








系列目录
《Web安全之机器学习入门》笔记:第十二章 12.2 隐式马尔可夫
《Web安全之机器学习入门》笔记:第十二章 12.3 隐式马尔可夫算法识别XSS攻击(一)
《Web安全之机器学习入门》笔记:第十二章 12.4 隐式马尔可夫算法识别XSS攻击(二)
《Web安全之机器学习入门》笔记:第十二章 12.5 隐式马尔可夫算法识别DGA域名
目录
本小节详细讲解隐式马尔可夫法识别DGA域名。
一、DGA域名
DGA 域名是指通过特定的算法动态生成的域名,这些算法通常基于时间、计数器或其他随机因素。恶意软件利用 DGA 域名来定期生成大量的域名,其中只有少数几个域名会被用于实际的恶意通信,而其他域名则作为诱饵或备用,增加了检测和防范的难度。DGA的域名相对于正常域名具有如下特点。
- 无明显语义:DGA 域名通常由随机的字符组合而成,没有明显的语义或与合法网站相关的含义。它们可能包含看似无意义的字母、数字和符号的混合,例如 “xzyz234klm.com”,很难通过直观的方式判断其用途或归属。
- 字符组合规律:虽然 DGA 域名看似随机,但在字符组合上可能存在一定的规律。一些 DGA 算法会按照特定的模式生成字符序列,例如固定的长度、特定字符集的使用频率等。例如,某些 DGA 域名可能总是由 8 个字符组成,其中包含特定比例的数字和字母。
- 动态生成:DGA 域名是根据一定的算法动态生成的,而不是像正常域名那样事先注册并长期固定使用。这意味着恶意软件可以在不同的时间点生成不同的域名,使得基于静态黑名单的检测方法难以奏效。例如,某个恶意软件可能每天生成 100 个新的 DGA 域名,只有当天的特定几个域名会被用于与控制服务器通信。
- 与恶意软件关联:DGA 域名主要被恶意软件用于恶意目的,如命令与控制(C2)通信、数据窃取或传播恶意软件等。它们通常与特定的恶意软件家族相关联,不同的恶意软件可能使用不同的 DGA 算法来生成域名,以实现对感染主机的控制和管理。
- 注册和解析行为异常:DGA 域名的注册和解析行为往往与正常域名不同。它们可能在短时间内大量注册,且注册信息可能不完整或虚假。在解析方面,DGA 域名可能会频繁地解析到不同的 IP 地址,或者解析到一些与合法服务无关的 IP 地址,这些异常行为可以作为检测 DGA 域名的重要线索。
二、马尔可夫算法识别DGA原理
马尔可夫算法识别 DGA 的原理基于正常域名与 DGA 域名在字符序列特征上的差异。正常域名的字符分布和转移具有一定规律,如特定字符间的转移概率相对稳定 ,语义上也有连贯性。而 DGA 域名由算法随机生成,字符组合常无实际意义,字符转移概率分布特殊。马尔可夫算法通过分析大量正常域名和 DGA 域名样本,学习各自字符间的转移概率,构建不同的转移概率矩阵。当检测未知域名时,依据马尔可夫模型计算其字符序列出现的概率,对比预设阈值,判断其属于正常域名还是 DGA 域名。基于如上原理,通常使用马尔可夫识别DGA域名的步骤如下所示。
- 特征提取:对于待识别的域名,将其转换为字符序列,并按照训练模型时的字符编码方式进行编码。
- 计算概率:根据马尔可夫模型,计算该域名字符序列出现的概率。从域名的第一个字符开始,根据初始状态概率分布和转移概率矩阵,依次计算每个字符出现的概率,最终得到整个域名序列的概率。
- 判断类别:将计算得到的概率与设定的阈值进行比较。如果概率大于阈值,则判定该域名为 DGA 域名;否则,判定为正常域名。阈值的选择可以根据实际需求和模型的性能进行调整,通常通过在测试集上进行实验来确定最佳阈值,以平衡准确率和召回率。
三、马尔可夫算法识别DGA域名
在9.4节通过SVM算法识别DGA域名中,其中使用了HMM特征。接下来通过代码来实现马尔可夫识别DGA域名。
1、白名单
def load_alexa(filename):
domain_list=[]
csv_reader = csv.reader(open(filename))
for row in csv_reader:
domain=row[1]
if len(domain) >= MIN_LEN:
domain_list.append(domain)
