







在数组里面不同的排序方法的具体操作不同,数组里每一时刻的元素排布也不同。稍微尝试了使用图像的方式来呈现数组排序过程中数据的走向,发现效果还不赖。如果之前有雷同的,纯属巧合。作者学术造诣还不高,文章中难免有一些说法或理论不标准甚至错误的地方,欢迎评论指出。同时如果读这篇文章的人可以把这文章当成娱乐向文章来轻松快乐地阅读,作者会很开心的。
操作说明
把一个数组中每一个元素转化成一个RGB色,把一个个RGB色按下标顺序顺接从左往右排成一行像素就是这个数组在图像上的映射。(如下图的ArrayView)
经过一些程序指令后,这个数组的元素排列会出现变化,那么这时这个数组对应的图像映射也有些许差异。我们把这行新像素接在上一行像素的下面,再重复操作,就可以得到下面的一张数组排序过程的图像映射。(如下图的ArrayScan)
下图为冒泡排序图像的说明:
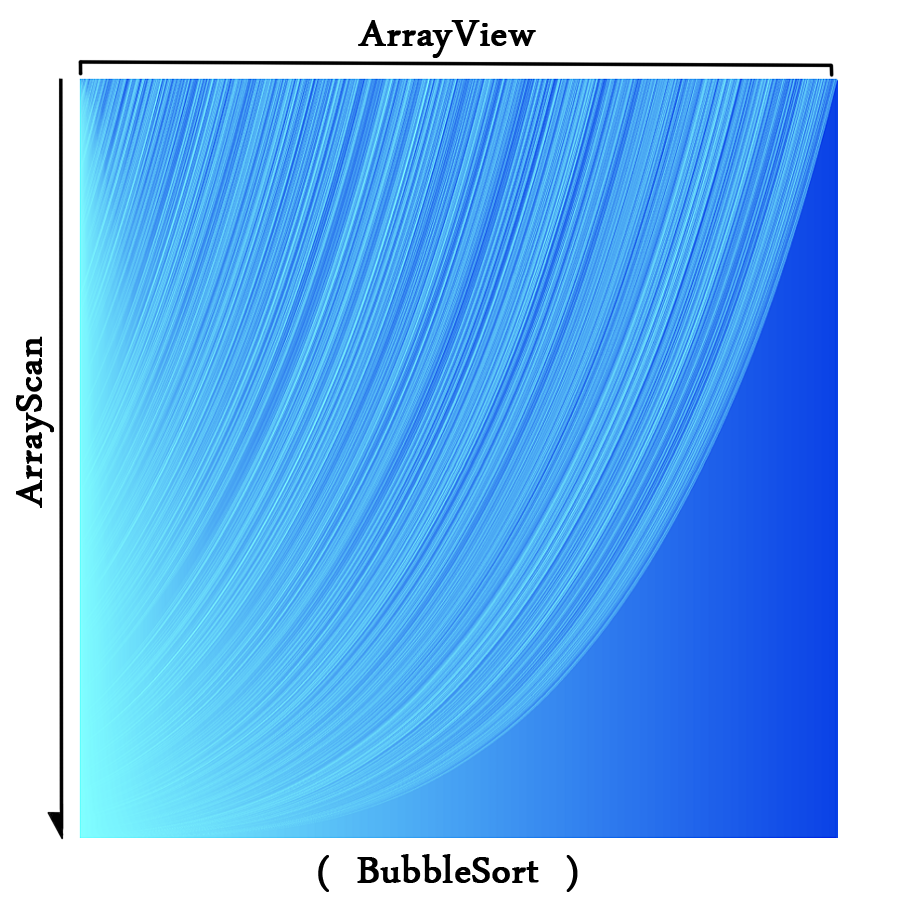
在这类图像中,两个值对应的两个像素的颜色的相近度反映了这两个元素在值上的相近度。两个像素色差越大说明值相差越大,反之越小。
如下图是数组有序的情况下连续映射若干行的图像:

而这幅图是数组乱序的情况下连续映射若干行的图像:

看来,使用此类图像可以较为清晰地看出数组内不同数据分布情况的变化。
实例展示
冒泡排序
映射图像:(打印频率:500)

