






1、MySQL调优参数有哪些
【双一参数重点说明下】
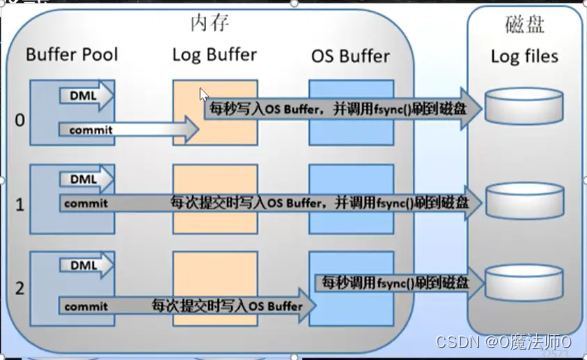
innodb_flush_log_at_trx_commit
0: 每次事务提交写入log buffer,每秒写入OS Buffer,并调fsync()刷盘
1: 每次事务提交log buffer --> os buffer -fsync()-> disk
2: 每次事务提交直接写入os buffer(跳过log buffer,由操作系统每秒调fsync()刷盘)
sync_binlog
0: 每次事务提交binlog_cache --> os buffer(由操作系统每秒进行刷盘)
1: 每次事务提交log buffer --> disk
N: N组事务提交后将数据更新到磁盘
连接层:
①max_connections=1000
②wait_timeout=600
③interactive_timeout=3600
server层:
①slow_query_log long_query_time
②sort_buffer join_buffer tmp_table
③max_execution_timeout
④sync_binlog=1
⑤binlog_format=row
innodb层:
①innodb_io_capacity :每秒刷脏页的数量
innodb_max_dirty_pages_pct 达到缓存区百分比 就触发刷盘
②innodb_buffer_pool_size:内存的50%~75%
innodb_log_buffer_size:1~2G redo日志文件是log_buffer的1-2倍大小
③transaction_isolation 隔离级别 RC
④innodb_flush_log_at_trx_commit
⑤行锁 innodb_lock_wait_timeout=10
2、MySQL有哪些锁?
按锁的资源层次分:
全局锁:Flush tables with read lock(FTWRL),典型使用场景是全库逻辑备份。
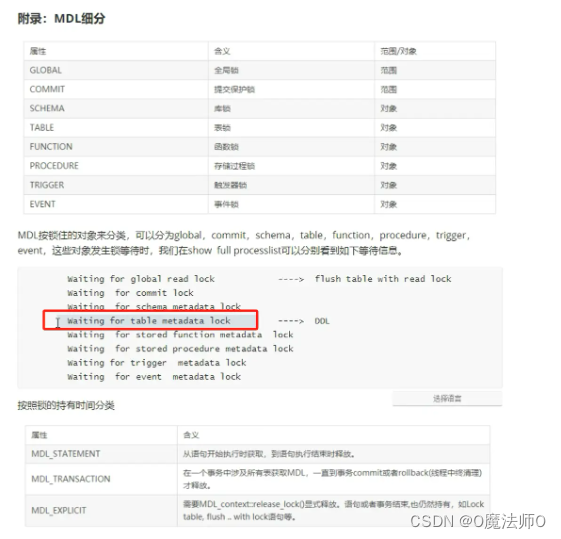
表锁:一种是表锁,一种是元数据锁。
1) MDL锁 S锁 X锁 IS锁 IX锁 AUTO_INC锁
2)元数据锁(metadata lock,MDL锁),MySQL使用MDL锁来管理对数据库对象的并发访问,并保证数据的一致性。
行锁:在索引上加的,有record、gap、next key lock
按锁的功能分:共享锁,排他锁,意向共享锁,意向排他锁
3、锁等待的监控数据如何获取?
0)show engine innodb status;
1)show processlist; 拿到前台的连接线程号,及等待什么锁
2)select * from performance_schema.threads where processlist_id=22; 查看对应的后台线程信息
3)select * from performance_schema.events_statements_history
(events_statements_current) where thread_id=51;
4)performance_schema.metadata_locks
5)SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS; 查看正在锁的事务
6)SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS; 查看等待锁的事务
- information_schema.innodb_trx–当前运行的所有事务
- information_schema.innodb_locks–当前出现的锁
- information_schema.innodb_lock_waits–锁等待的对应关系
4、MySQL可以做调优的磁盘IO参数有哪些?
innodb_read_io_threads
innodb_write_io_threads
innodb_io_capacity
5、存储引擎innodb和myisam的区别?
