






关注公众号,发现CV技术之美
本文分享『REVIVE: Regional Visual Representation Matters in Knowledge-Based Visual Question Answering』,VQA不只需要图片,还需要外部知识!华盛顿大学&微软提出提出REVIVE,用GPT-3和Wikidata来辅助回答问题!
详细信息如下:

论文链接:http://arxiv.org/abs/2206.01201[1]
01
摘要
本文重新探讨了基于知识的视觉问答(VQA)中的视觉表示,并证明了更好地使用区域信息可以显著提高性能。虽然在传统的VQA中对视觉表示进行了广泛的研究,但在基于知识的VQA中对视觉表示的研究还不够深入,尽管这两项任务有着共同的精神,即依赖视觉输入来回答问题。
具体而言,作者观察到,在大多数最先进的基于知识的VQA方法中:1)视觉特征要么从整个图像中提取,要么以滑动窗口的方式检索知识,而忽略了对象区域内/之间的重要关系;2) 在最终的回答模型中,视觉特征没有得到很好的利用,这在一定程度上违反了直觉。
基于这些观察,作者提出了一种新的基于知识的VQA方法REVISE,该方法不仅在知识检索阶段,而且在回答模型中,都试图利用对象区域的显式信息。本文的关键动机是对象区域和内在关系对于基于知识的VQA非常重要。
作者在标准OK-VQA数据集上进行了广泛的实验,取得了最新的性能,即58.0%的准确率,大大超过了以前最先进的方法(+3.6%)。作者还进行了详细的分析,并说明了区域信息在基于知识的VQA的不同框架组件中的必要性。
02
Motivation
在日常生活中,许多基于视觉的决策过程超越了感知和识别。例如,如果我们在熟食店看到一个沙拉,我们决定是否购买它不仅取决于沙拉里有什么,而且还取决于每个项目中的卡路里。这激发了基于知识的视觉问答(VQA)任务,该任务扩展了传统的VQA任务,以解决更复杂的问题,即回答开放领域问题需要常识。
根据定义,基于知识的VQA采用三种不同的信息源来预测答案:输入视觉信息(图像)、输入问题和外部知识。虽然现有的基于知识的VQA研究主要集中于改进外部知识的融合,但本文侧重于改进以对象为中心的视觉表示,并提出了一个全面的实证研究来证明视觉特征在这项任务中的重要性。
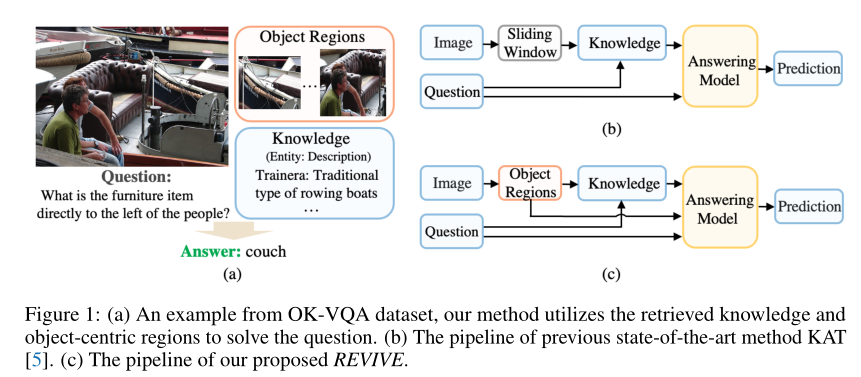
直观地说,视觉信息应该很好地用于知识检索和最终回答。然而,作者发现现有的最先进(SOTA)方法并没有充分利用它。一方面,他们简单地使用整个图像或图像上的滑动窗口来检索外部知识。另一方面,他们只使用视觉信息进行知识检索,而在最终的回答模型中忽略了视觉信息。换句话说,它们仅将检索到的知识和问题作为纯自然语言处理(NLP)模型进行融合,以获得答案,上图(b)中说明了一种典型的方法。
在本文中,作者重新讨论了基于知识的VQA中的视觉表示,并认为应该专门考虑和使用对象区域的信息及其关系。上图(a)显示了潜在动机,这表明理解对象及其关系是必要的。为此,作者提出REVISE更好地利用区域视觉表示来进行基于知识的视觉问答。它不仅利用详细的区域信息进行更好的知识检索,而且还将区域视觉表示融合到最终的回答模型中。具体来说,作者首先使用对象检测器GLIP来定位对象,然后使用裁剪区域proposal来检索不同类型的外部知识。最后,将知识与区域视觉特征集成到一个统一的基于Transformer的答案模型中,以生成最终的答案。