说实话,与其说数据像泡泡一样冒上去,我更觉得更有是未有序的部分在一点一点向下沉。同时可看出未排序部分刚开始“沉”得比较慢,后来“沉”得越来越快,说明了使每一个元素“冒”上来的时间在逐渐减少。
排序代码:
public static void bubbleSort(int arr[]){
for(int i=0;i<arr.length;++i){
for(int j=1;j<arr.length-i;++j){
//交换相邻两个不连续的元素
if(arr[j]<arr[j-1]){
//**主要耗时段
int temp=arr[j];
arr[j]=arr[j-1];
arr[j-1]=temp;
}
}
}
}在本文章中如果没有特殊说明,待排序数组的长度都为2048。同时看到代码“**主要耗时段”的注释,说明这部分的运行次数很大部分地决定了程序的运行时间。这篇文章所有的映射图每一行都是在主要耗时段代码块运行一次后添加的,也就是说,打印代码放在主要耗时块内。有时可能该代码块运行次数较多,图片会拉得很长,不便于观察,作者会改为适当确定次数执行后才添加一行(如图片前标注的打印频率)。如果把打印的代码放在第一层循环块中,那么未排序部分与已排序部分的交界线将是一条直线。难道冒泡排序开始时的冒泡完成速度与最后的冒泡完成速度是一样的吗?不是的,冒泡到后面无序的元素变少,冒泡速度是变快的,这样绘图不能很好地展现运行时间的因素对改变数据分布的作用。把打印代码放在主要耗时段可以使图像更贴近直观地显示数据分布与运行时间的关系。
选择排序
映射图像:(打印频率:500)

排序代码:
public static void selectionSort(int arr[]){
for(int i=0;i<arr.length;++i){
//index为未排序段中的最小元素下标
int index=arr.length-1;
for(int j=i;j<arr.length;++j){
//标记当前最小元素
if(arr[j]<arr[index]){
//**主要耗时段
index=j;
}
}
//把最小元素交换到已排序段
int temp=arr[i];
arr[i]=arr[index];
arr[index]=temp;
}
}插入排序
映射图像:(打印频率:500)

排序代码:
public static void insertionSort(int arr[]){
for(int i=1;i<arr.length;++i){
//temp为要插入的数据
int temp=arr[i],
j=i-1;
//把temp前的大于temp的元素都向后挪
//留出空位
while(j>=0 && arr[j]>temp){
//**主要耗时段
arr[j+1]=arr[j];
--j;
}
//把temp放进空位
arr[j+1]=temp;
}
}通过观察可以发现,冒泡排序、选择排序与插入排序这种具有两层循环的排序过程映射的图像中,未排序部分与已排序部分的交界线好像是抛物线形状。这是可以证明的:在冒泡排序中和选择排序中,第二层循环的循环次数与该次第一次循环的i值是成线性关系的,即已排序数据数量与第二层循环的次数是成线性关系的。所以交界线的斜率与时间成线性关系,根据导数可得交界线的形状是二次函数曲线,即抛物线。
而在插入排序中,第二层循环的循环次数虽然是不一定的,但是区间范围在0~i之间,范围长度与i成线性关系。同理可得插入排序未排序部分与已排序不分的交界线上每一点的回归曲线为抛物线。我们可以看到交界线是不平滑的,这是因为对于数值的大小不同的待插入数据,需要的插入时间不同。
快速排序
快速排序的思想是选定一个标准后根据这个基准点分堆,然后递归。
下图是将打印语句直接放在递归体最外一层(非主要耗时块)时的映射图像:(打印频率:1)

我们可以看到数据被“分”成了一个个颜色更相近的“无序块”,然后在这个无序块里面继续分颜色更相近的,直到整个数组有序。
而有关快速排序分堆的具体实现方法有两种。我们把标记已经把堆分到的位置的变量暂时称呼为分堆指针,那么对于快速排序,要分成两个堆:一个堆内的与元素都小于(或小于等于)基准;一个堆内的元素都大于等于(或大于)基准。因此在主流上需要两个分堆指针。而在不同的实现方法里,这两个分堆指针运动的方向是不同的:
分堆指针向同一方向移动的情况
将打印语句放在分堆时遍历数据的程序块(主要耗时块)中的映射图像:(打印频率:8)

