






Implementing a CNN for Text Classification in TensorFlow
代码见GitHub
The full code is available on Github.
在这篇文章中,我们用了与 Kim Yoon’s
Convolutional Neural Networks for Sentence Classification模型类似的模型, 论文中的模型通过一系列文本分类取得了很好的分类效果,已经成为后来文本分类体系结构的标准基准。
我将假设你已经熟悉了在自然语言处理中应用卷积神经网络的基础知识,如果没有,建议先阅读
Understanding Convolutional Neural Networks for NLP 来了解必要的背景知识。
数据处理
使用的数据集为电影评论,数据集中有10662条评论语句,一半positive,一半negative,词汇量大约20k。此处,我们用10%的数据做dev set。
此处不讲数据预处理,GitHub有代码:
- 从原始数据文件中加载数据
- 用与原文一样的代码清洗数据
- 用<pad>填充每个句子使长度一致,长度为59个词,长度一致可以高效地批处理数据
- 建立词汇索引,将每个字标记上一个0到18765(词汇量)之间的整数,这样每个句子就成了一个整数向量
模型(The Model)
第一层将字组织成低维向量,下一层用多种过滤器大小在映射成的字向量上进行卷积运算,例如,一次滑动3,4或5个字。然后我们将卷积层的结果通过max-pool化为一个长特征向量,添加dropout正则化,用softmax层将结果分类。
为方便讲解,此处略微简化下原论文的模型:
不会用提前训练好的word2vec矢量数据 作为我们的word embedding,我们学一下从头开始映射(embed)
我们不会在权重向量上用L2常规约束,已有论文证明此约束对最终结果影响甚小
原论文中的实验用了两个数据输入渠道——静态和非静态字向量,我们只用一种
将以上扩展加入代码中并不难(几十行代码而已),可以看一下本文结尾的练习。
下面正式开始!
实现(Implementation)
我们把代码放在了TextCNN类中,以便进行不同的超级参数(Hyperparameter)设置,在init函数中生成模型图。
importtensorflow as tf
importnumpy as np
classTextCNN(object):
"""
A CNN for text classification.
Uses an embedding layer, followed by a convolutional, max-pooling and softmax layer.
"""
def__init__(
self, sequence_length, num_classes, vocab_size,
embedding_size, filter_sizes, num_filters):
#implementation
参数介绍:
sequence_length 句子的长度。我们已将所有句子填充至等长(59)
num_classes 输出层的类个数,此项目中是二——positive和negative
vocab_size 词汇规模,用来定义嵌入层的大小,形如[vacabulary_size,embedding_size]
embedding_size 嵌入(embeddings)的维数
filter_sizes 我们希望的卷积过滤器覆盖的单词数。我们将为每个大小指定过滤器,例如,[3,4,5]表示我们分别设置滑过3,4,5个词的过滤器,即共有3*num_fliters个过滤器
num_filters 针对每个过滤器大小的过滤器个数
输入占位符
从定义传递给网络的输入数据开始:
# Placeholders for input, output and dropout
self.input_x= tf.placeholder(tf.int32, [None, sequence_length], name="input_x")
self.input_y= tf.placeholder(tf.float32, [None, num_classes], name="input_y")
self.dropout_keep_prob= tf.placeholder(tf.float32, name="dropout_keep_prob")
