






点击我爱计算机视觉标星,更快获取CVML新技术
本文原载于知乎,作者吴捷,目前于中山大学就读研究生。研究领域为计算机视觉与自然语言处理。

作者不仅综述了时域语言定位(Temporally Language Grounding)相关技术,还开源了多个state-of-the-art的实现,总结了一份资源列表,可谓相关研究者的端午佳节大福利~
开源网址在文末,欢迎去GitHub给大佬加星。
一. 任务概述
"Temporally Language Grounding in Untrimmed Videos"(TLG) 是目前视频理解领域一个新提出的任务,任务要求是给定一句自然语言描述,模型需要在未剪裁的视频中确定该描述的活动发生的时间片段(起始时间,终止时间)。在计算机视觉领域中,动作时序定位(Temporal Activity Localization, TAL )任务与TLG是十分相关的,与TAL 相比,TLG更具挑战性,因为TLG不仅没有预定义的动作列表与标签,而且可能包含复杂的描述。TLG需要模型能够建立语言模态与视觉模态的关系,对多模态特征进行建模,对自然语言和视频内容有深入的理解。
二. 基于监督学习算法的经典模型
TLG任务在2017年ICCV中由两篇经典的论文提出,分别是:TALL(TALL: Temporal Activity Localization via Language Query:https://arxiv.org/abs/1705.02101)与MCN (MCN: Localizing Moments in Video with Natural Language:https://arxiv.org/pdf/1708.01641.pdf)。
2.1 TALL
Gao (TALL)认为虽然可以利用不同尺度上密集采样的滑动窗口来确定正确的时间片段,但这样做不仅计算开销大,而且随着搜索空间的增加,时间片段对齐的难度也逐渐提高。一种替代密集抽样的方法是在预设的时间片段做偏移回归,来调整时间框的大小。Gao提出了跨模态时间回归定位器(CTRL)模型,将句子描述、候选视频片段及其时间上下文信息联合建模,并为候选的视频片段生成对齐的置信度分数和时间窗口的微调结果。它利用C3D模型提取视频片段的视觉特征,利用skip-thought技术提取句子的编码表示。CTRL设计了一个跨模态处理单元,对文本和视觉特征进行联合建模,计算模态间中不同维度元素的加法、乘法和全连接表示。最后,利用卷积层网络进行视觉语义对齐和边界框位置的回归训练。CTRL的损失函数被设计为多任务的损失函数:由对齐损失与时间回归损失构成。对齐损失鼓励对齐的短句对得到正的分数,而对齐错误的短句对得到负的分数;回归损失用于纠正已经对齐的视频片段中的时间偏移。(Our Implementation: TALL:https://github.com/WuJie1010/Temporally-language-grounding/blob/master/model_TALL.py)
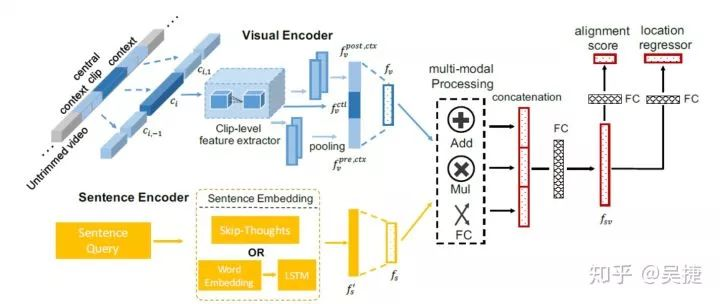
2.2 MCN