排序代码:
public static void quickSort1(int arr[],int left,int right){
//只有一个元素则不用分堆
if(left>=right){
return;
}
//把最左端的元素定位基准
//i为分小于基准的堆的指针
//j为分大于等于基准的堆的指针
int point=arr[left],
j=left+1,
i=left;
//j先行遍历整个数组
for(;j<=right;++j){
//**主要耗时段
//j指针遇到了小于基准的点
if(arr[j]<point){
//与i指针后的大于等于基准的元素调换并把i指向交换后的元素
++i;
int temp=arr[j];
arr[j]=arr[i];
arr[i]=temp;
}
}
//把基准点与i指针位置元素调换
arr[left]=arr[i];
arr[i]=point;
//分治
quickSort1(arr,left,i-1);
quickSort1(arr,i+1,right);
}分堆指针从两端出发向中间靠拢的情况
将打印语句放在分堆时寻找数据的程序块(主要耗时块)中的映射图像:(打印频率:8)

排序代码:
public static void quickSort2(int arr[],int left,int right){
//只有一个元素则不用分堆
if(left>=right){
return;
}
//把最左端的元素定位基准
//i为分小于基准的堆的指针
//j为分大于等于基准的堆的指针
int point=arr[left],
i=left,
j=right;
//指针从两端开始向中间趋近
while(i<j){
//j遇到比基准小的则停下
while(arr[j]>=point && i<j)
--j; //**主要耗时段
//与i所指的调换且把i向中间推
if(i<j)
arr[i++]=arr[j];
//i遇到不比基准小的则停下
while(arr[i]<=point && i<j)
++i; //**主要耗时段
//与j所指的调换且把j向中间推
if(i<j)
arr[j--]=arr[i];
}
//把基准移到中间
arr[i]=point;
//分治
quickSort2(arr,left,i-1);
quickSort2(arr,i+1,right);
}两种情况只是细节上的不同,而在运算量/内存使用上是大同小异的。我们可以关注一下打印频率:在数组长度都为2048的情况下,快速排序的两个图像高度都与冒泡排序、选择排序和插入排序差不多,可快速排序的打印频率是8,后三者两层循环类型的排序方法的打印频率却高达500。这说明了快速排序的平均运算量远远低于后三者,效率更高。这一点作者在生成图片时就可以感受到:快速排序基本都是五秒内就把图片生成出来了,而后三者我去喝杯茶回来再等等才生成出来,不得不感叹良好算法的重要性。
归并排序
归并的思想是把N个有序的子数组归并成一个有序的数组。这里只讨论二路归并,其他都是一通百通的。
二路归并算法代码:
public static void merge(int arr[],int left,int point,int right){
//复制数组片段
int leftArr[]=new int[point-left+1];
int rightArr[]=new int[right-point];
int i=left,
j=point+1,
p=i-1;
for(int k=0;k<leftArr.length;++k){
leftArr[k]=arr[i+k];
}
for(int k=0;k<rightArr.length;++k){
rightArr[k]=arr[j+k];
}
//归并至其中一个子数组为空
i=0;j=0;
while(i<leftArr.length && j<rightArr.length){
//**主要耗时段
if(leftArr[i]<rightArr[j]){
arr[++p]=leftArr[i++];
}else{
arr[++p]=rightArr[j++];
}
}
//把两个子数组中一个子数组多出来的元素归入
while(i<leftArr.length){
//**主要耗时段
arr[++p]=leftArr[i++];
}
while(j<rightArr.length){
//**主要耗时段
arr[++p]=rightArr[j++];
}
}而归并排序的具体实现方法有两种。一种是通过递归实现的,我们把它叫做深度优先归并;另一种是通过队列或循环实现的,我们把它叫做广度优先归并。
深度优先归并
深度优先归并是通过分治递归来运作的。也就是说,要先归并这一部分,必须先把这一部分的两个子数组归并好。
映射图像:(打印频率:10)

排序代码:
public static void mergeSortD(int arr[],int left,int right){
//只有一个元素时数组必为有序的
if(right-left<1)
return;
//分治 在两个子数组中完成各自的归并
final int point=(left+right)/2;
mergeSortD(arr,left,point);
mergeSortD(arr,point+1,right);
//归并两个子数组
merge(arr,left,point,right);
}广度优先归并
广度优先归并的思想是归并序列长度优先。也就是说,先把数组内所有元素两两归并成长度为2的子序列,再把所有这些子序列两两归并成长度为4的……以此类推。
映射图像:(打印频率:10)

