









定义
类别特征:如['male', 'female']等,模型不能直接识别的数据。处理的目的是将不能够定量处理的变量量化。
特别的比如星期[1, 2, ... , 7]虽然是数字,但是数值之间没有大小顺序关系,需要视为类别特征。
处理
编码为模型可识别的数值型特征。
根据模型处理能力的不同,需要考虑单纯映射为数值或哑变量编码。(尤其是线型模型和SVMs with standard kernels, knn?)
sklearn.preprocessing.OneHotEncder
This estimator transforms each categorical feature with m possible values into m binary features, with only one active.
把所有可能取值转换为二进制表示,只含一个一的那种?
结果
- dt, rf, gb, ada等对于缩放,编码等不敏感,结果差异不大
- svr, knn结果缩放有提高,编码还会变差?
pandas.get_dummies
哑变量编码,适用于pd.DataFrame。
功能和OneHot类似,有额外的drop_first功能。
总结
- 哑变量编码对于sklearn中的sklearn模型的意义不大。尤其是基于树模型没有影响。
- 线性模型有影响
- svm影响不大,甚至默认参数时因为特征增加,表现下降
- knn不受影响(knn受冗余特征的影响较大)
为什么无关紧要的特征会损害KNN?
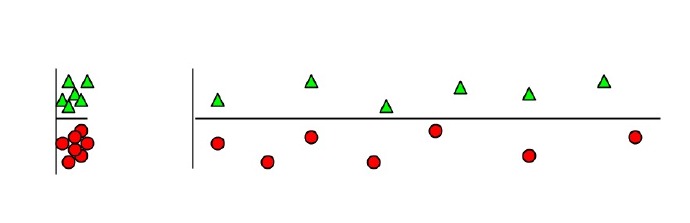
答:如上图,横轴为无关紧要特征,因为横轴特征的出现,将原本鲜明的聚类特征模糊化,纵轴权重被横轴稀释,从而得到错误的聚类结果。















 4795
4795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









