







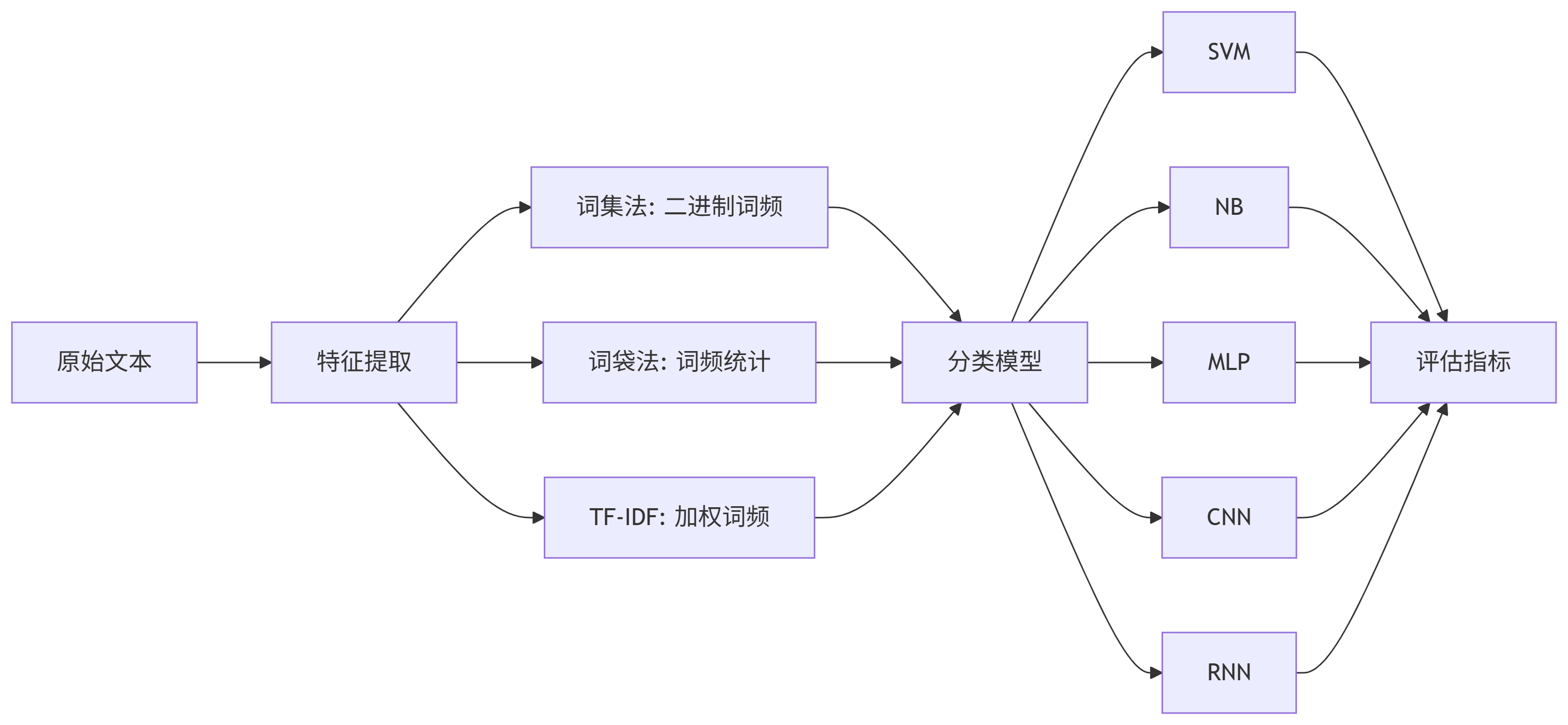
 本篇博客介绍了使用Enron-Spam数据集进行垃圾邮件识别的方法,包括词汇表模型、词袋模型、TF-IDF模型的特征提取,以及SVM、NB、MLP、CNN和RNN等机器学习算法的应用。实验对比了不同max_features数量对识别效果的影响,总结了各种方法在垃圾邮件识别中的应用。
本篇博客介绍了使用Enron-Spam数据集进行垃圾邮件识别的方法,包括词汇表模型、词袋模型、TF-IDF模型的特征提取,以及SVM、NB、MLP、CNN和RNN等机器学习算法的应用。实验对比了不同max_features数量对识别效果的影响,总结了各种方法在垃圾邮件识别中的应用。
目录
本小节使用Enron-Spam数据集来识别垃圾邮件,通过多种方法处理数据集,同时使用多种机器学习的方法来识别垃圾邮件。
一、数据集介绍
垃圾邮件对于企业邮箱用户的影响主要是给日常办公和邮箱管理者带来额外负担,尤其是钓鱼邮件更是有可能导致企业遭受巨大损失。根据不完全统计,在高效的反垃圾环境下依旧有80%的用户每周需要耗费10分钟左右的时间处理这些垃圾邮件。对于企业邮件服务商而言,垃圾邮件大量占用网络资源,使得邮件服务器大部分资源都耗费在处理垃圾邮件上,不仅大大浪费资源,甚至可能影响企业正常业务邮件的沟通。
垃圾邮件识别使用的数据集为Enron-Spam数据集,Enron-Spam数据集是目前在电子邮件相关研究中使用最多的公开数据集,其邮件数据是安然公司(Enron Corporation, 原是世界上最大的综合性天然气和电力公司之一,在北美地区是头号天然气和电力批发销售商)150位高级管理人员的往来邮件。这些邮件在安然公司接受美国联邦能源监管委员会调查时被其公布到网上。机器学习领域使用Enron-Spam数据集来研究文档分类、词性标注、垃圾邮件识别等,由于Enron-Spam数据集都是真实环境下的真实邮件,非常具有实际意义。

