







第6章 SVM
支持向量机是一种二分类模型,其基本模型是定义在特征空间上间隔最大的线性分类器,间隔最大使它有别于感知机;其核技巧使其成为非线性分类器
函数间隔:定义超平面(w,b)关于样本点 (xi,yi) 的函数间隔为
γi^=yi(w∗xi+b)
几何间隔:可以理解成点到面的距离,不会因为w,b的集体变化而变化(w,b集体变化,超平面不变),
公式为: γi=w||w||xi+b||w||
有 γ̂ =||w||γ
【注意到上面的几何间隔和函数间隔,也就是说如果等比例的改变w,b,超平面不变,对于函数间隔公式,左右两边同时变化,一定有w,b使得 γ̂ =1】
线性可分支持向量机
线性可分支持向量机的最大间隔超平面可以表示为下面的约束最优化问题:
转化为:
由上面所述,令 γ̂ =1,且求 1||w|| 的最大值与求 12||w||2 的最小值等价,故而将上诉问题转化为如下:
将上式不等式转换为如下:
构建拉格朗日函数,对每个不等式约束引进拉格朗日乘子
其问题对应:
求
解得:
代入
将问题转化为如下:
线性支持向量机
是线性可分支持向量机的扩展,对约束问题做如下改变
对约束条件加上松弛变量,变为:
同时对每个松弛变量 ξi ,需支付一个代价 ξi ,目标函数变为:
这里的C>0,为惩罚参数,C值越大,对误分类的惩罚越大,C值越小,对误分类的惩罚越小
线性不可分的线性支持向量机的学习问题变为如下的凸二次规划问题:
同上面求解线性可分支持向量机最优化问题一样
不等式转化为小于等于的形式:
转化为拉格朗日函数,添加拉格朗日乘子 αi , μi :
求解
上面这个式子等价如下:
即 C−αi−μi=0
往回代,
原式:
转化为最小值问题,并消去 μ :
SMO算法
SMO算法是对上面凸二次规划的对偶问题的一种高效解决方法,具体如下:
每次选取两个参数
α1,α2
,其他变量为固定的,则对偶问题中的主以写为:
关于二次规划问题就不详述了,直接讲算法原理
1.选取变量
第一个变量的选取看样本点是否满足KKT条件:
不满足的条件就两种情况: αi>0andyig(xi)≥1 和 αi<Candyig(xi)≤1 ,
书中说道是在
ε
范围内进行,即上述不满足的情况变为如下
第二个变量的选取见统计学习方法中p129, E1 为正,选取最小的 Ei 作为 E2 ; E1 为负,选取最大得 Ei 作为 E2
2.关于边界条件的选取
二次规划在约束条件下对应的最小或最大值,见P126
3.新值的计算
其中 η 的求解,程序中直选取小于0的部分, η 表示的是二阶导,如果大于0,表示没有极小值,极小值在边界,而当 η =0的情况,书中说道比较复杂未考虑,可以参见
http://blog.csdn.net/luoshixian099/article/details/51227754
下面摘取一部分:
大部分情况下,有η=K11+K22−2K12>0。但是在如下几种情况下,αnew2需要取临界值L或者H.
- η<0,当核函数K不满足Mercer定理时,矩阵K非正定;
- η=0,样本x1与x2输入特征相同;
也可以如下理解,对(3)式求二阶导数就是η=K11+K22−2K12,
当η<0时,目标函数为凸函数,没有极小值,极值在定义域边界处取得。
当η=0时,目标函数为单调函数,同样在边界处取极值。
计算方法:
即当αnew2=L和αnew2=H分别带入(9)式中,计算出αnew1=L1和αnew1=H1,其中s=y1y2
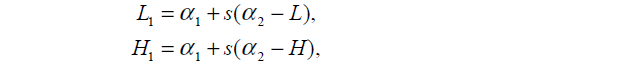
带入目标函数(1)内,比较Ψ(α1=L1,α2=L)与Ψ(α1=H1,α2=H)的大小,α2取较小的函数值对应的边界点。
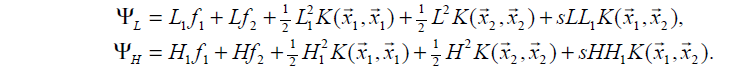
其中
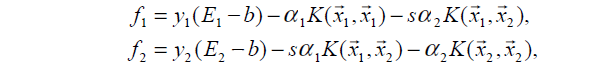
顺便有一篇博客讲得还不错:http://blog.csdn.net/on2way/article/details/47730367
4.b和 Ei 的求解P130有讲到
具体程序如下:
from numpy import mat, shape, zeros, multiply
def loadDatas():
dataMat=[]
labelMat=[]
with open("testSet.txt",'r') as f:
dateline=f.readline()
while dateline:
lineArr=dateline.strip().split('\t')
dataMat.append([float(lineArr[0]),float(lineArr[1])])
labelMat.append(float(lineArr[2]))
dateline=f.readline()
return dataMat,labelMat
#计算ei
def calculEi(alphas,b,dataMatrix,labelMatrix):
eilist=[]
m=len(labelMatrix)
for i in range(m):
# 这个是g(xi),即拟合的y值;其中有个[i,:]表示获取第i行
gxi = float(multiply(alphas, labelMatrix).T * (dataMatrix * dataMatrix[i, :].T)) + b
ei = gxi - float(labelMatrix[i]) # 误差
eilist.append(ei)
return eilist
#获取最大值对应的下标