tf.placeholder创建了一个占位符变量,在训练或测试时用于反馈给网络。第二个参数是输入张量(input tensor)的形式,none表示维度的长度是任意的,在本例中第一维是批处理大小,使用none允许网络处理任意大小的批处理。
在dropout层保存一个神经元也是对网络的输入,因为我们只在训练时允许dropout,评估模型时禁止。
嵌入层(embedding layer)
嵌入层使我们声明的第一个层,它将字索引映射到低维向量表示,本质上是一个从数据中学习的查找表。
with tf.device('/cpu:0'), tf.name_scope("embedding"):
W= tf.Variable(
tf.random_uniform([vocab_size, embedding_size], -1.0,1.0),
name="W")
self.embedded_chars= tf.nn.embedding_lookup(W, self.input_x)
self.embedded_chars_expanded= tf.expand_dims(self.embedded_chars,-1)
此处应用了几个新功能:
tf.device("/cpu:0) 进行CPU执行的操作,默认情况下TensorFlow会将操作放在GPU上,如果有的话。但是嵌入层的实现现在没有GPU支持,放在GPU上回抛出错误。
tf.name_scope 创建一个名为embedding的NameScope,它将所有操作加至名为embedding的顶层节点以方便你在TensorBoard可视化操作
w 是在训练时学到的嵌入层矩阵。我们用一个随机统一分布(random uniform distribution)初始化它
tf.nn.embedding_lookup 创建一个实在的嵌入层操作,嵌入层操作的结果是产生一个三维tensor [None,sequence_length,embedding_size]
TensorFlow的卷积conv2d操作需要一个四维tensor:batch,width,height,channel。我们的嵌入层结果没有channel这一维,需要手动添加,所以最终该层为[None,sequence_length,embedding_size,1]
Convolution and Max-Pooling Layers卷积和最大池层
现在我们可以建造卷积层和max-pooling了,注意我们用了不同大小的过滤器(filter)。由于每个卷积产生不同形状的tensor,因此我们需要标识(iterate)他们,为每一个创建一个层,然后将结果合并进一个大的特征向量。
|
w 是过滤矩阵,h 是对卷积输出层应用非线性处理(nonlinearity)的结果。每个过滤器滑过整个嵌入,但是覆盖的字数不同。“VALID”padding表示过滤器滑过了整个句子没有填充边缘,执行一个窄卷积得到输出[1,sequence_length-filter_size+1,1,1]。对特定大小的过滤器输出执行max-pooling得到一个tensor[batch_size,1,1,num_filters]。这本质是一个特征向量,最后一维对应我们的特征。得到所有大小的过滤器的池化输出tensor后将他们合并入一个长特征向量[batch_size,num_filters_total]。在tf.reshape中使用-1告诉TensorFlow在可能时降维(flatten the dimension)
可以花点时间理解这些操作的输出形式,回去看《理解自然语言处理中的卷积神经网络》。TensorBoard可视化操作也可以帮助理解。
Dropout Layer
Dropout也许是正则化卷积神经网络最流行的方法,Dropout背后的思想很简单。dropout层随机“禁用”一部分神经元,有效防止神经元共适应(co-adapting),迫使它们学习独立有用的特征。可用的那部分神经元由dropout_keep_prob对网络的输入定义,在训练时我们将它设为0.5,评估时设为1(禁用dropout)。
# Add dropout
with tf.name_scope("dropout"):
self.h_drop= tf.nn.dropout(self.h_pool_flat,self.dropout_keep_prob)
