







 本文介绍了一种名为层归一化的神经网络技术,它通过使用所有神经元的总输入而非单个神经元来计算归一化统计量,解决了批量归一化在循环神经网络中的局限性,显著提高了训练效率和模型泛化能力。
本文介绍了一种名为层归一化的神经网络技术,它通过使用所有神经元的总输入而非单个神经元来计算归一化统计量,解决了批量归一化在循环神经网络中的局限性,显著提高了训练效率和模型泛化能力。
论文链接:[1607.06450] Layer Normalization (arxiv.org)
一、论文翻译
Abstract
训练深度神经网络的计算开销很大。一个可以减少训练时间的方法是“归一化神经元活动”。近来一个叫做批量归一化的技术,在小批量训练情况下,使用一个神经元的总输入的分布来计算均值和方差,然后用于归一化每个训练样本上的神经元的总输入。这显著减少了前馈神经网络的训练时间。但是,批量归一化的影响依赖于batch size,并且不知道如何将它应用在循环神经网络中。在这篇论文中,我们不再使用一个神经元,而是使用单次训练情况下所有神经元的总输入来计算均值和方差,从而将批量归一化调换为层归一化。和批量归一化类似,我们同样给每一个神经元赋予自适应偏置和增益参数,这在归一化之后、非线性化之前发挥作用。和批量归一化不同的是,层归一化在训练和测试时执行完全相同的操作。通过分别计算每个时间步的归一化统计参数,可以将层归一化直接应用在循环神经网络中。层归一化在稳定循环网络隐藏层神经元的活跃性方面很高效。
Introduction
在计算机视觉与语音处理(speech processing)领域的各种监督学习任务中,使用随机梯度下降法训练深度神经网络已被证明明显优于先前的方法,但是近来的深度神经网络往往需要训练多日。想要加快训练速度,可以在多个机器上计算不同训练子集的梯度(训练集划分)或者将网络的神经元分布在不同机器上,但这类方法需要频繁的交互和复杂的软件支持,随着并行化程度的提高,收益会明显下降。另一类方法是修改神经网络前向传播时执行的计算,以使学习变得更容易。最近,批量归一化被提出,它通过在深度神经网络中引入归一化操作来减少训练时间。归一化是指使用训练数据集的均值和标准差来标准化每个神经元接收到的输入信号。使用批量归一化训练的前馈神经网络即使使用简单的SGD优化器也能很快收敛。除了训练时间的优化,批量统计中引入的随机性可以充当训练过程中的正则化器。(在批量归一化中,对单一批次进行归一化时会用到该批次中的所有样本的统计数据,而不会用到其他批次的样本数据,这能减少不同批次样本之间的相关性,从而避免过拟合,起到正则化器的作用)
批量归一化原理简单,但它需要对各个批次的总输入信号统计量执行平均运算(在训练时分别计算每个批次样本的均值与方差,在测试时会对训练时得到的所有均值与方差取平均,以此来对测试数据进行归一化)。在深度固定的前馈神经网络中,每个隐藏层可以直接分别存储各自的统计量,但是,循环神经网络的神经元的总输入信息会随着时间序列推进而变化,因此对RNN执行批量归一化时,不同的时间步需要不同的统计量(总而言之,批量归一化不适合应用于RNN)。此外,批量归一化不能应用于在线学习任务或者非常大规模的分布式模型。
这篇论文介绍了层归一化,这是一种简单的归一化方法,可以用于提高各种神经网络模型的训练速度。与批量归一化不同,层归一化直接从隐含层的所有神经元的总输入中直接估计归一化统计量,因此归一化不会再训练过程中引入新的依赖关系。我们展现了层归一化在RNN上表现很好,并优化了现有集中RNN模型的训练时间和泛化能力。
Background
前馈神经网络是从输入模式x到输出向量y的非线性映射。考虑前馈神经网络的第 个隐含层,令
表示该层所有神经元的总输入的向量表示,则
可以通过权重矩阵
和自下而上的输入
(也就是前一层的输出)来计算,公式如下:
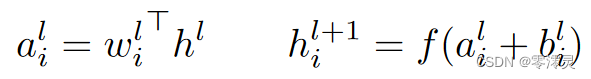
其中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2834
2834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