return domain_list
domain_list = load_alexa("../data/top-1000.csv")2、训练hmm模型
首先通过正常的域名训练hmm,代码如下所示,为了节省训练,如果存在训练好的模型,则是直接load训练好的模型即可。
def train_hmm(domain_list):
X = [[0]]
X_lens = [1]
for domain in domain_list:
ver=domain2ver(domain)
np_ver = np.array(ver)
X=np.concatenate([X,np_ver])
X_lens.append(len(np_ver))
remodel = hmm.GaussianHMM(n_components=N, covariance_type="full", n_iter=100)
remodel.fit(X,X_lens)
joblib.dump(remodel, FILE_MODEL)
return remodel
if not os.path.exists(FILE_MODEL):
remodel=train_hmm(domain_list)
remodel=joblib.load(FILE_MODEL)3、验证HMM模型
def test_dga(remodel,filename):
x=[]
y=[]
dga_cryptolocke_list = load_dga(filename)
for domain in dga_cryptolocke_list:
domain_ver=domain2ver(domain)
np_ver = np.array(domain_ver)
pro = remodel.score(np_ver)
#print "SCORE:(%d) DOMAIN:(%s) " % (pro, domain)
x.append(len(domain))
y.append(pro)
return x,y
def test_alexa(remodel,filename):
x=[]
y=[]
alexa_list = load_alexa(filename)
for domain in alexa_list:
domain_ver=domain2ver(domain)
np_ver = np.array(domain_ver)
pro = remodel.score(np_ver)
#print "SCORE:(%d) DOMAIN:(%s) " % (pro, domain)
x.append(len(domain))
y.append(pro)
return x, y
x_3,y_3=test_dga(remodel, "../data/dga-post-tovar-goz-1000.txt")
x_2,y_2=test_dga(remodel,"../data/dga-cryptolocke-1000.txt")
x_1,y_1=test_alexa(remodel, "../data/test-top-1000.csv")4、可视化HMM
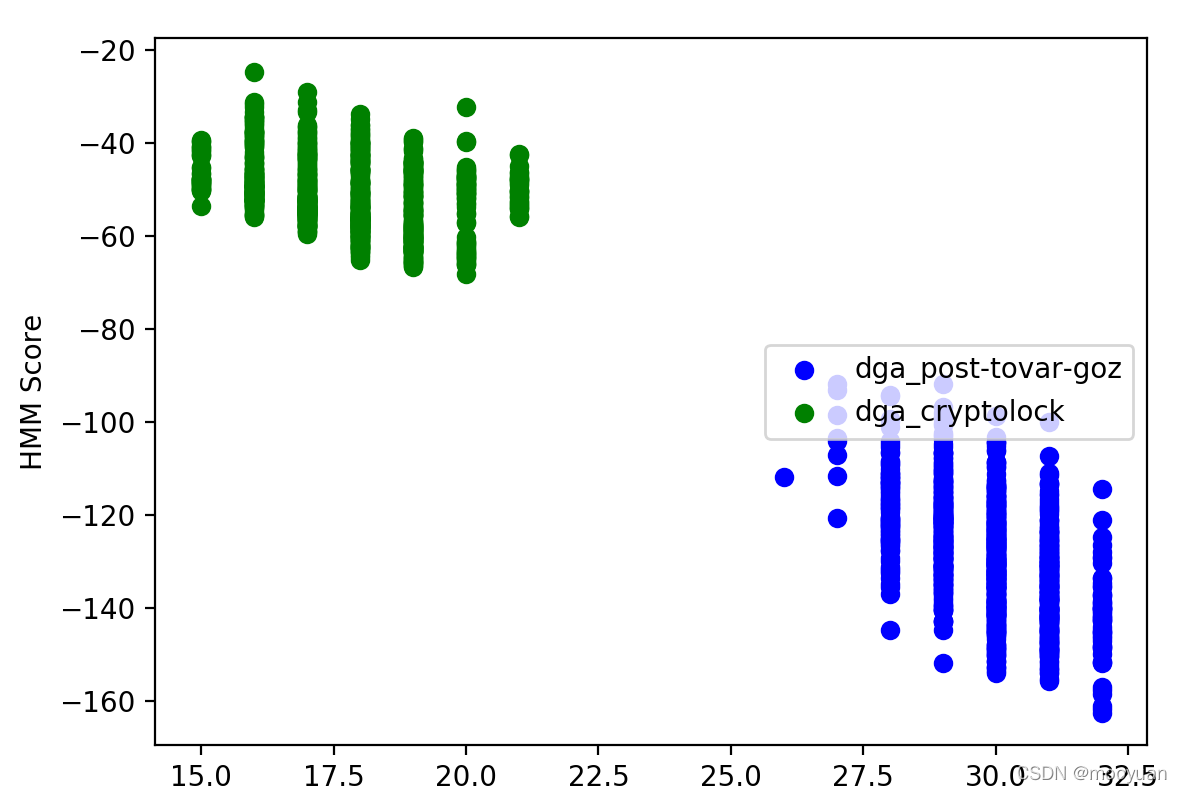
计算两类僵尸网络(蓝色和绿色)的HMM, 以域名长度为横轴,HMM分数为纵轴作图,并图形展示的源码处理。
fig,ax=plt.subplots()
ax.set_xlabel('Domain Length')
ax.set_ylabel('HMM Score')
ax.scatter(x_3,y_3,color='b',label="dga_post-tovar-goz")
ax.scatter(x_2, y_2, color='g', label="dga_cryptolock")
#ax.scatter(x_1, y_1, color='r', label="alexa")
ax.legend(loc='right')
plt.show()可视化运行结果如下:




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