以下特性innodb都具备,myisam都没有:
InnoDB支持MVCC
InnoDB支持聚簇索引
InnoDB支持事务
InnoDB支持行级锁
InnoDB支持外键约束
InnoDB使用缓冲区来缓存数据和索引,MyISAM使用操作系统的缓存来处理数据。
InnoDB支持自适应hash索引:AHI
InnoDB有通过redo实现的崩溃恢复机制,MyISAM没有内置的崩溃恢复机制。
InnoDB支持双写机制:DWB double write buffer(2个DWB文件,2M数据)
6、MySQL有哪些同步模式?之间的区别?
1)异步模式
2)半同步模式:采用 after commit have_dynamic_loading
3)增强半同步:采用 after sync
7、MySQL如何实现的可重复读?
InnoDB为每个事务构造了一个数组,用来保存这个事务启动瞬间,当前正在“活跃”的所有事务ID。“活跃”指的就是,启动了但还没提交。
数组里面事务ID的最小值记为低水位,当前系统里面已经创建过的事务ID的最大值加1记为高水位。
这个视图数组和高水位,就组成了当前事务的一致性视图(read-view)。
而数据版本的可见性规则,就是基于数据的row trx_id和这个一致性视图的对比结果得到的。
对于当前事务的启动瞬间来说,一个数据版本的row trx_id,如果低于低水位,这个数据是可见的;如果高于高水位,这个数据是不可见的;若在低水位和高水位之间,如果trx_id在数组中,则不可见,如果不在数组中,则可见。
在可重复读隔离级别下,只需要在事务开始的时候创建一致性视图,之后事务里的其他查询都共用这个一致性视图;
在读提交隔离级别下,每一个语句执行前都会重新算出一个新的视图。
8、介绍下并行复制的策略?
MySQL提供了多种并行复制策略:
1)MySQL 5.6 基于库级别的并行复制策略;
2)MySQL 5.7 基于组提交的并行复制策略;
3)MySQL 5.7.22 基于WRITESET的并行复制策略。
由于并行复制策略这块内容较多,这里只是简单提示下三种策略,面试时回答的越详细越好,最好把每一种策略如何实现的回答出来。
比如WRITESET复制策略,表示的是对于事务涉及更新的每一行,计算出这一行的hash值,组成集合writeset。如果两个事务没有操作相同的行,也就是说它们的writeset没有交集,就可以并行。
当然为了唯一标识,这个hash值是通过“库名+表名+索引名+值”计算出来的。如果一个表上除了有主键索引外,还有其他唯一索引,那么对于每个唯一索引,insert语句对应的writeset就要多增加一个hash值。
当然,对于“表上没主键”和“外键约束”的场景,WRITESET策略也是没法并行的,也会暂时退化为单线程模型。
PS:相关参数,了解即可
1.slave_parallel_type 默认值LOGICAL_CLOCK
注释:控制事务在从库上并发执行的策略。DATABASE表示开启数据库级别的MTS。LOGICAL_CLOCK表示开启事务级别的MTS。
补充:
数据库级别MTS是MySQL5.6.36中已有的特性。slave_preserve_commit_order要为off才会生效,但是5.7低版本slave_preserve_commit_order默认值为ON,如修改失败需要手动升级mysql版本。(5.6.40版本之后、5.7版本之后支持)
2.slave_preserve_commit_order 默认值OFF
