







 本文介绍了PGNet,一种用于高分辨率显著目标检测的新型单阶段架构,它采用Transformer和CNN并行提取特征,并通过跨模型嫁接模块实现特征信息的融合。此外,还提出了一种新的超高分辨率显著目标检测数据集UHRSD,以促进高分辨率分割任务的研究。实验证明,PGNet在处理高分辨率图像时表现出色。
本文介绍了PGNet,一种用于高分辨率显著目标检测的新型单阶段架构,它采用Transformer和CNN并行提取特征,并通过跨模型嫁接模块实现特征信息的融合。此外,还提出了一种新的超高分辨率显著目标检测数据集UHRSD,以促进高分辨率分割任务的研究。实验证明,PGNet在处理高分辨率图像时表现出色。
关注公众号,发现CV技术之美
▊ 引言
最近基于深度学习的显著目标检测方法取得了出色的性能。然而现有的大多数方法多事基于低分辨率输入设计的,这些模型在高分辨率图片上的表现不尽人意,这是由于网络的采样深度和感受野范围之间的矛盾所导致的。
为了缓解这一矛盾,我们提出了一个新颖的单阶段架构名叫金字塔嫁接网络(PGNet),使用transformer和CNN骨干网络从不同分辨率图像中独立地提取特征,然后将特征信息从transformer分支嫁接到CNN分支。
同时我们提供了一个新的超高分辨率显著目标检测数据集(UHRSD),包含了5,920张4K-8K分辨率的图片及其像素级标注。这是我们所知的目前规模最大分辨率最高的显著目标检测数据集,希望可以为未来高分辨率分割任务的研究提供帮助。大量实验表明,我们的方法简单高效地在高分辨率显著检测任务上取得了良好的表现。



▊ 1.论文、代码和数据集下载链接

论文地址:https://arxiv.org/abs/2204.05041
数据集地址:
https://drive.google.com/drive/folders/1u3K65AaKh78P5qKXTsMjVI1SvBXNAPFk?usp=sharing
代码地址:https://github.com/iCVTEAM/PGNet
▊ 2.研究动机
人类的视觉系统具有从复杂场景中快速、准确地定位感兴趣物体或区域的能力,称为选择性注意力机制。显著物体检测(Salient Object Detection, SOD)是对该机制的一种模拟,旨在分割给定图像中最具视觉吸引力的物体或区域。大多数现有的SOD方法在一个特定的输入分辨率范围内表现的很好(例如224×224,384×384)。
但随着图像采集设备的快速更新,获取到的图片分辨率也随之急速增长,高分辨率图像(例如1080P,2K,4K图像)在日常生活中很容易被获取。然而,这些日常获取到的图像显然超出了现有模型可处理的分辨率范围。
一些现有的方法已经开始关注高分辨率输入导致的问题。但这些方法都是多阶段的。在不同阶段以不同输入分辨率处理图像:在第一阶段以低分辨率输入对全局语义进行获取并得到初步的模糊预测结果;
在第二阶段,使用第一阶段得到的粗略结果以及高分辨率输入,通过轻量级的网络保证分辨率的同时避免巨大的计算消耗对第一阶段得到的模糊结果进行细化得到最终的结果。但这样也带来了新的问题,例如多阶段导致的推理速度变慢以及优化相对困难等。
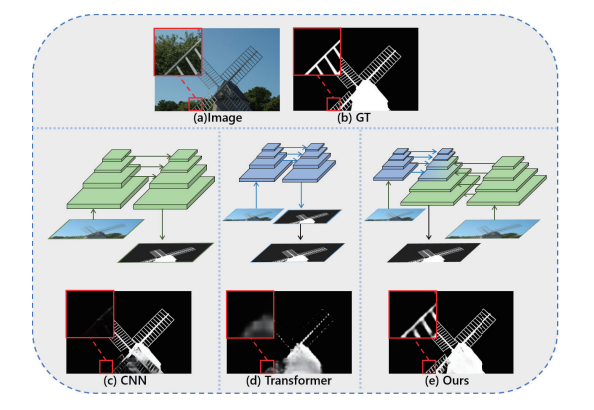
图1:不同结构对比。(a) 输入图片 (b) 真值标签 (c)高分辨率直接输入卷积网络的结果 (d)下采样后输入Swin-FPN结果 (e) 我们方法的结果
我们认为单一深度的网络不能解决感受野和高分辨率细节同时保留的矛盾,因此我们提出分别以不同的输入分辨率提取两组特征然后将信息从一个分支嫁接到另一分支。
为此,我们重新思考了双分支的架构并设计了一个新颖的单阶段深度网络金字塔嫁接网络(Pyramid Grafting Network, PGNet)来解决高分辨率显著性的问题。
我们使用了Res
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









