.特点.说明.取值.函数)
文章目录
Series使用语法
声明Series
Series是一个带有索引的一维数组。属于Pandas的其中一个数据结构。
pandas是什么?快速的pandas简介。帮助理解: pandas的简介
#声明一个pandas Series数组,存储数据 (数字)
s01 = pd.Series([10,20,30])
print(s01) #输出这个series 为:带有索引的一维数组
#声明了数组,我们目前还没有去使用,其实pandas有非常多的操作数据分析功能的
#通过Series变量 s01.功能 来使用

第一列是索引(如:0) 第二列是数据(如:10)
取值
直接通过索引取值即可(索引是:前面案例代码)
s01 = pd.Series([10,20,30])
print(s01)
print(s01[0]) #取出10
其他情况声明
字符串数据和指定索引:
#定义一个字符串数据
str = ['bangbangzhi','hello','python-pandas']
#声明一个pandas Series数组,存储数据 (字符串)
#s02 = pd.Series(str) #和上一个案例一模一样 ,默认索引从0开始
#声明一个pandas Series数组,存储字符串 并指定索引
s02 = pd.Series(str,index=['x','y','z'])
print(s02)
#取值按索引取值
#s02['x']

字典数据和指定范围:
#字典数据,key自动定为索引
# key就自己声明的了,可以是数字,可以是字符串,可以是..
d01 = {'a':'hello','b':'bangbangzhi','c':'python'}
s03 = pd.Series(d01)
print(s03)
print("---------隔开一下--------")
d02 = {1:'hello',2:'bangbangzhi',3:'python',4:'four'}
#只取一部分数据
s03 = pd.Series(d02,index=[1,3]) #故意写的3,没有2
print(s03)
#取值是索引

完整语法
pandas.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)
data:Series 的数据部分,可以是列表、数组、字典等。
index:Series 的索引部分,用于对数据进行标记。可以是列表、数组、索引对象等。如果不提供此参数,则创建一个默认的整数索引,从0开始。
dtype:指定 Series 的数据类型。可以是 NumPy 的数据类型,例如 np.int64、np.float64 等。如果不提供此参数,则根据数据自动推断数据类型。
name:Series 的名称,用于标识 Series 对象。如果提供了此参数,则创建的 Series 对象将具有指定的名称。
copy:是否复制数据。默认为 False,表示不复制数据。如果设置为 True,则复制输入的数据。常用有时数据分析可能会更改原始值,看情况是否允许,改了就改了
fastpath:是否启用快速路径。默认为 False。启用快速路径可能会在某些情况下提高性能。
Series的特点
一维数组:Series 中的每个元素都有一个对应的索引值。
索引: 每个数据元素都可以通过标签(索引)来访问,默认情况下索引是从 0 开始的整数,但你也可以自定义索引。
数据类型: Series 可以容纳不同数据类型的元素,包括整数、浮点数、字符串、Python 对象等。
大小不变性:Series 的大小在创建后是不变的,但可以通过某些操作(如 append 或 delete)来改变。
操作:Series 支持各种操作,如数学运算、统计分析、字符串处理等。
缺失数据:Series 可以包含缺失数据,Pandas 使用NaN(Not a Number)来表示缺失或无值。
自动对齐:当对多个 Series 进行运算时,Pandas 会自动根据索引对齐数据,这使得数据处理更加高效。
Series说明
Series 中的数据是有序的。
可以将 Series 视为带有索引的一维数组。
索引可以是唯一的,但不是必须的。
数据可以是标量、列表、NumPy 数组等。
可以使用运算符,包括基本运算符±*/ 和 比较运算符 > < >= <=
s04 = pd.Series([10,20,30])
result = s04 * 2 #每个数据 * 2
print(result)
print("------隔开----")
filter_r = result[result>50]#过滤 条件
print(filter_r)#得到新的Series ,看输出的数据格式,还是Series

