




 文章讲述了在系统高负载情况下,MySQL数据库出现longsemaphorewait错误,导致实例挂起。通过分析发现,这可能是由于并发访问过多、锁竞争激烈造成的。解决方法包括优化SQL语句、关闭自适应哈希索引。
文章讲述了在系统高负载情况下,MySQL数据库出现longsemaphorewait错误,导致实例挂起。通过分析发现,这可能是由于并发访问过多、锁竞争激烈造成的。解决方法包括优化SQL语句、关闭自适应哈希索引。
背景介绍
- 数据库症状:系统高负载情况下错误日志中出现long semaphore wait信息,数据库实例本身hang住,无法提供正常的访问服务,可登录,但登录后任何操作没有反应。
- 数据库版本:8.0.20
- 操作系统版本:CentOS 7.6
- 主机信息:32GB内存,CPU 16cores
- 数据库架构:单实例MySQL
处理方式
鉴于业务端无法正常使用DB,故只能通过操作系统层面执行命令 kill -9的方式临时杀进程重启MySQL实例,以最短的时间恢复DB正常使用。
问题分析
首先通过MySQL错误日志中的内容进行原因查找,错误日截图如下:(由于当时获取信息不便,临时采用截图的方式保留故障信息)
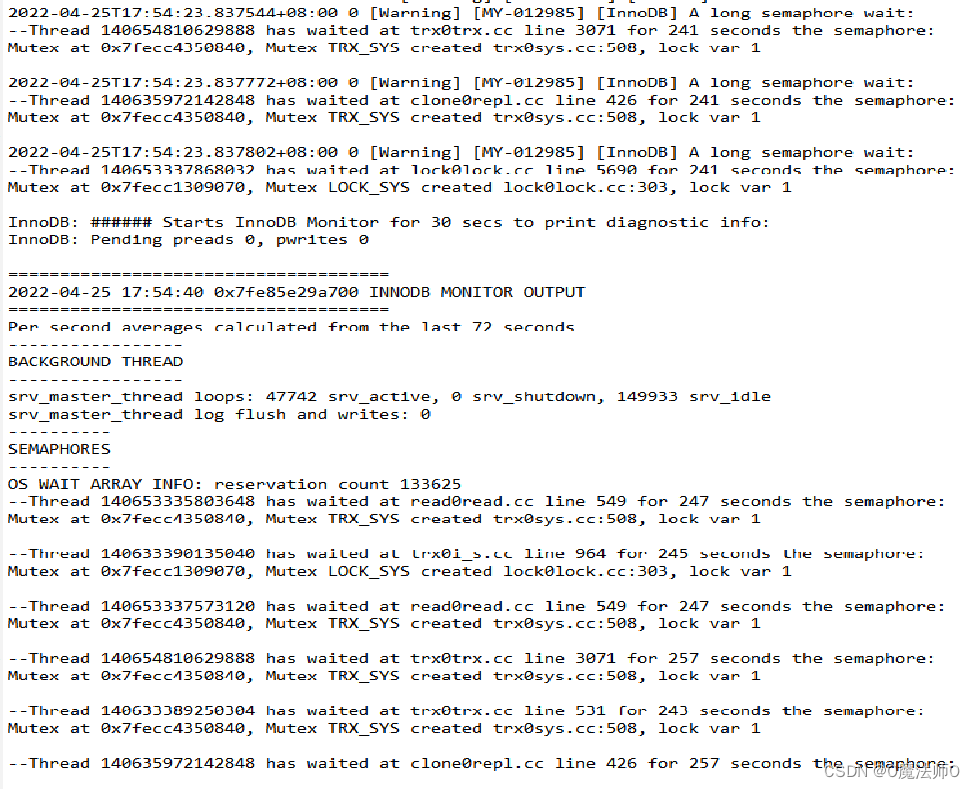
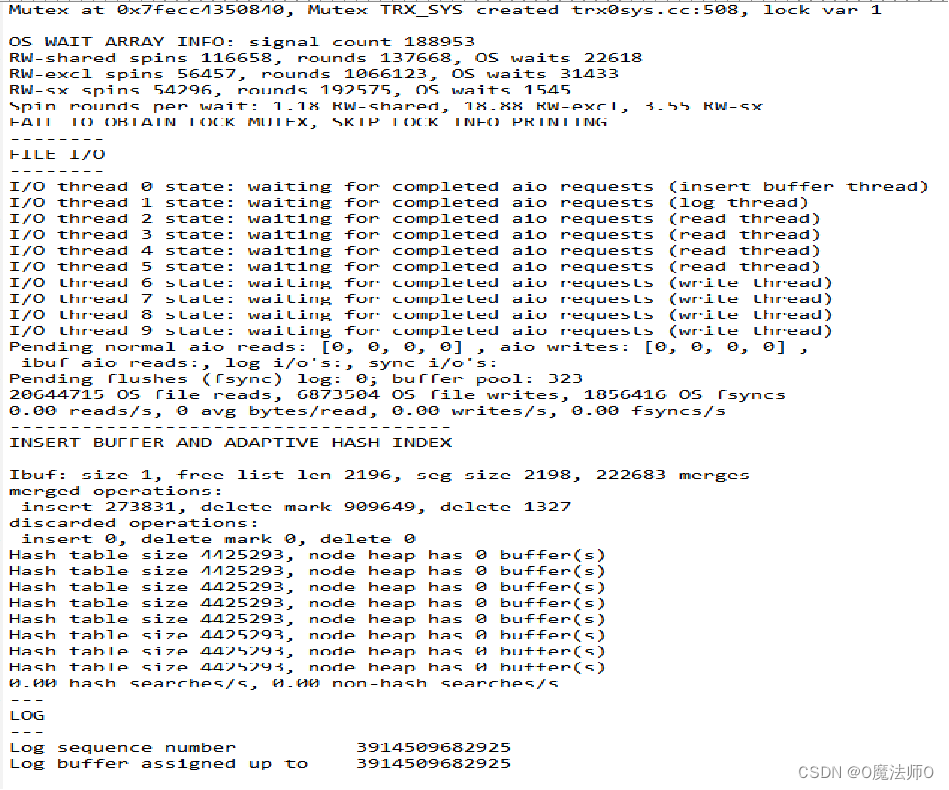
概念:
long semaphore waits 是什么? --信号量,控制资源的并发访问 这里是信号量的等待,Semaphore就像可以容纳N人的房间,如果人不满就可以进去,如果人满了,就要等待有人出来。
背景
Innodb使用了mutex和rw_lock来保护内存数据结构,同步的机制要么是互斥,要么是读写阻塞的模式。
Innodb认为mutex和rw_lock hold的时间足够短,所以,如果有线程wait mutex或者rw_lock时间过长,那么很可能是程序有bug,所以就会异常主动
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 520
520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