排序代码:
public static void mergeSortB(int arr[]){
//n为归并的长度
int n=1;
//不断二路归并至整个数组被归并
while(n<arr.length){
n*=2;
//以n为单位归并两个子数组
int i;
for(i=0;i+n-1<arr.length;i+=n){
merge(arr,i,i+(n/2)-1,i+n-1);
}
//后面多出来的部分如果需要归并则归并
if(arr.length-i>n/2){
merge(arr,i,i+(n/2)-1,arr.length-1);
}
}
}其实有时候说到递归,我就会想到分形。这个想法很好地在归并算法中得到了验证。如果这个数组的长度是无限的,那这个伪分形该有多壮观。
堆排序
映射图像:(打印频率:10)

图像的上面部分是建堆的过程,下面是维护堆的过程。至于为什么建堆用的时间比较短,我是这样理解的:初始时数组为乱序,新入堆的元素去到的堆深度是不确定的;而维护堆的时候从尾部调到堆顶的元素是原来在堆底的,难免要调回堆中较为底部的部分,所以用的时间就长了。
至于已排序的部分与堆底的分界线的形状,作者认为其分界线上的每一点的回归曲线大约是f(x)=(1/ln2)(xlnx-x)+C图像的形状(对对数求积分)。假设每一个从堆底调到堆顶的元素都调到堆的最底一层,那么经过的堆深度是以2为底数、以这时堆长度为真数的对数函数关系(需要取整)。
排序代码:
public static void heapSort(int arr[]){
//建最大堆
for(int i=1;i<arr.length;++i){
int father=(i-1)/2,
son=i;
while(arr[father]<arr[son] && son>0){
//**主要耗时段
int temp=arr[father];
arr[father]=arr[son];
arr[son]=temp;
son=father;
father=(son-1)/2;
}
}
//排序
int length=arr.length-1;
while(length>0){
//把堆顶元素移动到堆尾
int temp=arr[length];
arr[length]=arr[0];
arr[0]=temp;
//在堆中删除移动到堆尾的元素
--length;
//维护堆
int index=0,son;
while(index*2+1<=length){
//**主要耗时段
son=index*2+1;
if(son<length && arr[son+1]>arr[son])
++son;
if(arr[index]>=arr[son])
break;
int temp1=arr[index];
arr[index]=arr[son];
arr[son]=temp1;
index=son;
}
}
}希尔排序
映射图像:(打印频率:10)