def getMaxIndex(eilist):
maxValue=eilist[0]
index=0
for i in range(len(eilist)):
if eilist[i]>maxValue:
maxValue=eilist[i]
index=i
return index
#获取最小值对应的下标
def getMinIndex(eilist):
minValue=eilist[0]
index=0
for i in range(len(eilist)):
if eilist[i]<minValue:
minValue=eilist[i]
index=i
return index
#选取第二个变量
def selectJFromEilist(ei,alphas,b,dataMat,labelMat):
eilist=calculEi(alphas,b,dataMat,labelMat)
j=0
if ei>0:j=getMaxIndex(eilist)
else:j=getMinIndex(eilist)
return j
#经剪辑后的a
def clipAlpha(al,H,L):
if al<L:al=L
elif al>H:al=H
return al
def smoSimple(dataMat,labelMat,C,toler,maxIter):
#转化为矩阵
dataMatrix=mat(dataMat)#
labelMatrix=mat(labelMat).transpose()#和.T的效果一样,转置
m,n=shape(dataMatrix)#获取数组的维度信息,这里是获取二维数组的行数和列数
alphas=mat(zeros((m,1)))#参数a,注意这个zeros函数,生成m行1列值为0的数组
b=0#参数b
iter=0#存储没有任何alpha改变的情况下遍历数据集的次数
while (iter<maxIter):
alphasChanged=0
for i in range(m):
eilist=calculEi(alphas,b,dataMatrix,labelMatrix)
ei=eilist[i]
#下面这个是找到不满足KKT条件的,(g(xi)-yi)*yi=yi*g(xi)-1
if(((labelMatrix[i]*ei<-toler) and (alphas[i]<C)) or ((labelMatrix[i]*ei>toler)and(alphas[i]>0))):
j=selectJFromEilist(ei)
ej=eilist[j]
#存取old变量
alphasIold=alphas[i]
alphasJold=alphas[j]
#确定边界值
if(labelMat[i]!=labelMat[j]):
L=max(0,alphas[j]-alphas[i])
H=min(C,C+alphas[j]-alphas[i])
else:
L=max(0,alphas[j]+alphas[i]-C)
H=min(C,alphas[j]+alphas[i])
if L==H:continue#L=H表明新的值被固定,不能改变了,故而没有必要进行下面的过程
eta=2.0*dataMatrix[i,:]*dataMatrix[j,:].T-dataMatrix[i,:]*dataMatrix[i,:].T-dataMatrix[j,:]*dataMatrix[j,:].T
# 书中说到此处为简化过程,详见我的文字说明
if eta>=0:continue
alphas[j]-=labelMat[j]*(ei-ej)/eta
alphas[j]=clipAlpha(alphas[j],H,L)#剪辑
#如果变化很小,则从新选取
if (abs(alphas[j]-alphasJold)<0.00001):
print("j not moving enough")
continue
alphas[i]+=labelMat[j]*labelMat[i]*(alphasJold-alphas[j])
b1=b-ei-labelMat[i]*dataMatrix[i,:]*dataMatrix[i,:].T*(alphas[i]-alphasIold)-labelMat[j]*dataMatrix[j,:]*dataMatrix[i,:].T*(alphas[j]-alphasJold)
b2=b-ej-labelMat[i]*dataMatrix[i,:]*dataMatrix[j,:].T*(alphas[i]-alphasIold)-labelMat[j]*dataMatrix[j,:]*dataMatrix[j,:].T*(alphas[j]-alphasJold)
if (alphas[i]>0)and(alphas[j]<C):b=b1
elif (alphas[j]>0)and(alphas[j]<C):b=b2
else:b=(b1+b2)/2
alphasChanged+=1
if(alphasChanged==0):iter+=1
else:iter=0
return b,alphas
关于SMO算法参见原论文:Sequential Minimal Optimization: A Fast
Algorithm for Training Support Vector Machines
SVM到此结束。。。累!















 709
709

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









