







 该博客介绍了如何使用TensorFlow构建CNN模型进行文本分类。文章详细阐述了CNN的原理,包括将句子转化为向量、卷积、最大池化等步骤,并展示了模型的构建过程,包括Embedding Layer、卷积层、池化层、全连接层和Softmax层。此外,还讨论了dropout作为正则化方法的作用以及训练和评估模型的过程。
该博客介绍了如何使用TensorFlow构建CNN模型进行文本分类。文章详细阐述了CNN的原理,包括将句子转化为向量、卷积、最大池化等步骤,并展示了模型的构建过程,包括Embedding Layer、卷积层、池化层、全连接层和Softmax层。此外,还讨论了dropout作为正则化方法的作用以及训练和评估模型的过程。
cnn在计算机视觉领域取得了很好的结果,同时它可以应用在文本分类上面,此文主要介绍如何使用tensorflow实现此任务。
cnn实现文本分类的原理
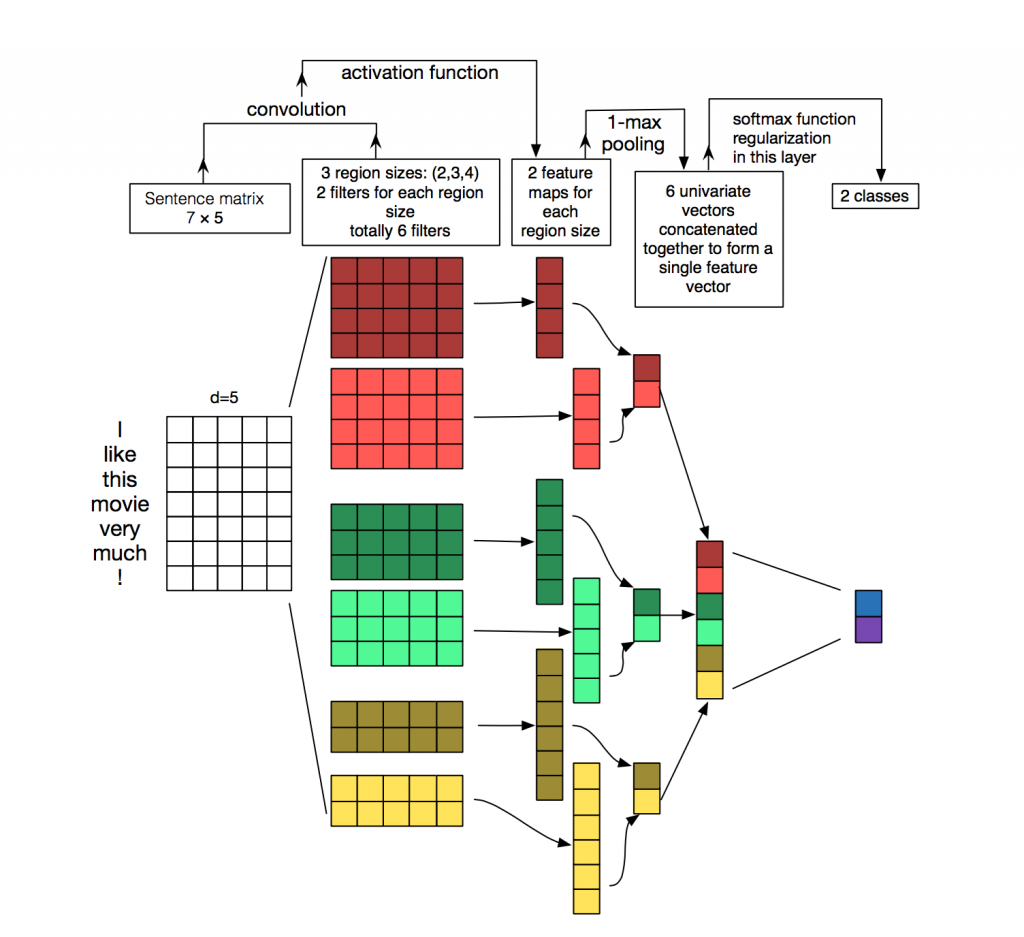
下图展示了如何使用cnn进行句子分类。输入是一个句子,为了使其可以进行卷积,首先需要将其转化为向量表示,通常使用word2vec实现。d=5表示每个词转化为5维的向量,矩阵的形状是[sentence_length × 5],即[7 × 5]。6个filter(卷积核),与图像中使用的卷积核不同的是,nlp使用的卷积核的宽与句子矩阵的宽相同,只是长度不同。这里有(2,3,4)三种size,每种size有两个filter,一共有6个filter。然后开始卷积,从图中可以看出,stride是1,因为对于高是4的filter,最后生成4维的向量,(7-4)/1+1=4。对于高是3的filter,最后生成5维的向量,(7-3)/1+1=5。卷积之后,我们得到句子的特征,使用activation function和1-max-pooling得到最后的值,每个filter最后得到两个特征。将所有特征合并后,使用softmax进行分类。图中没有用到chanel,下文的实验将会使用两个通道,static和non-static,有相关的具体解释。
本文使用的模型
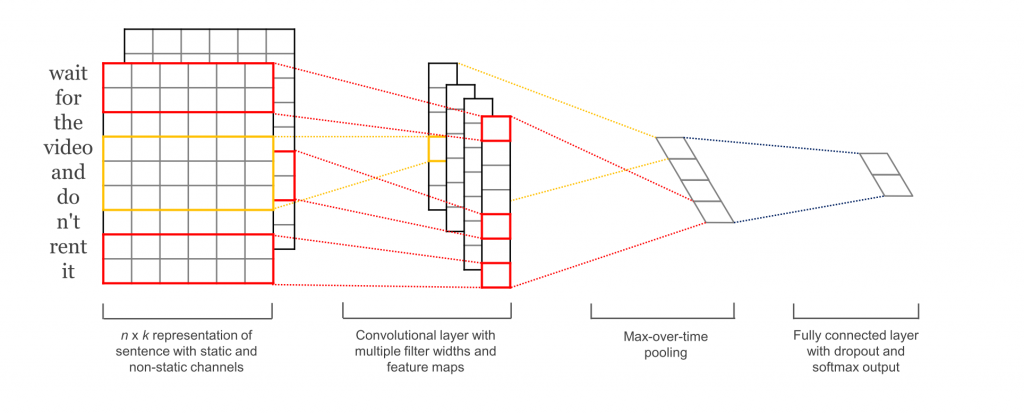
主要包括五层,第一层是embedding layer,第二层是convolutional layer,第三层是max-pooling layer,第四层是fully connected layer,最后一层是softmax layer.接下来依次介绍相关代码实现。
Input placeholder
# Placeholders for input, output and dropout
self.input_x = tf.placeholder(tf.int32, [None, sequence_length], name="input_x")
self.input_y = tf.placeholder(tf.float32, [None, num_classes], name="input_y")
self.dropout_keep_prob = tf.placeholder(tf.float32, name= 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 875
875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









