






 论文《Patches Are All You Need?》介绍了ConvMixer,一个基于卷积的简单模型,它在ImageNet上实现了与Transformer类似的高性能。ConvMixer通过标准卷积混合空间和通道信息,挑战了Transformer优越性能源于其结构而非patch表示的假设。
论文《Patches Are All You Need?》介绍了ConvMixer,一个基于卷积的简单模型,它在ImageNet上实现了与Transformer类似的高性能。ConvMixer通过标准卷积混合空间和通道信息,挑战了Transformer优越性能源于其结构而非patch表示的假设。
关注公众号,发现CV技术之美
本文分享论文『Patches Are All You Need?』,提出《ConvMixer》,只需 7 行 pytorch 代码实现的网络,就能在 ImageNet 上达到 80%+ 的精度!
详细信息如下:

论文链接:https://openreview.net/forum?id=TVHS5Y4dNvM
项目链接:https://github.com/tmp-iclr/convmixer
复现代码:https://github.com/xmu-xiaoma666/External-Attention-pytorch#4-ConvMixer-Usage
导言:

尽管卷积网络多年来一直是视觉任务的主要结构,但最近的实验表明,基于Transformer的模型,在某些设置下可能超过卷积神经网络的性能。然而,由于Transformer中自注意层的计算复杂度和输入大小呈二次关系,因此ViT需要使用patch embedding,它将图像的小区域组合成单个输入特征,以便自注意力能够应用于更大的图像大小。
因此,作者就提出了一个问题:ViT的性能是由于其强大的Transformer结构,还是至少有部分是由于使用patch作为输入表示?
在本文中,作者为后者提出了一些证据:我们提出了一个非常简单的模型ConvMixer,在思想上类似于ViT和MLP-Mixer,因为它直接将patch作为输入,分离空间和通道尺寸的混合建模,并在整个网络中保持相同大小的分辨率。但是ConvMixer只使用标准卷积来实现混合步骤。尽管ConvMixer的设计很简单,但是实验证明了ConvMixer在相似的参数计数和数据集大小方面优于ViT、MLP-Mixer及其一些变体,以及经典的视觉模型,如ResNet。
01
Motivation
多年来,卷积神经网络一直是计算机视觉任务的主流结构。但最近,基于Transformer的结构,在许多这些任务中显示出不错的性能,特别是在大型数据集上,通常优于经典的卷积结构。因此,作者认为Transformer成为视觉领域的主导结构只是时间问题,就像它们在NLP中的影响一样。
然而,如果想将Transformer应用于图像,就不能将原始图像直接输入到Transformer中,因此Transformer中的自注意层的计算成本将与每张图像的像素数成二次相关。因此需要将图像分割成多个“patch”,然后采用线性投影将他们转换成token,再将Transformer应用于这个token集合上。
在本文中,作者探讨了一个问题:从根本上讲,视觉Transformer的强大性能是否可能更多地来自于这种基于patch的表示,而不是来自于Transformer结构本身?为了回答这一问题,作者提出了一个非常简单的卷积结构ConvMixer,因为他和MLP-Mixer的结构非常相似。
这种结构和ViT、MLP-Mixer有很多相似之处:它直接在patch上操作;它在所有层中保持相同分辨率的表示;它不对连续层中的表示进行降采样;它分离了“channel-wise mixing”和“spatial mixing”过程。但是,与他们不同的是,ConvMixer只采用了标准卷积结构。

ConvMixer的实验结果表明,虽然使得它实现非常简单,只需要7行pytorch代码(如上图所示),但能实现和ResNet、MLP-MIxer、ViT等复杂结构相似的性能。这表明,至少在某种程度上,patch表示本身可能是视觉Transformer优越性能来源的关键组成部分之一。
02
方法
2.1. ConvMixer
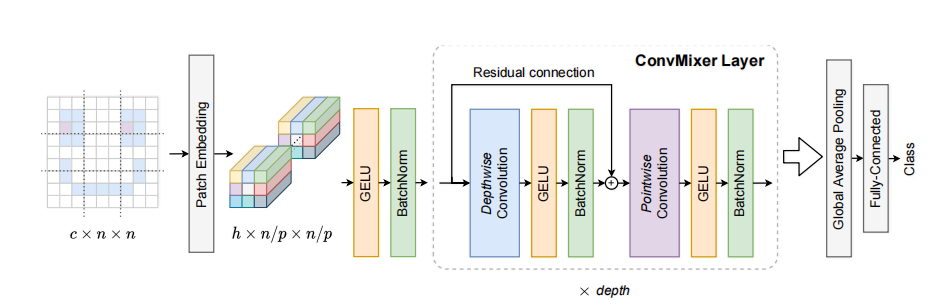
ConvMixer包括一个patch embedding层,然后重复应用一个简单的卷积块。模型结构图上图所示,像ViT一样,作者也同样运用了Patch Embedding层,Patch大小为p,嵌入维数为h的Patch Embedding层可以通过与输入通道为,输出通道为,kernel大小为, 步长为的卷积来实现:
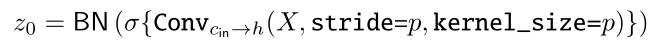
ConvMixer模块由深度卷积(即,组数等于通道数h的分组卷积)和逐点卷积(即,核大小为1 × 1的常规卷积)组成。每个卷积之后都有一个激活函数和BatchNorm:

