







 本文探讨了半监督学习在解决数据标注难题中的作用,特别是在联邦学习场景下,面对非独立同分布的数据和隐私保护需求。文章介绍了伪标签、熵最小化、标签锐化、一致性正则化等半监督学习策略,并通过Mixup、MixMatch、ReMixMatch、FixMatch和FlexMatch等方法进行了深入阐述,展示了这些方法如何提高模型的泛化能力和数据利用率。
本文探讨了半监督学习在解决数据标注难题中的作用,特别是在联邦学习场景下,面对非独立同分布的数据和隐私保护需求。文章介绍了伪标签、熵最小化、标签锐化、一致性正则化等半监督学习策略,并通过Mixup、MixMatch、ReMixMatch、FixMatch和FlexMatch等方法进行了深入阐述,展示了这些方法如何提高模型的泛化能力和数据利用率。
关注公众号,发现CV技术之美
在现实世界中,数据往往存在各种各样的问题,例如:图片分类模型对标注数据的依赖性很强、标注图片数据难以获取、大量未标注数据存在、针对某个场景的数据量过小…等等问题。
在联邦学习中,由于数据的非独立同分布特性(Non-IID)导致了每个客户端(数据拥有者)自身的数据可能存在噪声、标注不完全、数据量不够等等情况,同时我们从隐私安全的方面考虑到只要使用数据,就有可能存在隐私泄露的风险,因此有人思考到:能否只从每个数据拥有方抽取一小部分数据(含有标签)放到客户端,然后再添加大量无标注数据来帮助模型进行训练呢?
这就不得不提到半监督学习,半监督学习是指训练集同时包含带标签的样本数据以及未标记的样本数据,在不需要人工干预的情况下,让模型可以自动利用未标记样本数据来提升自己的学习性能。
进一步而言,本质就是模型利用已标注数据从未标注数据中提取信息用于自身训练,同时有些情况下如果标注数据很多,那么再利用未标注数据可以提升模型的泛化能力。如下图所示,半监督学习可以在标签不知道的情况下让模型也能正确完成任务。
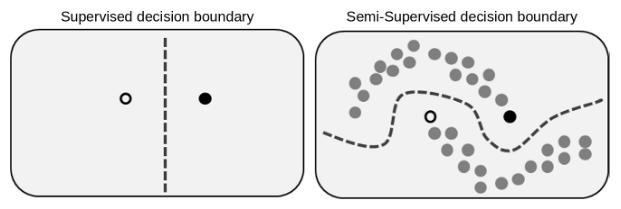
图1:半监督学习example(链接1)
以往的联邦学习工作往往专注于监督学习任务的研究,即要求所有的数据都必须包含相应的标签。但是在联邦学习的现实场景下,本地客户端所包含的数据常常大部分甚至全部都是没有相应的标签的。因此,我们需要结合半监督学习的技术来改进算法从而解决联邦学习中存在的一些问题。
接下来我将从近期的一些论文从半监督学习与联邦半监督学习两个方面进行概述,并加以总结和思考。
▊ 半监督学习
伪标签(Pseudo Label):伪标签是半监督学习的一个基本思路,即模型在标注数据上进行训练然后对未标注数据进行预测,得到的预测结果作为未标记数据的标签。
模型通过伪标签的方式,可以将未标注样本拉向与其最相邻的类,然后再训练时(有标签数据+无标签数据一起训练)这就相当于约束了模型对无标签的搜索空间,但是也有一个缺点就是这个伪标签的预测是不分对错的,其仅仅只是提高了模型对该样本的置信度。
同时我们也可以从熵的角度去思考,强迫模型对未标记数据做出预测,这就代表熵降低了,模型偏向于低熵预测,通过最小化熵将模型预测拉向当前最邻近的类别。伪标签方法带来了若干好处:
1)增强模型的泛化能力和鲁棒性;
2)模型充分利用了无标注数据。
最小化熵(Entropy Minimization):同时我们也可以从概率的角度去思考,熵代表事件的混乱程度,如果一个事件分布越均衡那么其熵越高。强迫模型对未标记数据做出预测,这就代表熵降低了,模型偏向于低熵预测,通过最小化熵将模型预测拉向当前最邻近的类别。强迫模型如何作出低熵预测呢?
实现方法其实很简单,就在损失函数中增加一项loss:最小P_model(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