为了在视频中对时刻进行定位,Hendrick 提出了一种联合的视频-语言模型,在度量学习的条件下解决这个问题。作者认为,来自相应时刻的句子表示和视频特征在共享嵌入空间应当存在较小的欧氏距离。与整个视频检索相比,除了特定时刻的视频特征外,全局的视频特征和当前的时间框位置是完成该任务的重要线索。例如,对于“舞台上离观众最近的人”的句子描述。“最近”这个词是相对的,需要全局的线索来正确判定。此外,在较长的视频中某一时刻的显性时间位置可以帮助正确定位该时刻。综上所述,Hendrick 提出了一种包含全局视频特性的时刻上下文网络(MCN),它提供了一个全局上下文视频特征和一个显性的时间信息来指示视频发生时间。MCN的损失函数由两部分组成 1)鼓励句子特征更接近于对应的视频时刻,而不是来自同一视频的其他可能视频片段。2)鼓励句子特征更接近于对应的视频时刻,而不是视频之外的时刻。
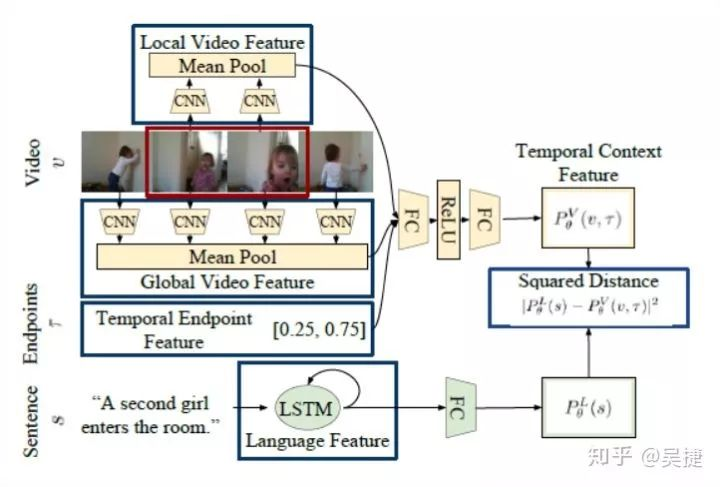
2.3 MAC
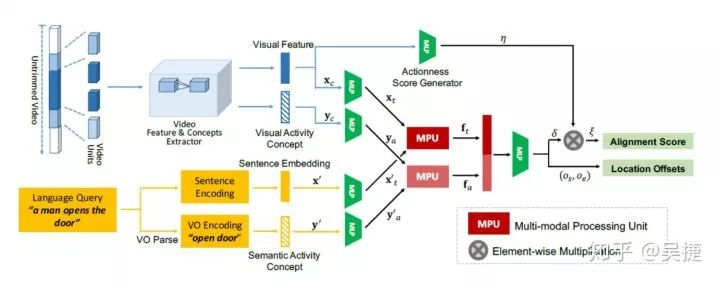
上述两篇文章分别代表了基于监督学习算法在该任务的两种经典方法。他们都首先选择一系列的候选视频片段。接着TALL采用置信度得分以及偏移调整的方法来选择输出的视频片段。MCN通过度量学习的方法,选择在嵌入空间上与对应的句子语义距离最小的视频片段。但他们都忽略了关于视频和句子中活动的丰富的动作概念。MAC (MAC: Mining Activity Concepts for Language-based Temporal Localization:https://arxiv.org/pdf/1811.08925.pdf)设计了一个基于动作表示的时间定位器(ACL),从视频和语言模式中挖掘动作概念。具体来说,为了挖掘句子表示中的动作概念,ACL在句中对verb-obj对中的语义概念进行编码,获得句子中动作概念的嵌入表示;视觉层面的运动概念来自C3D最后的分类层中的不同运动标签的概率分布。 MAC分别处理这对运动概念表示,以及一对视觉特征和句子嵌入(与TALL相同)。 视觉表示-句子表示对 与 视觉动作概念-句子动作概念对 分别送入多模态处理单元,再将输出的串联表示馈送到两层MLP,其输出对齐的置信度得分和回归时间边界。 其损失函数与TALL的损失函数一致。实验结果发现引入这些动作概念有助显著性地提高对齐准确性。(Our Implementation: MAC:https://github.com/WuJie1010/Temporally-language-grounding/blob/master/model_MAC.py)
在监督学习的范畴下,还有一些其他的论文值得关注,分别是:
对视频的前后片段采用关注机制的ACRN (ACRN: Attentive Moment Retrieval in Videos:
https://dl.acm.org/citation.cfm?id=3210003);
实时地捕捉视频和句子之间不断发展的细粒度的交互的TGN(Temporally Grounding Natural Sentence in Video:
https://www.aclweb.org/anthology/papers/D/D18/D18-1015/);
利用多模态的co-atttention机制的ABLR (To Find Where You Talk: Temporal Sentence Localization in Video with Attention Based Location Regression:
https://arxiv.org/abs/1804.07014);