在经过多个卷积块之后,作者应用了一个全局池化来获得大小为h的特征向量,并将其传递给softmax分类器,输出分类结果。
Design parameters
ConvMixer的实例化依赖于四个参数:
Patch Embedding的通道维度h;
ConvMixer层的重复次数d;
控制模型中特征分辨率的patch大小p;
depthwise卷积的卷积核大小k。
在后面的实例化中,作者将特定设置的ConvMixer表示为,其中h为通道维数,d为卷积层的重复次数。
2.2. Implementation
2.2.1. Readable PyTorch Code
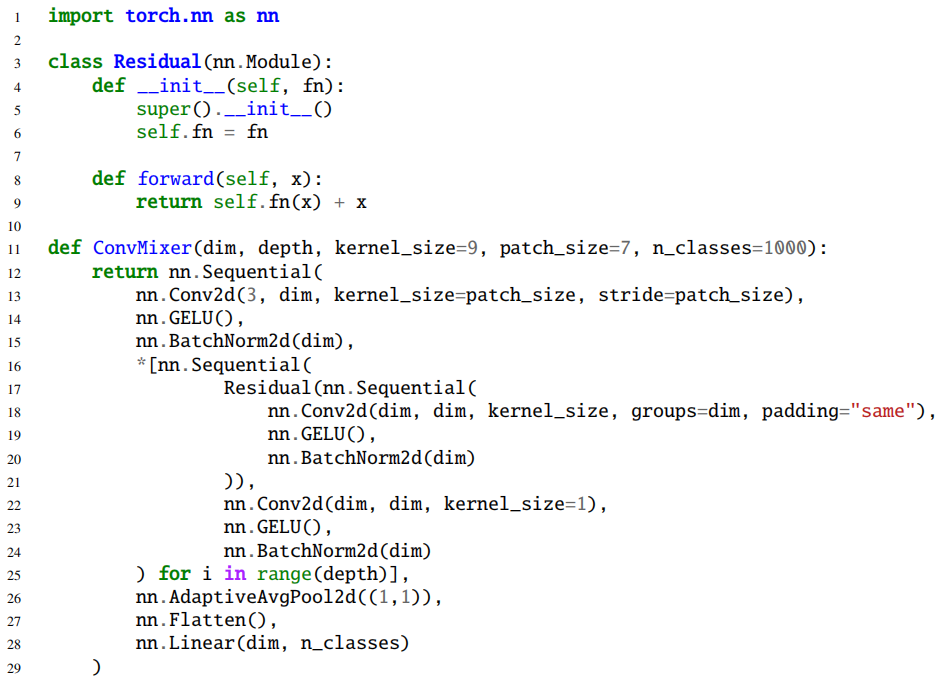
上图展示了本文方法可读性比较强的pytorch实现。整个网络其实非常简单,就是由三部分组成:
首先就是patch embedding的过程,这个过程采用的是一个卷积,这个卷积的卷积核大小和步长是一样的,所以卷积过程没有重叠;
然后就是本文提出的用来替换Self-Attention和FFN的结构,分别由两种卷积实现,第一种是逐通道的卷积,这个卷积的组数和输入特征的通道数是一样的,可以进行空间上的建模,用于替换Self-Attention;第二种是逐点卷积,这个卷积的卷积核大小是1x1,可以进行通道上的建模,用于替换FFN。此外,与Transformer不同,这里只有逐通道的卷积是有残差连接的,逐点卷积是没有残差连接的。
最后就是进行AdaptiveAVGPooling之后,然后用线性层分类,这一部分和ResNet等卷积网络是一样的。
2.2.2. Simple PyTorch Code