二、加载数据集
数据集共6个目录

每个目录下有两个文件夹,ham(正常邮件)和spam(垃圾邮件),其中ham被标记为0,spam标记为1,这样做是因为垃圾邮件为识别目的。

源码如下所示
def load_all_files():
ham=[]
spam=[]
for i in range(1,6):
path="../data/mail/enron%d/ham/" % i
print ("Load %s" % path)
ham+=load_files_from_dir(path)
path="../data/mail/enron%d/spam/" % i
print ("Load %s" % path)
spam+=load_files_from_dir(path)
return ham,spam
不过本书中的代码在处理过程中,会经常报错gbk无法识别一些字符,故而大家在处理过程中可以将ham邮件文档或者spam邮件文档转换为utf-8格式,再进行读取即可解决这些报错。
三、特征提取
文本特征提取有两个非常重要的模型:
词集模型:单词构成的集合,集合自然每个元素都只有一个,也即词集中的每个单词都只有一个。
词袋模型:如果一个单词在文档中出现不止一次,并统计其出现的次数(频数)。
词袋是在词集的基础上增加了频率的纬度,词集只关注有和没有,词袋还要关注有单词的频率。
(一)tensorflow 词集模型(词汇表模型)
词袋模型可以很好地表现文本由哪些单词组成,但是却无法表达出单词之间的前后关系,于是人们借鉴了词袋模型的思想,使用生成的词汇表对原有句子按照单词逐个进行编码。TensorFlow默认支持了这种模型:
tflearn.data_utils.VocabularyProcessor(max_document_length,
min_frequency = 0,
vocabulary = None,
tokenizer_fn = None)其中各个参数的含义为:
· max_document_length:,文档的最大长度。如果文本的长度大于最大长度,那么它会被截断,反之则用0填充。
· min_frequency,词频的最小值,出现次数小于最小词频则不会被收录到词表中。
· vocabulary,CategoricalVocabulary对象。
· tokenizer_fn,分词函数。假设有如下句子需要处理:
x_text =[
'i love you',
'me too'
]基于以上句子生成词汇表,并对'i me too'这句话进行编码:
vocab_processor = learn.preprocessing.VocabularyProcessor(max_document_length)
vocab_processor.fit(x_text)
print next(vocab_processor.transform(['i me too'])).tolist()
x = np.array(list(vocab_processor.fit_transform(x_text)))
print(x)运行程序,x_text使用词汇表编码后的数据为:
[[1 2 3 0]
[4 5 0 0]]完整示意图如下所示