Series各种 功能 函数
index 获取 Series 的索引
values 获取 Series 的数据部分(返回 NumPy 数组)
head(n) 返回 Series 的前 n 行(默认为 5)
tail(n) 返回 Series 的后 n 行(默认为 5)
dtype 返回 Series 中数据的类型
shape 返回 Series 的形状(行数)
describe() 返回 Series 的统计描述(如均值、标准差、最小值等)
isnull() 返回一个布尔 Series,表示每个元素是否为 NaN
notnull() 返回一个布尔 Series,表示每个元素是否不是 NaN
unique() 返回 Series 中的唯一值(去重)
value_counts() 返回 Series 中每个唯一值的出现次数
map(func) 将指定函数应用于 Series 中的每个元素
apply(func) 将指定函数应用于 Series 中的每个元素,常用于自定义操作
astype(dtype) 将 Series 转换为指定的类型
sort_values() 对 Series 中的元素进行排序(按值排序)
sort_index() 对 Series 的索引进行排序
dropna() 删除 Series 中的缺失值(NaN)
fillna(value) 填充 Series 中的缺失值(NaN)
replace(to_replace, value) 替换 Series 中指定的值
cumsum() 返回 Series 的累计求和
cumprod() 返回 Series 的累计乘积
shift(periods) 将 Series 中的元素按指定的步数进行位移
rank() 返回 Series 中元素的排名
corr(other) 计算 Series 与另一个 Series 的相关性(皮尔逊相关系数)
cov(other) 计算 Series 与另一个 Series 的协方差
to_list() 将 Series 转换为 Python 列表
to_frame() 将 Series 转换为 DataFrame
iloc[] 通过位置索引来选择数据
loc[] 通过标签索引来选择数据
Series各种 统计 函数
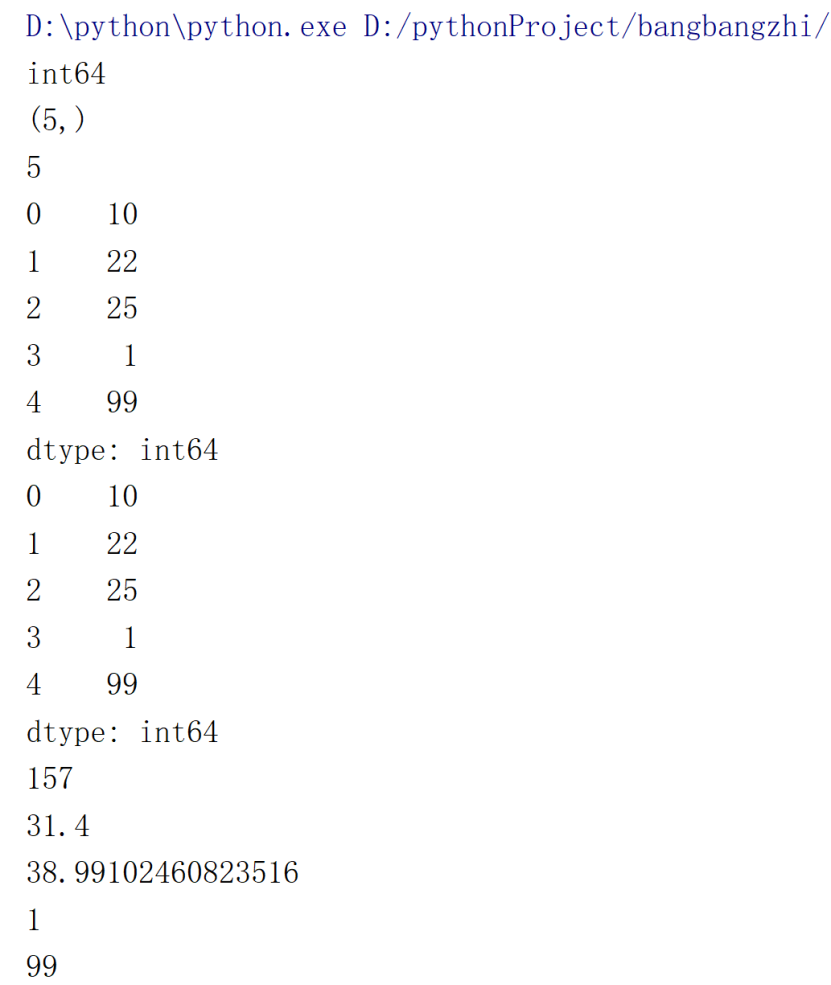
s06 = pd.Series([10, 22, 25, 1, 99])
print(s06.dtype) # 数据类型
print(s06.shape) # 形状
print(s06.size) # 元素个数
print(s06.head()) # 前几个元素,默认是前 5 个
print(s06.tail()) # 后几个元素,默认是后 5 个
print(s06.sum()) # 求和
print(s06.mean()) # 平均值
print(s06.std()) # 标准差
print(s06.min()) # 最小值
print(s06.max()) # 最大值
(会陆续更新非常多的IT技术知识及泛IT的电商知识,可以点个关注,共同交流。比心)

















 1839
1839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









