







原文链接:[2106.09681] XCiT: Cross-Covariance Image Transformers (arxiv.org)
一、论文翻译
Abstract
Transformer在自然语言处理取得巨大成功,最近在CV领域也表现出巨大潜力。transformer中的自注意力操作可以生成tokens(例如单词或图像块)间的全局交互(因为自注意力会计算tokens两两之间的注意力分数),并且可以在卷积的局部操作之外对图像数据进行灵活建模。但是,为了达到这种灵活性,代价是时间以及空间复杂度达到O(),限制了长序列和高分辨率图像场景的应用。
我们提出了一种“transposed”版本的自注意力机制,它可以通过keys和queries之间的互协方差矩阵来跨特征通道(feature channels)计算注意力分数,而不仅仅是计算tokens之间的注意力分数。计算互协方差注意力(XCA)的时间复杂度与tokens数目成线性相关,并允许对高分辨率图像做处理。基于XCA的cross-covariance image transformer(XCiT)结合了传统transformer的高准确性和卷积架构的可拓展性,在实验中取得优异成果。
Introduction
Transformer架构在语音和NLP取得重大突破。最近,Dosovitskiy等人(An image is worth 16x16 words: Transformers for image recognition at scale)建立了以Transformer学习视觉表示的可行架构,依赖大规模预训练,从而在图像分类任务中取得优异结果。Touvron等人(Training data-efficient image transformers and distillation through attention)使用数据增强和改进的训练方案在imageNet-1k数据集上训练transformer,有良好表现。在图像检索、目标检测、语义分割以及视频理解任务中都有突破。
Transformer的主要缺点是最为关键的自注意力计算需要O()的时间和空间复杂度,对于w×h大小的图像,需要O(
)的开销,这导致目标检测和分割任务中处理高分辨率图像时受到限制。目前提出了一些解决策略,例如使用自注意力的近似形式,或者对特征图逐步下采样的金字塔结构,不过这些方案都不尽人意。
我们将自注意力替换成“transposed”注意力,称之为“cross-covariance attention”(XCA)。互协方差注意力通过在特征维度上计算自注意力来取代tokens之间计算自注意力,具有方法是计算tokens特征的keys和queries矩阵的互协方差矩阵,优点在于XCA计算的时间复杂度与tokens长度成线性关系。为了构建XCiT模型,我们将XCA与局部块交互模块(local patch interaction modules)结合,这些模块依赖于高效的深度卷积和transformer中常用的点式前馈网络(point-wise feedforward networks),如图1所示。XCA可看做动态1×1卷积,它将所有tokens乘以一个相同的权重矩阵,我们发现相较于把所有通道混合,将XCA应用在通道块上可以进一步提高性能,XCA的这种“块对角(block-diagonal)”形状进一步降低了计算复杂度,与blocks数目成线性关系。
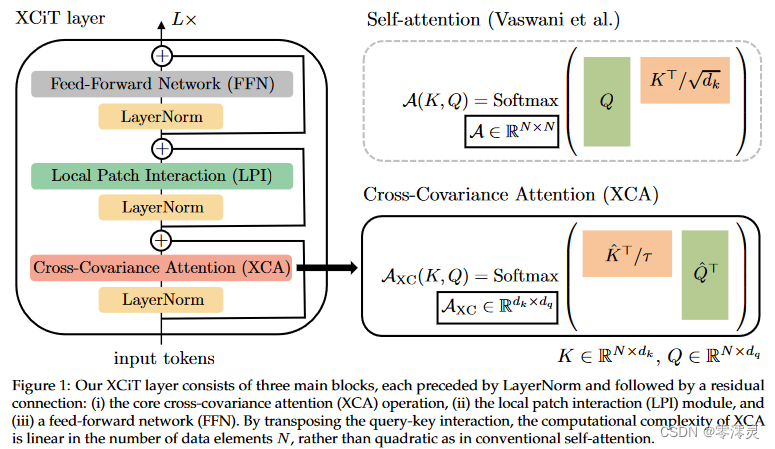
XCiT的计算时间复杂度与tokens数目成正比,所以可以处理高分辨率图像。另外,实验结果表明XCiT并不会降低准确率,在目标检测和图像分割任务上取得比基于ResNet和其他主流transformer的模型更优异的结果。
总的来说,本文贡献如下:
- 引入了cross-covaariance attention(XCA),它使用一种“transposed”来取代传统的自注意力,通过跨通道维度来计算注意力,而不是通过tokens维度来计算注意力。其复杂度达到O(n),可以处理高分辨率图像。
- XCA关注通道的数目,而不是tokens的数目,因此,图像分辨率的变化对模型影响很小(分辨率改变只会导致tokens数目变化,通道数不会改变),模型更适合处理可变尺寸图像。
- 对于图像分类任务,我们证明了我们的模型与最先进的vision transformer表现接近。
- 对于高分辨率图像的密集预测任务,我们的模型优于ResNet和多个基于Transformer的模型(Swin transformer: Hierarchical vision transformer using shifted windows.)。
Related work
Method
3.1 Background
Token self-attention Vaswani等人(Attention is all you need)提出自注意力机制,在输入矩阵上运算,其中N是tokens的数目,d是token的维度。使用权重矩阵
,
,
将输入矩阵X投影成Q(queries)、K(keys)、V(values)矩阵,即
,
,
, 其中
。使用Q和K矩阵计算注意力权重:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1566
1566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