在本例中,获取完ham和spam数据后,通过VocabularyProcessor函数对数据集进行处理,获取词汇表,并按照定义的最大文本长度进行截断处理,没有达到最大文本长度的使用0填充,具体源码如下所示
def get_features_by_tf():
global max_document_length
x=[]
y=[]
ham, spam=load_all_files()
x=ham+spam
y=[0]*len(ham)+[1]*len(spam)
vp=tflearn.data_utils.VocabularyProcessor(max_document_length=max_document_length,
min_frequency=0,
vocabulary=None,
tokenizer_fn=None)
x=vp.fit_transform(x, unused_y=None)
x=np.array(list(x))
return x,y(二)词袋模型(Bag of Word)
词袋模型(英语全称:Bag-of-words model)是个在自然语言处理和信息检索(IR)下被简化的表达模型。此模型下,一段文本(比如一个句子或是一个文档)可以用一个装着这些词的袋子来表示,这种表示方式不考虑文法以及词的顺序。可以通过调用 scikit-learn 的 CountVectorizer 类来进行文本的词频统计与向量化。
from sklearn.feature_extraction.text import CountVectorizer
vectorizer=CountVectorizer()CountVectorize函数比较重要的几个参数为:
·decode_error,处理解码失败的方式,分为“strict”“ignore”“replace”3种方式。
·strip_accents,在预处理步骤中移除重音的方式。
·max_features,词袋特征个数的最大值。
·stop_words,判断word结束的方式。
·max_df,df最大值。
·min_df,df最小值。
·binary,默认为False,当与TF-IDF结合使用时需要设置为True。以本文为例,垃圾邮件为x,代码如下所实话
x=ham+spam
本例中处理的数据集均为英文,所以针对decode_error直接忽略,使用ignore方式,stop_words的方式使用english,strip_accents方式为ascii方式,如下为定义词袋模式的源码
vectorizer = CountVectorizer(binary=False,
decode_error='ignore',
strip_accents='ascii',
max_features=max_features,
stop_words='english',
max_df=1.0,
min_df=1 )在使用过程中,可通过 fit_transform 函数计算各个词语出现的次数。
x=vectorizer.fit_transform(x)返回文档中的词对应的词向量矩阵
x=x.toarray()完整的处理源码如下所示
def get_features_by_wordbag():
ham, spam=load_all_files()
x=ham+spam
y=[0]*len(ham)+[1]*len(spam)
vectorizer = CountVectorizer(
decode_error='ignore',
strip_accents='ascii',
max_features=max_features,
stop_words='english',
max_df=1.0,
min_df=1 )
print (vectorizer)
x=vectorizer.fit_transform(x)
x=x.toarray()
return x,y(三)TF-IDF模型
TF-IDF的主要思想是,根据某个词或短语在一篇文章中出现的频率即词频(Term Frequency,TF),如果词频高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF实际上是:TF×IDF。TF表示词条在文档d中出现的频率。 逆向文件频率(inverse document frequency,IDF)的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。如果某一类文档C中包含词条t的文档数为m,而其他类包含t的文档总数为k,显然所有包含t的文档数n=m+k,当m大的时候,n也大,按照IDF公式得到的IDF的值会小,就说明该词条t类别区分能力不强。但是实际上,如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别于其他类文档。
在Scikit-Learn中实现了TF-IDF算法,实例化TfidfTransformer即可:
transformer = TfidfTransformer(smooth_idf=False)TF-IDF模型通常和词袋模型配合使用,对词袋模型生成的数组进一步处理。在本例中,获取完ham和spam数据后,使用词袋模型CountVectorizer进行词袋化,其中binary参数需要设置为True,然后再使用TfidfTransformer计算TF-IDF:
def get_features_by_wordbag_tfidf():
ham, spam=load_all_files()
x=ham+spam
y=[0]*len(ham)+[1]*len(spam)
vectorizer = CountVectorizer(binary=False,
decode_error='ignore',
strip_accents='ascii',
max_features=max_features,
stop_words='english',
max_df=1.0,
min_df=1 )
x=vectorizer.fit_transform(x)
x=x.toarray()
transformer = TfidfTransformer(smooth_idf=False)
tfidf = transformer.fit_transform(x)
x = tfidf.toarray()
return x,y四、SVM算法识别垃圾邮件
def do_svm_wordbag(x_train, x_test, y_train, y_test):
print ("SVM and wordbag")
clf = svm.SVC()
clf.fit(x_train, y_train)
y_pred = clf.predict(x_test)
print (metrics.accuracy_score(y_test, y_pred))
print (metrics.confusion_matrix(y_test, y_pred))
五、NB算法识别垃圾邮件
def do_nb_wordbag(x_train, x_test, y_train, y_test):
print ("NB and wordbag")
gnb = GaussianNB()
gnb.fit(x_train,y_train)
y_pred=gnb.predict(x_test)
print (metrics.accuracy_score(y_test, y_pred))
print (metrics.confusion_matrix(y_test, y_pred))六、MLP算法识别垃圾邮件
def do_dnn_wordbag(x_train, x_test, y_train, y_testY):
print ("DNN and wordbag")