此外,作者也提供了一个简短的pytorch实现,只需要280个字符,就能实现ConvMixer。
03
实验
3.1. CIFAR-10 Experiments
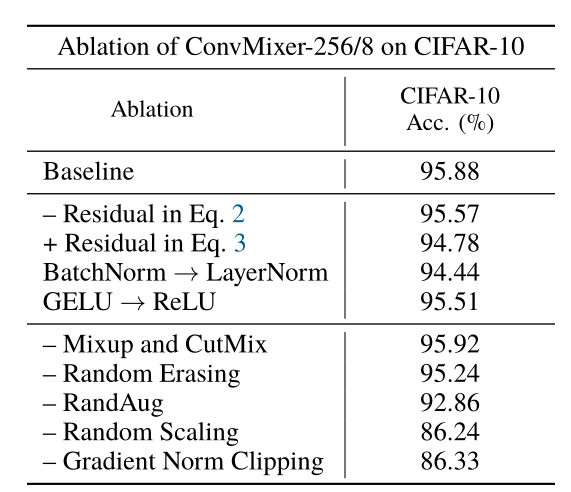
作者在CIFAR-10数据集上,基于ConvMixer-256/8模型上进行了消融实验,作者首先尝试了去掉逐通道卷积的残差结构和加上逐点卷积的残差结构,可以看出,这两种方式都会带来模型性能的下降。然后,作者也尝试了将BatchNorm换成LayerNorm,把GELU换成ReLU,以及加上各种数据增强,可以看出,模型性能都会有一定程度的下降。
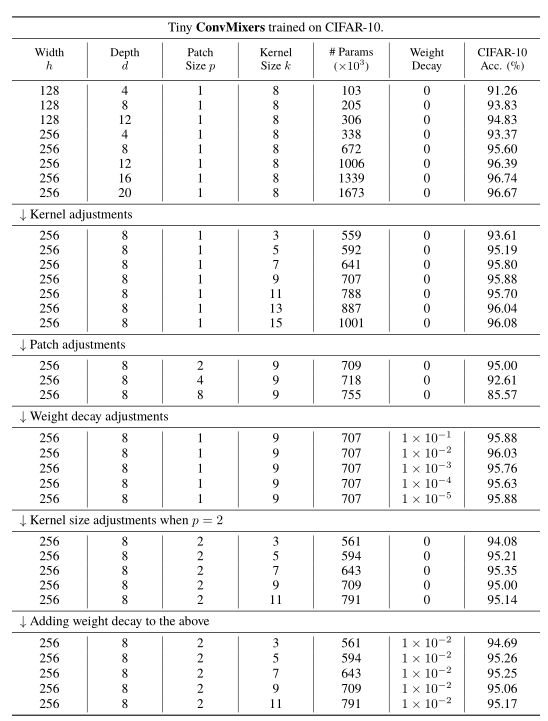
除此之外,作者还在CIFAR-10上进行了h、d、p、k和weight decay的消融实验,结果如上表所示。
3.2. ImageNet
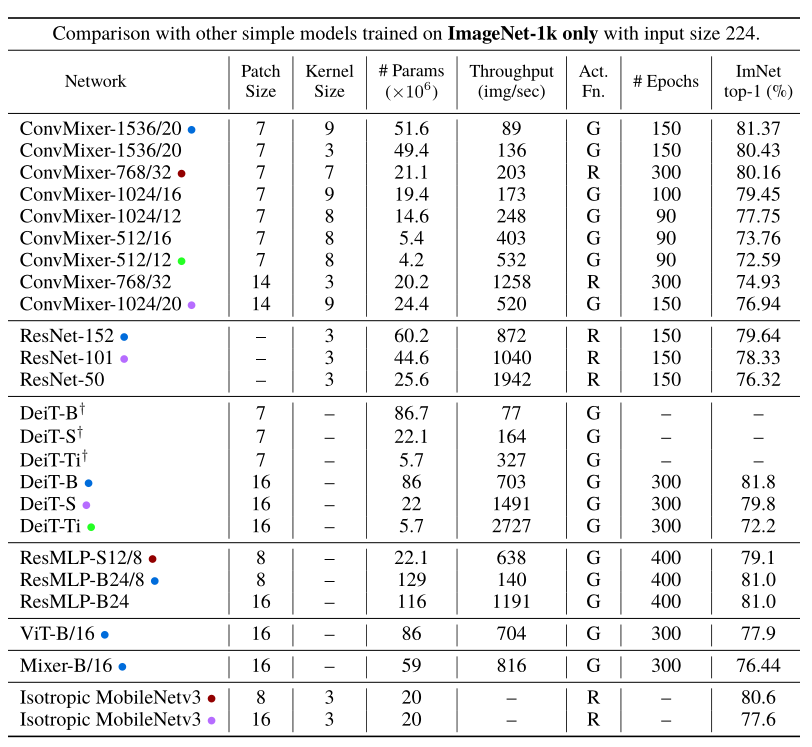
上表展示了本文方法和各种ViT、CNN结构在ImageNet的对比,可以看出,虽然本文的模型设计非常简单,但依旧可以在相当的参数量下,实现和其他ViT和CNN结构相当甚至更好的性能。
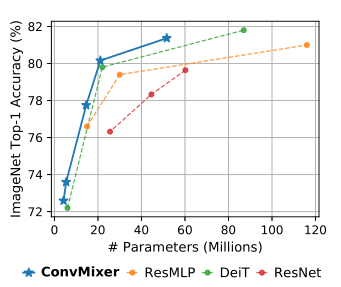
上图展示了ConvMixer和其他结构的参数量、准确的对比图,可以看出本文方法的优越性。
3.3. Weight Visualization