注释:对于事务级并行复制(MTS),打开该变量能保证事务能在从库上按照relay日志的同样的顺序(也就是说和主库一样的顺序)。如果没有打开并行复制的话,那该变量设置不会生效。
对于多线程并发复制,打开该模式能保证和主库的状态一致。此外,如果未启用,则检查最近执行的事务并不能保证来自主服务器的所有先前事务都已在从服务器上执行。(5.6.40版本之后、5.7版本之后支持)
3.slave_parallel_workers 默认值32
注释:用于设置从库中并发执行的日志回放的线程数量。该值设置大于0,表示会在从库上开启多个并发线程的,数量由该变量决定。当设置为0时,表示关闭并行复制,采用单线程。设置该变量不会立即生效,直到下次重启复制(start slave)后才生效。
4.slave_rows_search_algorithms 默认值table_scan,index_scan
注释:在为基于行的日志记录和复制准备批处理行时,此变量控制如何搜索行以查找匹配项,即是否使用散列法用于使用主键或唯一键的搜索,使用其他键,或使用no键。
5.binlog_transaction_dependency_tracking 默认值COMMIT_ORDER(MySQL 5.7.22 引入)
注释:控制如何决定事务的依赖关系:
COMMIT_ORDER:表示继续使用 5.7 中的基于组提交的方式决定事务的依赖关系;
WRITESET:表示使用写集合来决定事务的依赖关系;
WRITESET_SESSION:表示使用WriteSet来决定事务的依赖关系,但是同一个Session内的事务不会有相同的last_committed值。
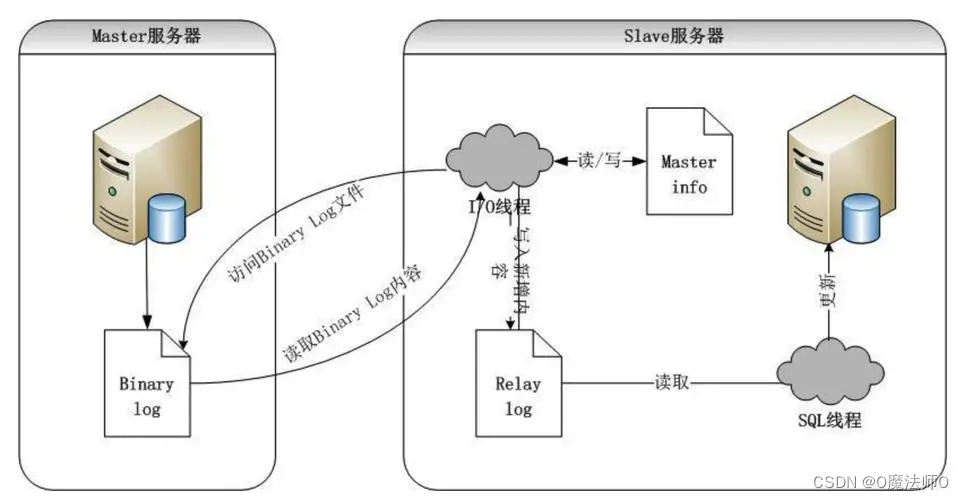
9、介绍下主从复制的原理?
10、介绍下MySQL的各个组件?
连接器:处理连接,用户密码校验,
预处理器:语法、语义、权限校验
解析器:把SQL打散成一块一块的 生成解析树
优化器:逻辑优化(代数的等价转换);物理优化(参考统计信息,优化器算法),最终生成执行计划explain
执行器:和存储引擎交互
11、undo log和redo log的区别?
undo日志:记录相反的操作,主要用在MVCC多版本并发控制中。文件名:undo_001
MVCC:undo + 三个隐藏字段(row_id,trx_id,roll_ptr) + read view
ReadView:m_ids, min_trx, max_trx, creator_trx_id
清理undo日志的线程:purge_thread
redo log:日志先行,记录buffer_pool所有数据的变化,有两类日志:数据页的变化,和 undo的数据(undo的redo日志先写,然后再写undo)
区别:
- redo用于恢复数据库,undo用于回滚事务。
- redo是物理日志,记录的是数据页的物理变化;undo是逻辑日志,只是将数据库逻辑地恢复到原来的样子。
- undo页面的修改也需要记录redo日志。
查看ib_logdata文件大小
12、SQL执行时快时慢,可能的原因?
第一种场景是如果 redo log 写满了,在这个时候,系统会停止所有更新操作,把脏页数据 flush 到磁盘上,然后 checkpoint 往前推进,redo log 留出空间可以继续写下去。
第二种场景是,系统内存不足,当需要新的内存页,而内存不够的时候,就需要腾出来一些数据页,空出内存供其它数据页使用,如果是脏页的话,就要先将脏页写到磁盘
原文链接:从头开始搞懂 MySQL(07)为什么同一条 SQL 时快时慢_mysql 查询时快时慢 如何解决-CSDN博客
13、什么是三大范式?