将句子的语义信息结合到视频片段选择的SAP (SAP:Semantic Proposal for Activity Localization in Videos via Sentence Query:
http://www.yugangjiang.info/publication/19AAAI-actionlocalization.pdf);
更早、更紧密地集成了视觉和语言特性的多级模型QSPN(Multilevel Language and Vision Integration for Text-to-Clip Retrieval:
https://arxiv.org/pdf/1804.05113.pdf);
三. 基于强化学习算法的经典模型
近年来,强化学习技术被成功地推广到各种基于图像/视频等人工智能问题中,用于学习特定任务的最优策略。在目标检测任务中,Jie等人提出了一种树形强化学习方法(https://arxiv.org/pdf/1703.02710.pdf),该方法基于历史和当前的观测数据,学习对多个目标进行定位与检测。Yeung等人提出了一种针对TAL任务的end-to-end方法(https://arxiv.org/pdf/1511.06984.pdf),该方法通过强化学习方法直接推理动作的时间片段。Wang等人提出了用于解决视频描述任务的层次化强化学习框架,其中high-level Manager模块用以设置目标,low-level worker 模块按照Manager的目标选择基本动作。
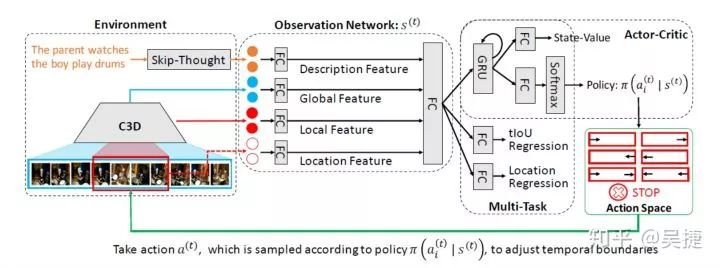
Read,Watch, and Move(https://arxiv.org/pdf/1901.06829.pdf)这篇论文首次将强化学习的算法应用在了TLG任务。论文从人类的感知过程出发,人类在执行这个任务的时候,首先会大概预设一个大致的时间边界,接着对时间边界内的视频片段进行观察后决定边界应该如何移动,然后逐步迭代地调整时间边界,以找到最佳匹配的视频片段。这个过程可以被看做是时间边界逐步调整的序列决策过程。因此,该任务自然地适合RL框架,该论文提出了一种基于end-to-end的强化学习(RL)的视频自然语言描述框架。如下图所示,在每个时间步长中,智能体读取句子描述并查看当前的视频片段,然后根据当前策略选择时间边界的移动行为。该行为会导致环境会相应地更新,并向智能体提供一个表示所选操作执行情况的奖励。
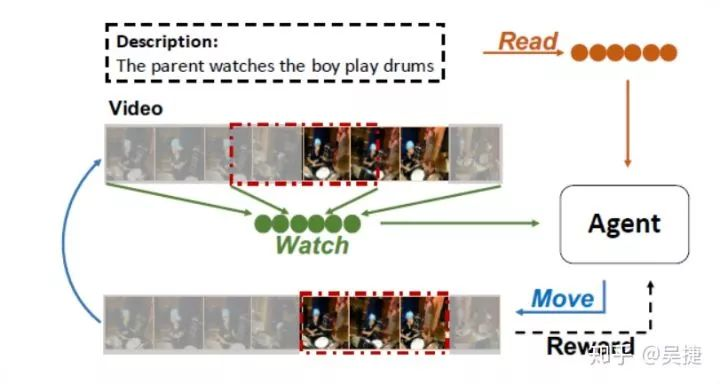
下图显示了所论文说提出的模型的体系结构。动作空间由7种不同的方式来调整时间边界:分别是 起始点/终止点/起始点与终止点 左移;起始点/终止点/起始点与终止点 右移和停止动作。状态向量s(t)融合了描述来自环境的句子编码特征、全局视频特征、局部视频特征和当前位置显性的嵌入特征。该论文只是探究利用强化学习的方法去解决这个问题,没有花力气在特征学习与模型构建上,所以各个模态的特征只是直接用全连接层学习后连接起来,没有引入attention等机制。状态特征被输入到actor-critic算法中学习策略和状态值。actor-critic算法能够减小策略梯度的方差。该模块使用GRU和FC层的来输出策略和状态值。策略决定了行动的概率分布,状态值作为当前奖赏值的估计。论文还引入了多任务的损失函数,利用监督学习对当前视频片段与Ground-truth的IoU进行回归,并对时间定位边界进行回归。(Our Implementation: A2C :https://github.com/WuJie1010/Temporally-language-grounding/blob/master/model_A2C.py)