上图展示了patch size为14的ConvMixer-1024/20的Patch embedding权重。

上图展示了patch size为7的ConvMixer-768/32的Patch embedding权重。
可以看出,从p = 14到p = 7的权重看起来几乎相同:后者看起来只是前者的下采样版本。
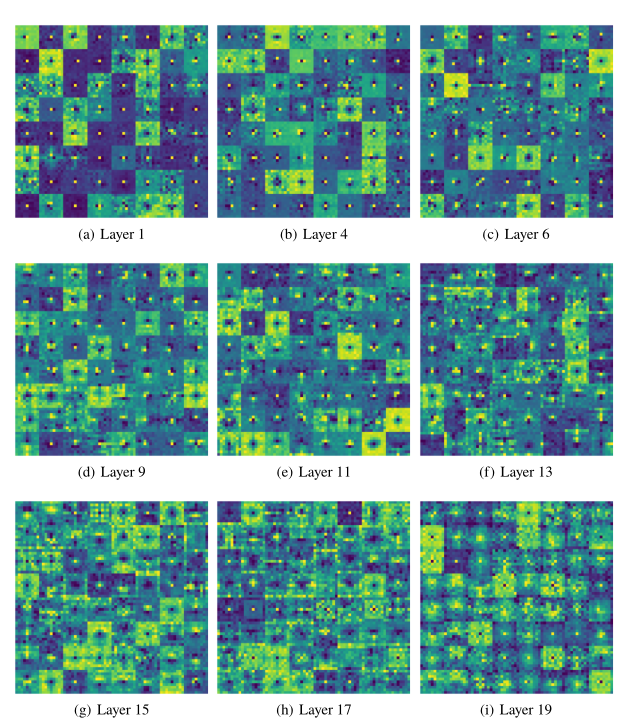
上图展示了ConvMixer-1536/20不同层的随机64个depthwise convolutional kernel的可视化。
04
总结
在本文中,作者提出了ConvMixer,这是一种非常简单的模型,它仅使用标准卷积就能独立地混合patch embedding的空间和通道信息。虽然ConvMixer不是为了最大化准确率或速度而设计的,但ConvMixer优于Vision Transformer和MLP-Mixer,并与ResNet、DeiT和ResMLP性能相当。
虽然在文章中,作者将ConvMixer的Patch Embedding层对标了ViT的Transformer中的Patch Embedding层,但是个人觉得,这个部分也可以是看成ResNet的Stem层,只不过下采样的程度比较大,然后后面都是卷积操作,所以就是一个纯卷积模型,只不过设计上因为没有像ResNet那样的多次下采样率,所以看起来和实现起来会更加简单,只需要用很少的代码就能实现。
▊ 作者简介
研究领域:FightingCV公众号运营者,研究方向为多模态内容理解,专注于解决视觉模态和语言模态相结合的任务,促进Vision-Language模型的实地应用。
知乎/公众号:FightingCV

END
欢迎加入「计算机视觉」交流群👇备注:CV



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