Scores and Predictions 分数和预测
使用来自最大池的特征向量,我们可以通过做矩阵乘法和选择得分最高的类来生成预测。也可以使用softmax函数将原始分数转换为标准概率,但这不会改变最终预测。
with tf.name_scope("output"):
W= tf.Variable(tf.truncated_normal([num_filters_total, num_classes], stddev=0.1), name="W")
b= tf.Variable(tf.constant(0.1, shape=[num_classes]), name="b")
self.scores= tf.nn.xw_plus_b(self.h_drop, W, b, name="scores")
self.predictions= tf.argmax(self.scores,1, name="predictions")
这里,tf.nn.xw_plus_b是执行Wx+b矩阵乘法的容器。
Loss and Accuracy 损失和准确度
使用得分可以定义损失函数。损失(loss)是对我们的网络犯的错误的衡量,我们的目标是最小化损失。分类问题的标准损失函数是交叉熵损失(cross-entropy loss
http://cs231n.github.io/linear-classify/#softmax)
# Calculate mean cross-entropy loss
with tf.name_scope("loss"):
losses= tf.nn.softmax_cross_entropy_with_logits(self.scores,self.input_y)
self.loss= tf.reduce_mean(losses)
这里,tf.nn.softmax_cross_entropy_with_logits是为每个类计算交叉熵损失的函数,根据我们的分数和正确的输入标签。然后我们可以选择损失的平均值。也可以使用总和,但这样会更难比较不同批量和训练/dev数据的损失。
也可以定义一个训练和测试期间追踪有用的量的精度表达式。
# Calculate Accuracy
with tf.name_scope("accuracy"):
correct_predictions= tf.equal(self.predictions, tf.argmax(self.input_y,1))
self.accuracy= tf.reduce_mean(tf.cast(correct_predictions, "float"), name="accuracy")
网络定义工作已经完成。所有代码可以在此
https://github.com/dennybritz/cnn-text-classification-tf/blob/master/text_cnn.py
获得。可以在TensorBoard中可视化网络得到大图
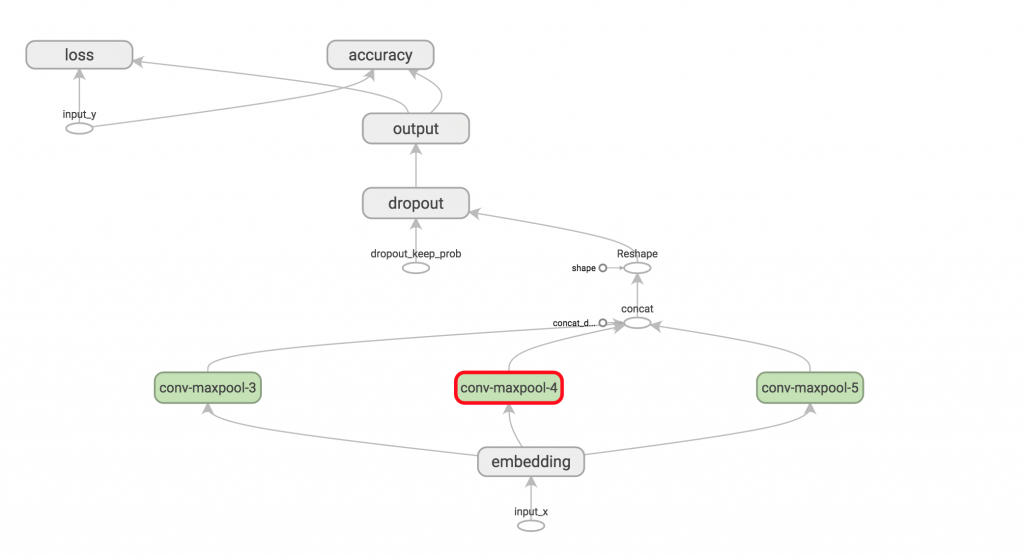
训练过程
为网络定义训练程序之前需要了解TensorFlow如何使用会话和图形的基本知识。如果你已经熟悉了这些概念,可以跳过本节。
在TensorFlow中,会话(Session)是一个你可以在其中进行图形操作的环境,它包含变量和队列的状态。每个会话都在一个图上进行。如果在穿件变量和操作时没有明确指定会话将使用TensorFlow创建的默认会话。可以通过在session.as_default()块内执行命令来更改会话(具体往下看)。
图形包含操作和张量(tensors),可以在程序中使用多个图,但大多数程序只需一个图。可以在多个会话中使用相同的图,但不能在一个会话中使用多个图。TensorFlow会创建默认图,你可以手动创建一个图并把它设为新的默认图,这就是我们接下来要做的。显式创建会话和图可以确保资源在不再使用时正确释放。
with tf.Graph().as_default():
session_conf= tf.ConfigProto(
allow_soft_placement=FLAGS.allow_soft_placement,
log_device_placement=FLAGS.log_device_placement)
sess= tf.Session(config=session_conf)
with sess.as_default():
