







文章目录
1、原题
1.1、英文原题
InnoDB: Warning: a long semaphore wait:
The relevant parts of the InnoDB monitor output shows:
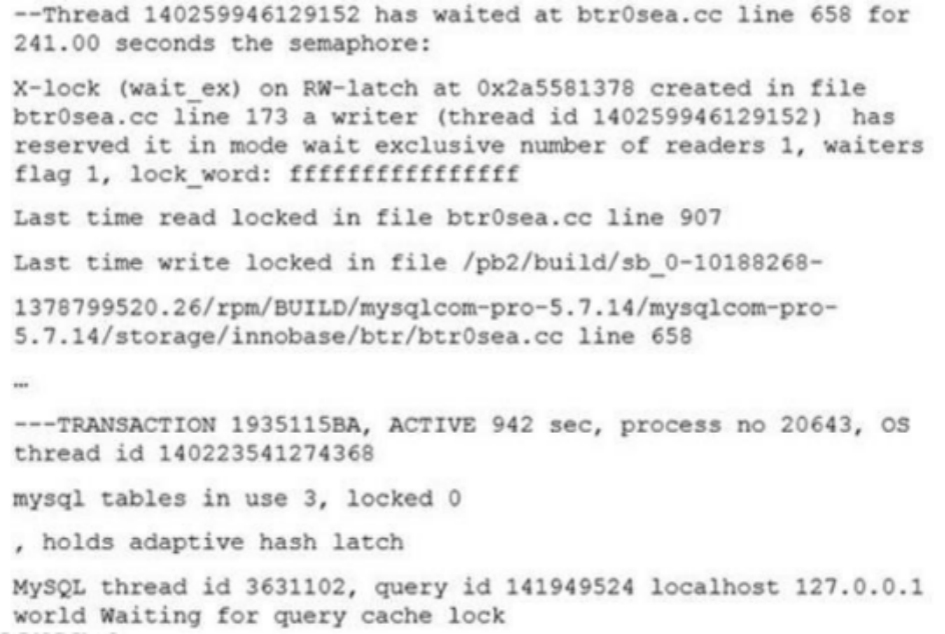
Which two options would help avoid the long wait in the future?
A、Increase the value of the innodb_lock_wait_timeout option.
B、Increase the value of the innodb_read_io_threads option.
C、Change the table to use HASH indexes instead of BTREE indexes.
D、Set the value of innodb_adaptive_hash_index to zero.
E、Deactivate the query cache.
F、Increase the size of the InnoDB buffer pool.
1.2、答案
D、E
2、题目解析
2.1、题干解析
本题考察的是InnoDB各种与性能有关的配置。
2.2、选项解析
- 锁等待时间是个最长的阀值,所以如果有等待时间很长的情况,并不是这个锁等待阀值导致的,而是实际等待行锁就需要这么长时间,所以修改这个阀值是没有意义的,跟query cache也没有关系,所以选项A错误。
- 从描述可以看出这里是有query cache锁,增加IO线程数量没有意义,所以选项B错误。
- 哈希索引是自适应的,没法指定使用,所以选项C错误。
- 选项D不知道为啥正确,有懂的小伙伴可以分享下。
- 从描述可以看出这里是有query cache锁,禁用query cache会有效果。所以选项E正确。
- 选项F不知道为啥错误,有懂的小伙伴可以分享下。
3、知识点
3.1、知识点1:innodb_lock_wait_timeout系统变量
- innodb_lock_wait_timeout系统变量表示InnoDB事务在放弃之前等待行锁的时间长度(秒)。默认值是50秒。对于及时性要求高的应用程序或OLTP系统,可以降低这个值。当锁等待超时发生时,当前语句被回滚(而不是整个事务)。
- innodb_lock_wait_timeout只适用于InnoDB行锁,不适用表锁的等待。
- 当innodb_deadlock_detect被启用(默认)时,锁等待超时值不适用于死锁,因为InnoDB会立即检测到死锁并回滚其中一个死锁事务。当innodb_deadlock_detect被禁用时,InnoDB依靠innodb_lock_wait_timeout在死锁发生时进行事务回滚。
- innodb_lock_wait_timeout可以在运行时通过SET GLOBAL或SET SESSION语句来设置。改变GLOBAL设置需要足够的权限来设置全局系统变量,并影响到随后连接的所有客户端的操作。任何客户端都可以改变innodb_lock_wait_timeout的SESSION设置,这只影响到该客户端。
3.2、知识点2:innodb_read_io_threads系统变量
innodb_read_io_threads系统变量代表InnoDB中读取操作的I/O线程数量。InnoDB使用后台线程来服务各种类型的I/O请求。你可以使用innodb_read_io_threads和innodb_write_io_threads配置参数来配置服务于数据页的读和写I/O的后台线程的数量。这些参数分别标志着用于读和写请求的后台线程的数量。它们在所有支持的平台上都有效。你可以在MySQL选项文件(my.cnf或my.ini)中为这些参数设置值;你不能动态地改变值。这些参数的默认值是4,允许的值范围是1-64。
