







原书配套代码5-2.py为python2运行环境,运行中遇到如下问题:
1.告警
from sklearn.externals import joblib警告:
#DeprecationWarning: sklearn.externals.joblib is deprecated in 0.21 and will be removed in 0.23. Please import this functionality directly from joblib, which can be installed with: pip install joblib. If this warning is raised when loading pickled models, you may need to re-serialize those models with scikit-learn 0.21+.warnings.warn(msg, category=DeprecationWarning)
可以通过升级版本,亦可以通过如下方法解决:
import joblib2.运行错误
(1)报错
ModuleNotFoundError: No module named ‘urlparse’
ModuleNotFoundError: No module named ‘HTMLParser’
import urlparse
import HTMLParser
修改如下:
from urllib.parse import urlparse
from html.parser import HTMLParser
(2)print报错
print y_test
print y_predict
print score
print classification_report(y_test, y_predict)加上括号
(3)版本不一致导致问题:
fdist = FreqDist(dist).keys()TypeError: ‘dict_keys’ object is not subscriptable
fdist = list(FreqDist(dist).keys())3.需要安装hmmlearn
安装方法:pip install joblib
4.运行准确率: GitHub上的源代码跑出的准确率是100%,而书上写为80%,这一点需要注意。
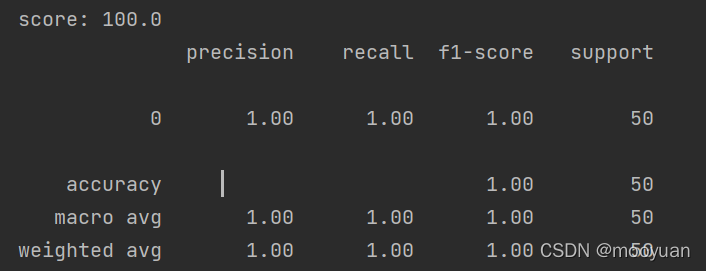
5.特征化函数get_user_cmd_feature解析:
github源码
def get_user_cmd_feature(user_cmd_list,dist_max,dist_min):
user_cmd_feature=[]
for cmd_block in user_cmd_list:
f1=len(set(cmd_block))
fdist = FreqDist(cmd_block).keys()
f2=fdist[0:10]
f3=fdist[-10:]
f2 = len(set(f2) & set(dist_max))
f3=len(set(f3)&set(dist_min))
x=[f1,f2,f3]
user_cmd_feature.append(x)以100个命令为统计单元,作为一个操作序列,KNN只能以标量作为输入参数,所以
f1:去重后的操作命令个数
f2:(最频繁10条命令)与(所有命令中最频繁的50条命令)的交集元素数量
f3: (最不频繁的10条命令)与(所有命令中最不频繁的50条命令)的交集元素数量
打印后f1、f2、f3代表的集合如下:
f1 {'sh', 'tail', 'ln', 'xmodmap', 'ksh', 'stty', 'grep', 'cat', 'ex', 'ls', 'hostname', 'uname', 'netscape', '.java_wr', 'sed', 'netstat', 'runnit'}
f2 {'sh', 'xmodmap', 'ksh', 'stty', 'grep', 'cat', 'hostname', 'uname', 'tail', 'sed'}
f3 {'runnit'}
f1: 17 10 1
f1 {'egrep', 'basename', 'dirname', 'java', 'ls', 'find', 'expr', '.java_wr', 'runnit'}
f2 {'basename', 'egrep', 'dirname', 'ls', 'java', 'expr', '.java_wr'}
f3 {'runnit', 'find'}
f1: 9 7 2
f1 {'egrep', 'basename', 'javac', 'rm', 'make', 'dirname', 'java', 'ls', 'ex', 'expr', 'more', 'netscape', 'mailx', '.java_wr'}
f2 {'basename', 'egrep', 'javac', 'make', 'rm', 'dirname', 'java', 'ls', 'expr', '.java_wr'}
f3 set()
f1: 14 10 0
6.所有源码,python3环境
# -*- coding:utf-8 -*-
import numpy as np
from nltk.probability import FreqDist
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report
from sklearn import metrics
#测试样本数
N=100
def load_user_cmd(filename):
print('load_user_cmd:', filename)
cmd_list=[]
dist_max=[]
dist_min=[]
dist=[]
with open(filename) as f:
i=0
x=[]
for line in f:
line=line.strip('\n')
x.append(line)
dist.append(line)
i+=1
if i == 100:
cmd_list.append(x)
x=[]
i=0
fdist = list(FreqDist(dist).keys())
dist_max=set(fdist[0:50])
dist_min = set(fdist[-50:])
print('dist_max:',dist_max)
print('dist_min:',dist_min)
print('cmd_list', len(cmd_list))
return cmd_list,dist_max,dist_min
def get_user_cmd_feature(user_cmd_list,dist_max,dist_min):
user_cmd_feature=[]
for cmd_block in user_cmd_list:
f1=len(set(cmd_block))
print('f1',set(cmd_block))
fdist = list(FreqDist(cmd_block).keys())
f2=fdist[0:10]
f3=fdist[-10:]
print('f2', set(f2) & set(dist_max))
print('f3', set(f3) & set(dist_min))
f2 = len(set(f2) & set(dist_max))
f3=len(set(f3)&set(dist_min))
x=[f1,f2,f3]
user_cmd_feature.append(x)
print('f1:', f1,f2,f3)
return user_cmd_feature
def get_label(filename,index=0):
x=[]
with open(filename) as f:
for line in f:
line=line.strip('\n')
x.append( int(line.split()[index]))
return x
if __name__ == '__main__':
user_cmd_list,user_cmd_dist_max,user_cmd_dist_min=load_user_cmd("../data/MasqueradeDat/User3")
print(len(user_cmd_list), len(user_cmd_dist_max), len(user_cmd_dist_min))
user_cmd_feature=get_user_cmd_feature(user_cmd_list,user_cmd_dist_max,user_cmd_dist_min)
#从0开始,2为第三个用户即user3的label
labels=get_label("../data/MasqueradeDat/label.txt",2)
'''
每个日志包含 15000条操作命令,前5000条正常,后10000条包含异常操作
数据集中每100条为1个操作序列,因前5000条正常,故前50个都是正常用户的操作序列
从而label.txt中只有后100个序列的标签,对应后10000条可能包含异常操作
'''
y=[0]*50+labels
x_train=user_cmd_feature[0:N]
y_train=y[0:N]
x_test=user_cmd_feature[N:150]
y_test=y[N:150]
neigh = KNeighborsClassifier(n_neighbors=3)
neigh.fit(x_train, y_train)
y_predict=neigh.predict(x_test)
score=np.mean(y_test==y_predict)*100
print("y_test:", len(y_test))
print(y_test)
print("y_predict:", len(y_predict))
print(y_predict)
print("score:",score)
print(classification_report(y_test, y_predict))
print(metrics.confusion_matrix(y_test, y_predict))
本例应该可以作为机器学习的一个样例,参考了最频繁和最不频繁操作命令

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