# Code that operates on the default graph and session comes here...
allow_soft_placement
http://www.tensorflow.org/how_tos/using_gpu/index.html
设定可以让TensorFlow在首选设备不存在时再可以执行特定操作的设备上回退。例如,如果我们的代码需要在GPU上操作,而我们在没有GPU的机器上运行代码,不使用allow_soft_placement将会导致错误。如果
设置了
log_device_placement
TensorFlow会登录能放置操作的设备(CPU或GPU),这对debug很有用。FLAGS是我们程序的命令行参数。
Instantiating the CNN and minimizing the loss 实例化CNN并最小化损失
实例化TextCNN模型时所有变量和操作将会被放在我们上面创建的默认的图和会话中。
cnn= TextCNN(
sequence_length=x_train.shape[1],
num_classes=2,
vocab_size=len(vocabulary),
embedding_size=FLAGS.embedding_dim,
filter_sizes=map(int, FLAGS.filter_sizes.split(",")),
num_filters=FLAGS.num_filters)global_step= tf.Variable(0, name="global_step", trainable=False)
optimizer= tf.train.AdamOptimizer(1e-4)
grads_and_vars= optimizer.compute_gradients(cnn.loss)
train_op= optimizer.apply_gradients(grads_and_vars, global_step=global_step)
train_op是一个新创建的操作,可以用来对参数执行梯度更新。train_op每次执行都是一个训练步骤,TensorFlow自动算出哪些变量是可训练的并计算出它们的梯度。通多定义一个名为global_step的变量并把优化器传值给它,可以让TensorFlow为我们计数训练步骤,每执行一次train_op全局步骤(global step)自动加一。
Summaries 摘要
TensorFlow有一个summaries的概念(
https://www.tensorflow.org/versions/master/how_tos/summaries_and_tensorboard/index.html#tensorboard-visualizing-learning
),可以让你在训练和评估时追踪和可视化各种数量。比如,你可能想追踪随时间变化的损失和精确度。也可以追踪更复杂的变量,例如图层激活的直方图。摘要是序列化的对象,使用SummaryWriter(
https://www.tensorflow.org/versions/master/api_docs/python/train.html#SummaryWriter
)写入磁盘。
# Output directory for models and summaries
timestamp= str(int(time.time()))
out_dir= os.path.abspath(os.path.join(os.path.curdir, "runs", timestamp))
print("Writing to {}\n".format(out_dir))
# Summaries for loss and accuracy
loss_summary= tf.scalar_summary("loss", cnn.loss)
acc_summary= tf.scalar_summary("accuracy", cnn.accuracy)
# Train Summaries
train_summary_op= tf.merge_summary([loss_summary, acc_summary])
train_summary_dir= os.path.join(out_dir, "summaries","train")
train_summary_writer= tf.train.SummaryWriter(train_summary_dir, sess.graph_def)
# Dev summaries
dev_summary_op= tf.merge_summary([loss_summary, acc_summary])
dev_summary_dir= os.path.join(out_dir, "summaries","dev")
dev_summary_writer= tf.train.SummaryWriter(dev_summary_dir, sess.graph_def)这里,我们分别追踪训练和测试的摘要。这该案例中他们是相同的量,但是你可能会有只想在训练期间追踪的量,比如变量更新值。tf.merge_summary是一个将多个汇总操作合并成一个可执行操作的函数。
Checkpointing 检查点
另一个常用的TensorFlow功能是检查点(
checkpointing
)--保存模型的参数以便稍后恢复。可以在新检查点之后继续训练,也可以使用以前的检查点选择最佳参数设定。检查点由
Saver
类创建。
# Checkpointing
checkpoint_dir= os.path.abspath(os.path.join(out_dir, "checkpoints"))
checkpoint_prefix= os.path.join(checkpoint_dir, "model")
# Tensorflow assumes this directory already exists so we need to create it
ifnot os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
saver= tf.train.Saver(tf.all_variables()Initializing the variables 初始化变量
在训练模型前需要初始化图中的变量。
|
sess.run(tf.initialize_all_variables())
|
initialize_all_variables
函数可以方便地初始化我们定义的所有变量。你也可以手动初始化你的变量。例如,使用预先训练的值初始化你的嵌入(embeddings)是很有用的。
Defining a single training step 定义一个训练步骤
现在我们来为单个训练步骤定义一个函数,在批量数据上评估模型、更新模型参数
deftrain_step(x_batch, y_batch):
"""
A single training step
"""
feed_dict= {
cnn.input_x: x_batch,
cnn.input_y: y_batch,
cnn.dropout_keep_prob: FLAGS.dropout_keep_prob
}
_, step, summaries, loss, accuracy = sess.run(
[train_op, global_step, train_summary_op, cnn.loss, cnn.accuracy],
feed_dict)
time_str= datetime.datetime.now().isoformat()
print("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy))
train_summary_writer.add_summary(summaries, step)
feed_dict包含传递给网络的占位符节点数据。你必须为所有占位符节点赋值,否则TensorFlow会报错。处理输入数据的另一种方法是使用队列,但这超出了本文的讨论范围。
接下来,我们使用session.run执行train_op,返回我们要求它评估的所有操作的值。记住train_op什么也不返回,它只是更新网络参数。最后输出当前批次的损失和精度,保存摘要到磁盘。注意,如果批量较小,训练批次的损失和精度可能因批次而异。由于我们使用dropout,你的训练指标可能比评估指标更糟。
我们在随机数据集
(arbitrary data set)
上写了个类似的函数来评估损失和精度,例如一个有效集或者整个训练集。重要的是,这个函数和上边的函数功能相同,但是没有训练操作。它也禁用dropout。
defdev_step(x_batch, y_batch, writer=None):
"""
Evaluates model on a dev set
"""
feed_dict= {
cnn.input_x: x_batch,
cnn.input_y: y_batch,
cnn.dropout_keep_prob:1.0
}
step, summaries, loss, accuracy = sess.run(
[global_step, dev_summary_op, cnn.loss, cnn.accuracy],
feed_dict)
time_str= datetime.datetime.now().isoformat()
print("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy))
ifwriter:
writer.add_summary(summaries, step)Training loop 训练循环
最后,准备写训练循环。遍历每个批次的数据,调用train_step函数,间或评估和检查模型:
# Generate batches
batches= data_helpers.batch_iter(
zip(x_train, y_train), FLAGS.batch_size, FLAGS.num_epochs)