第一范式(1NF):每个列都不可分割。
第二范式(2NF):在第一范式的基础上,非主键列完全依赖于主键,而不能是依赖于主键的一部分。(完全依赖)
第三范式(3NF):在第二范式的基础上,非主键列只依赖于主键,不依赖于其他非主键。(不能有传递依赖)
14、什么是隐式提交?何时会触发?
隐式提交就是MySQL自动提交事务。
1)事务开启了后,执行了DDL语句,就会触发隐式提交
2)第二个BEGIN,会隐式提交 第一个BEGIN的事务
3)执行LOAD DATA
4)执行START SLAVE STOP SLAVE
5)执行FLUSH OPTIMIZE TABLE
15、XA事务的SQL语法
# 在mysql实例中开启一个XA事务,指定一个全局唯一标识;
mysql> XA START 'any_unique_id';
# XA事务的操作结束;
mysql> XA END 'any_unique_id';
# 告知mysql准备提交这个xa事务;
mysql> XA PREPARE 'any_unique_id';
# 告知mysql提交这个xa事务;
mysql> XA COMMIT 'any_unique_id';
# 告知mysql回滚这个xa事务;
mysql> XA ROLLBACK 'any_unique_id';
# 查看本机mysql目前有哪些xa事务处于prepare状态;
mysql> XA RECOVER;16、如何提高insert的性能?
a)合并多条 insert 为一条,即: insert
into t values(a,b,c), (d,e,f) ,
原因分析:主要原因是多条insert合并后日志量(MySQL的binlog和innodb的事务日志) 减少了,降低日志刷盘的数据量和频率,从而提高效率。通过合并SQL语句,同时也能减少SQL语句解析的次数,减少网络传输的IO。
b)修改参数
bulk_insert_buffer_size,
调大批量插入的缓存;
c)设置
innodb_flush_log_at_trx_commit = 0 ,相对于
innodb_flush_log_at_trx_commit = 1 可以十分明显的提升导入速度;
(备注:innodb_flush_log_at_trx_commit
d)手动使用事务
因为mysql默认是autocommit的,这样每插入一条数据,都会进行一次commit;所以,为了减少创建事务的消耗,我们可用手工使用事务,即START TRANSACTION;insert 。。,insert。。 commit;即执行多个insert后再一起提交;一般1000条insert 提交一次。17、介绍下MySQL的线程池
关于MySQL线程池,这也许是目前最全面的实用帖!_mysql线程池配置-CSDN博客
18、事务隔离级别有哪些?MySQL如何解决的幻读?
四种:读未提交、读已提交、可重复读、序列化读
不可重复读:同一事务内的两次查询,读到的同一行集合中数据是不同的。
幻读:同一事务内的两次查询,读到了不同的行集合。
MySQL在可重复读隔离级别下通过间隙锁解决了大部分幻读。
19、介绍下索引?聚簇索引、非聚簇索引的含义?什么是回表?
20、MySQL自增主键满了,怎么处理?
1)将字段类型改为BIGINT
2)使用UUID或GUID代替自增ID
字段类型 char(36) , 插入时使用uuid()函数来自动生成新的UUID值。
21、如何删除大表?
参考链接:MySQL删除大表文件解决方案_mysql如何删除大表-CSDN博客
- 数据表.ibd文件,创建文件硬链接
- drop table删除表结构,数据,磁盘中物理文件(物理文件删除的是一个文件的硬链接)
- 使用truncate对物理文件进行截断,直至足够小后直接删除
22、索引失效可能的原因?
概括:统计数据不准、隐式转换、使用了函数、字符集不一致
1. 使用or操作符
2. 复合索引失效
3. like查询 以%开头
4. 索引列上使用函数
5. 隐式类型转换
6. 对索引进行表达式计算
23、慢SQL如何优化

















 7353
7353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