3.3、知识点3:自适应哈希索引
3.3.1、什么是自适应哈希索引
Innodb存储引擎会监控对表上二级索引的查找,如果发现某二级索引被频繁访问,二级索引成为热数据,建立哈希索引可以带来速度的提升。经常访问的二级索引数据会自动被生成到hash索引里面去(最近连续被访问三次的数据),自适应哈希索引通过缓冲池的B+树构造而来,因此建立的速度很快。
自适应哈希索引由innodb_adaptive_hash_index变量启用,或者在服务器启动时由–skip-innodb-adaptive-hash-index关闭。
自适应哈希索引的优点:
1、无序,没有树高,访问速度更快
2、降低对二级索引树的频繁访问资源
3、自适应
自适应哈希索引的缺点:
1、hash自适应索引会占用innodb buffer pool;
2、自适应hash索引只适合搜索等值的查询,如select * from table where index_col=‘xxx’,而对于其他查找类型,如范围查找,是不能使用的;
3.3.2、自适应哈希索引和B树索引的比较
B树索引的特点:
- 在使用=, >, >=, <, <=, 或BETWEEN操作符的表达式中,B树索引可用于列比较。如果LIKE的参数是一个不以通配符开始的常量字符串,那么索引也可以用于LIKE比较。
哈希索引的特点
1/ 它们只用于使用=或<=>运算符的平等比较(但速度非常快)。它们不用于查找数值范围的比较运算符,如<。依靠这种类型的单值查找的系统被称为 “键值存储”;要将MySQL用于这种应用,应尽可能使用哈希索引。
2. 优化器不能使用哈希索引来加速ORDER BY操作。(这种类型的索引不能用于搜索顺序的下一个条目)。
3. 只有整个键可以被用来搜索一条记录。(对于B树索引,键的任何最左边的前缀都可以用来寻找行)。
3.3.3、innodb_adaptive_hash_index系统变量
innodb_adaptive_hash_index系统变量表示InnoDB的自适应哈希索引是否被启用或禁用。这个变量在默认情况下是启用的。你可以使用SET GLOBAL语句修改这个参数,而不需要重新启动服务器。在运行时改变设置需要足够的权限来设置全局系统变量。
禁用自适应哈希索引会立即清空哈希表。当哈希表被清空时,正常的操作可以继续进行,而执行使用哈希表的查询则直接访问索引B树。
4、总结
- innodb_lock_wait_timeout系统变量表示InnoDB事务在放弃之前等待行锁的时间长度(秒)。该变量只适用于InnoDB行锁,不适用于表锁。对于及时性要求高的应用程序或OLTP系统,可以降低这个值。当锁等待超时发生时,当前语句被回滚(而不是整个事务)。
- innodb_read_io_threads系统变量代表InnoDB中读取操作的I/O线程数量。InnoDB使用后台线程来服务各种类型的I/O请求。
- InnoDB自适应哈希索引:Innodb存储引擎会监控对表上二级索引的查找,如果发现某二级索引被频繁访问,二级索引成为热数据,建立哈希索引可以带来速度的提升。但哈希索引只能用于只适用于使用=或<=>运算符的平等比较,不适用于查找数值范围的比较运算符。哈希索引不能用来加速排序擦欧洲哦,也只能用整个键可以被用来搜索一条记录。(对于B树索引,键的任何最左边的前缀都可以用来寻找行)。所以哈希索引的局限性很明显,但是哈希索引会占用innodb buffer pool,所以要慎用。















 520
520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