# Training loop. For each batch...
forbatch in batches:
x_batch, y_batch = zip(*batch)
train_step(x_batch, y_batch)
current_step= tf.train.global_step(sess, global_step)
ifcurrent_step % FLAGS.evaluate_every ==0:
print("\nEvaluation:")
dev_step(x_dev, y_dev, writer=dev_summary_writer)
print("")
ifcurrent_step % FLAGS.checkpoint_every ==0:
path= saver.save(sess, checkpoint_prefix, global_step=current_step)
print("Saved model checkpoint to {}\n".format(path))
batch_iter
是批处理数据的辅助函数,
tf.train.global_step
是返回
global_step的值的函数。完整训练代码见这里:
The full code for training is also available here.
在TensorBoard中将结果可视化
tensorboard --logdir
/PATH_TO_CODE/runs/1449760558/summaries/
使用默认参数(128维嵌入,过滤器大小为3,4,5,dropout为0.5,每个大小的过滤有128个过滤器)运行训练过程会产生以下损失和精度曲线图(蓝色是训练数据,红色是10%dev数据)
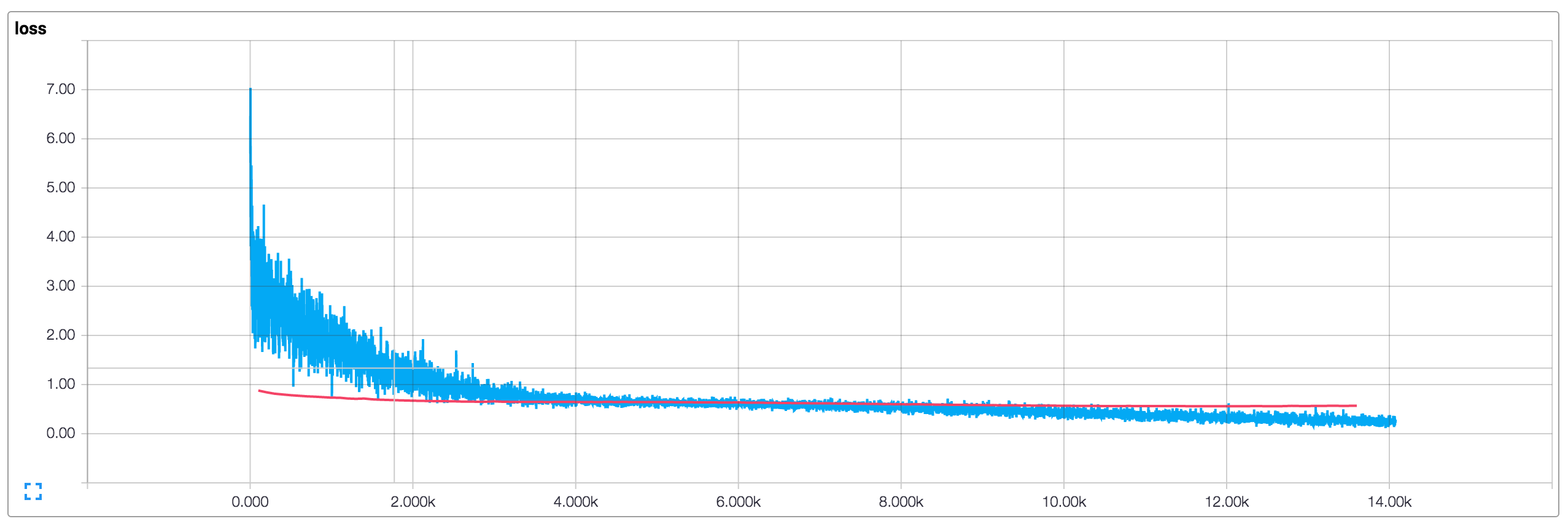
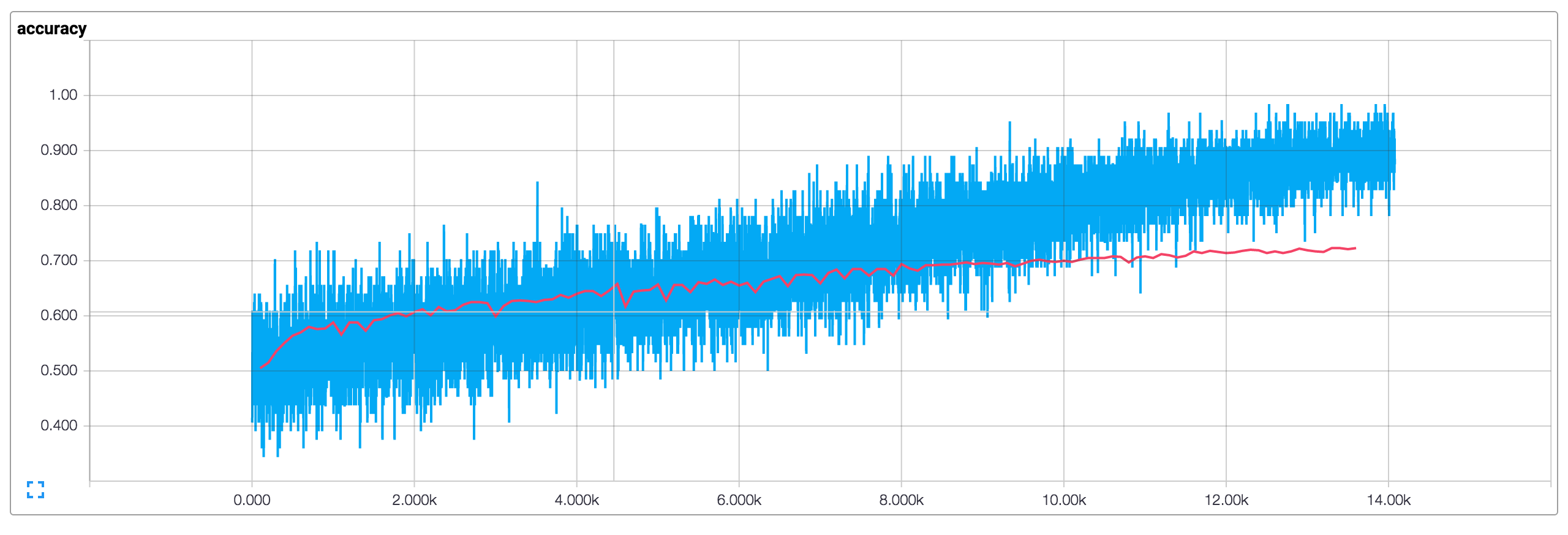
这里需要说明几件事:
- 由于使用了小批量,我们的训练指标(training metrics)并不平滑。如果使用大批量(或在整个训练集上进行评估)会得到一条更平滑的蓝线
- 由于开发(dev)精度明显低于训练精度,看上与很想网络过拟合训练数据。说明我们需要更多的数据(MR数据集很小),需要更强的正则化或更少的模型参数,例如 我尝试在最后一层为权重添加额外的L2惩罚可以将精度提高到76%,接近于原论文中的结果。
- 由于使用了dropout训练损失和精度开始时显著低于开发指标(dev metrics)
扩展训练
有几个提高模型性能的练习:
- 使用预先训练的 word2vec向量初始化嵌入。你需要使用300维嵌入并用预先训练的值初始化
- 在最后一层限制权重向量的L2范数,参考原始论文( original paper)。可以通过定义一个新的操作,该操作可以在每一步训练后更新权重值来实现。
- 增加L2正则化到网络来对付过度拟合 也是增加抛出率的试验,(GitHub上的代码包含L2正则,但默认禁用)
- 为权重更新和图层操作添加直方图摘要,并在TensorBoard中将其显示。















 9973
9973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