四. 数据集与评测标准
4.1 数据集:TACoS
TACoS 数据集是来自于MPII Composites dataset,它包含了烹饪领域的不同活动。Regneri等人通过众包扩展了视频片段的自然语言描述。数据集中有127个视频,分为训练集、验证集和测试集,分别包含75、27和25个视频。每个时间片段包含一个句子,以及它在视频中描述的活动的开始和结束时间。训练、验证和测试集视频片段的数量分别为10146条、4589条和4083条。句子平均长度6.2个单词,视频平均时长287.1秒,每个视频平均活动次数21.4次。
https://www.mendeley.com/catalogue/script-data-attributebased-recognition-composite-activities/
4.2 数据集:Charades-STA
Charades-STA数据集建立在Charades数据集的基础上,Gao等人对原本数据集添加了句子描述,使其适合于TLG任务。数据集中有16128个视频-句子对,它们分别被划分为12408对和3720对分别用于训练和测试。句子平均长度8.6个单词,视频平均时长29.8秒,每个视频平均活动次数2.3次。
https://arxiv.org/abs/1705.02101
4.3 数据集:ActivityNet
ActivityNet数据集包含了20k个视频和100k个描述。与TACoS相比,ActivityNet多了两个数量级的视频,包含37421和17505个视频-句子对,分别用于训练和测试。ActivityNet中的视频平均长度为2分钟,描述的视频片段平均为36秒。
https://arxiv.org/abs/1705.00754
4.4 评测标准
TLG任务一般采用两个评测标准来评估模型的性能:1)“R@1, IoU@a”表示正确的时间片段和预测的时间片段的IoU大于a的百分比。2)“MIoU”表示所有预测片段与正确片段的平均IoU。
五. State-of-the-art模型的实现
我们在GitHub上开源了一些最先进模型的实现:
https://github.com/WuJie1010/Temporally-language-grounding
其中包括基于监督学习算法的TALL, MAC 和基于强化学习算法的A2C。欢迎大家去follow与fork。我们也将紧跟这个任务的最新成果,同时更新在GitHub上。
https://github.com/WuJie1010/Awesome-Temporally-Language-Grounding
视频理解专业交流群
关注最新的视频理解与分析技术,欢迎加入52CV-视频理解专业交流群,扫码添加CV君拉你入群,(如果你已经加CV君为好友,请直接私信就好了,不必重复添加)
(请务必注明:视频理解)

喜欢在QQ交流的童鞋可以加52CV官方QQ群:702781905。
(不会时时在线,如果没能及时通过还请见谅)

长按关注我爱计算机视觉

















 7644
7644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