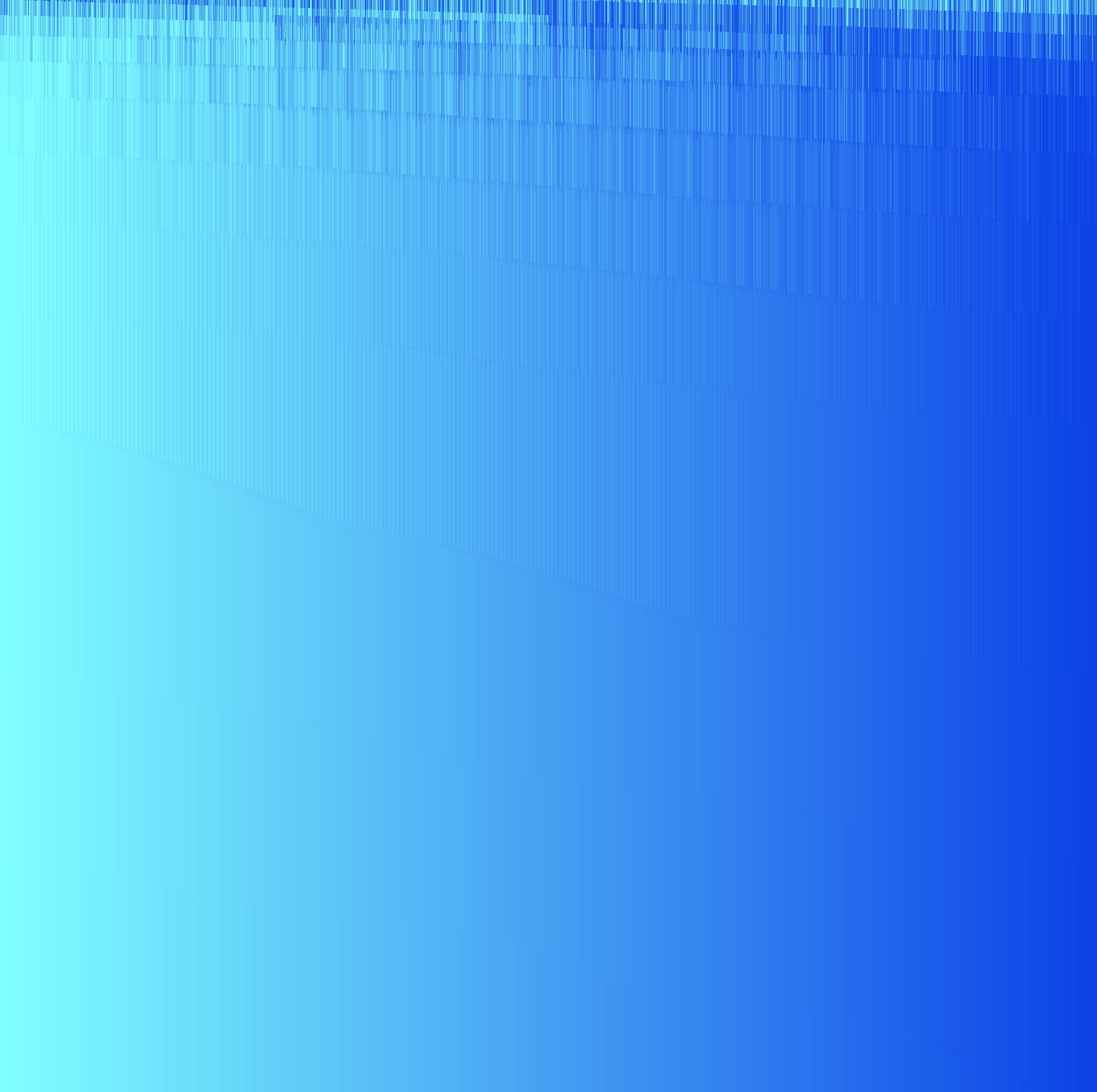
我们看到希尔排序刚开始高跨度时的插入排序速度很快,但是到后面就慢下来了。作者认为这是因为高跨度时要进行插入排序的子序列长度较小,速度比较快。插入排序的时间复杂度是O(n^2),在每一步的插入排序中,子序列的长度变为原来的两倍,那么用时约是原来的四倍;而子序列的个数却是原来的二分之一,故每步的用时在理论上都是上一次的两倍。不过越到后面子序列越趋于有序,时间达不到原来的两倍。
同时我们可以发现希尔排序可以很快地把随机数组转化为较为有序的数组,这可以说是希尔排序的一大优点。
排序代码
public static void shellSort(int arr[]){
//gap为调换跨度
for(int gap=arr.length/2;gap>0;gap/=2)
//插入排序
for(int i=gap;i<arr.length;++i)
for(int j=i-gap;j>=0 && arr[j]>arr[j+gap];j-=gap){
//**主要耗时段
int temp=arr[j];
arr[j]=arr[j+gap];
arr[j+gap]=temp;
}
}随机排序
随机排序可以说是程序界的一大玩笑,但是它对数组的随机化很有用。下面展示对随机数组的随机排序以及对有序数组的随机化两个过程的映射图。
对随机数组的随机排序的映射图像:(打印频率:1)

对有序数组的随机化的映射图像:(打印频率:1)

排序代码:
public static void randomSort(int arr[],int times){
//按照调换次数调换
for(int i=0;i<times;++i){
//**主要耗时段
//随机获取两个不同的数组下标
int index1,index2;
do{
index1=(int)Math.floor(arr.length*Math.random());
index2=(int)Math.floor(arr.length*Math.random());
}while(index1==index2 ||
index1>arr.length || index2>arr.length ||
index1<0 || index2<0);
//调换两个随机下标的元素
int temp=arr[index1];
arr[index1]=arr[index2];
arr[index2]=temp;
}
}后记
作者能写出来的排序算法也就这么多了,其他的我还要日后学习才能补全。
关于基数排序和地精排序,基数排序其实类似于快速排序,图像比较相似,这里不做展示;地精排序其实就是插入排序的一个变体,绘制出来的图像与插入排序是一样的,于是没有给出。
总之,美是用来发现的,其实很多时候数学也是一种美。















 47
47

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