# Building deep neural network
clf = MLPClassifier(solver='lbfgs',
alpha=1e-5,
hidden_layer_sizes = (5, 2),
random_state = 1)
print ( clf)
clf.fit(x_train, y_train)
y_pred = clf.predict(x_test)
print (metrics.accuracy_score(y_test, y_pred))
print (metrics.confusion_matrix(y_test, y_pred))
七、CNN算法识别垃圾邮件
def do_cnn_wordbag(trainX, testX, trainY, testY):
global max_document_length
print ("CNN and tf")
trainX = pad_sequences(trainX, maxlen=max_document_length, value=0.)
testX = pad_sequences(testX, maxlen=max_document_length, value=0.)
# Converting labels to binary vectors
trainY = to_categorical(trainY, nb_classes=2)
testY = to_categorical(testY, nb_classes=2)
# Building convolutional network
network = input_data(shape=[None,max_document_length], name='input')
network = tflearn.embedding(network, input_dim=1000000, output_dim=128)
branch1 = conv_1d(network, 128, 3, padding='valid', activation='relu', regularizer="L2")
branch2 = conv_1d(network, 128, 4, padding='valid', activation='relu', regularizer="L2")
branch3 = conv_1d(network, 128, 5, padding='valid', activation='relu', regularizer="L2")
network = merge([branch1, branch2, branch3], mode='concat', axis=1)
network = tf.expand_dims(network, 2)
network = global_max_pool(network)
network = dropout(network, 0.8)
network = fully_connected(network, 2, activation='softmax')
network = regression(network, optimizer='adam', learning_rate=0.001,
loss='categorical_crossentropy', name='target')
# Training
model = tflearn.DNN(network, tensorboard_verbose=0)
model.fit(trainX, trainY,
n_epoch=5, shuffle=True, validation_set=(testX, testY),
show_metric=True, batch_size=100,run_id="spam")
八、RNN算法识别垃圾邮件
def do_rnn_wordbag(trainX, testX, trainY, testY):
global max_document_length
print ("RNN and wordbag")
trainX = pad_sequences(trainX, maxlen=max_document_length, value=0.)
testX = pad_sequences(testX, maxlen=max_document_length, value=0.)
# Converting labels to binary vectors
trainY = to_categorical(trainY, nb_classes=2)
testY = to_categorical(testY, nb_classes=2)
# Network building
net = tflearn.input_data([None, max_document_length])
net = tflearn.embedding(net, input_dim=10240000, output_dim=128)
net = tflearn.lstm(net, 128, dropout=0.8)
net = tflearn.fully_connected(net, 2, activation='softmax')
net = tflearn.regression(net, optimizer='adam', learning_rate=0.001,
loss='categorical_crossentropy')
# Training
model = tflearn.DNN(net, tensorboard_verbose=0)
model.fit(trainX, trainY, validation_set=(testX, testY), show_metric=True,
batch_size=10,run_id="spm-run",n_epoch=5)
九、max-feature数量对比
def show_diffrent_max_features():
global max_features
a=[]
b=[]
for i in range(1000,20000,2000):
max_features=i
print ("max_features=%d" % i)
x, y = get_features_by_wordbag()
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.4, random_state=0)
gnb = GaussianNB()
gnb.fit(x_train, y_train)
y_pred = gnb.predict(x_test)
score=metrics.accuracy_score(y_test, y_pred)
print(score)
a.append(max_features)
b.append(score)
plt.plot(a, b, 'r')
plt.xlabel("max_features")
plt.ylabel("metrics.accuracy_score")
plt.title("metrics.accuracy_score VS max_features")
plt.legend()
plt.show()运行结果如下所示

十、总结
本章以Enron-Spam数据集为训练和测试数据集,介绍了常见的垃圾邮件识别方法,介绍了3种特征提取方式,分别是词汇表模型(词集)、词袋模型、TF-IDF模型,其中词汇表模型后来发展成了word2ver模型,这将在后面章节具体介绍。



















 2156
2156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