作者在OK-VQA数据集上进行了广泛的实验,所提出的REVISE实现了58.0%的SOTA性能,比以前的SOTA方法的结果绝对提高了3.6%。
本文的贡献总结如下:
作者系统地探讨了如何更好地利用视觉特征来检索知识。实验结果表明,与基于全图像和滑动窗口的方法相比,基于区域的方法表现最好。
作者将区域视觉表示、检索到的外部知识和隐含知识集成到基于Transformer的问答模型中,该模型可以有效地利用这三种信息源来解决基于知识的VQA问题。
作者提出的REVISE在OK-VQA数据集上实现了最先进的性能,即58.0%的准确率,大大超过了以前的方法。
03
方法
基于知识的VQA任务寻求基于图像以外的外部知识回答问题。具体来说,将基于知识的VQA数据集表示为,其中分别表示第i个样本的输入图像、问题和答案,N是总样本数。给定数据集,目标是训练一个参数为θ的模型,用输入和生成答案。
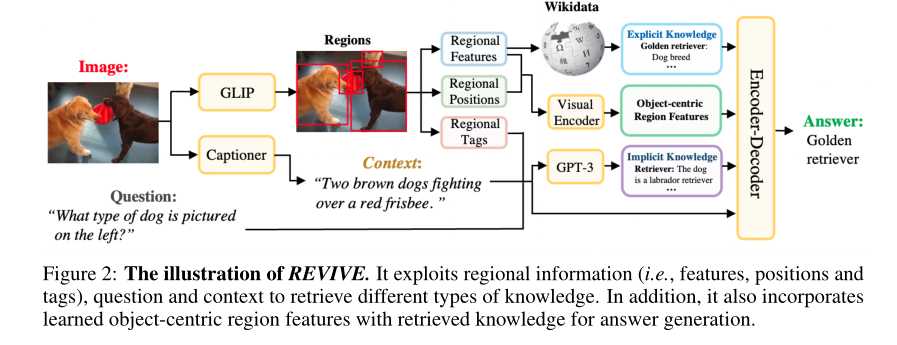
上图显示了REVISE方法的概述。首先利用输入图像中检测到的区域来获取以对象为中心的区域特征并检索显式知识,同时,通过区域标记、问题和上下文基于GPT-3来检索隐含知识。然后,将区域视觉特征、检索到的知识以及由区域标记、问题和上下文组成的文本提示融合到编解码模块#中,生成答案。
3.1 Regional Feature Extraction Module
给定一幅图像I,作者首先采用一个目标检测器来给出区域proposal的位置:
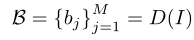
其中,是bouding boxes集,M是检测到的box数,D(·)是目标检测器。这里,作者采用Visual Grounding模型GLIP作为D(·)。作者使用文本提示“检测:人、自行车、汽车、…、牙刷”,其中包含MSCOCO数据集的所有对象类别。这样,模型可以提供与这些类别关联的所有边界框。
在从GLIP中获得感兴趣对象的边界框B之后,作者根据B裁剪图像I,以获得区域proposal。然后,作者从proposal中提取以对象为中心的视觉特征,其中是第j个proposal的视觉嵌入,S是嵌入维度,E(·)代表图像编码器。受最近对比训练的视觉语言模型强大迁移能力的启发,作者采用CLIP的视觉编码器作为图像编码器E(·),并用[CLS] token的编码作为最终嵌入。
为了理解对象之间的关系,作者发现引入位置信息B及其区域视觉特征也很重要。除了嵌入,以文本格式显式获取每个区域proposal的描述也有助于知识检索。对于经过对比训练的视觉语言模型,如果图像和文本对齐良好,训练损失明显会促使图像嵌入和文本嵌入之间的内积增大。因此,这样的模型能够通过计算内积,从一组定制标签中选择描述图像的标签。将CLIP的语言编码器表示为T(·)。给定一组标签,N1是总标签数,作者计算区域proposal和所有标签之间的内积,并采用具有top-P相似度的标签作为区域proposal的描述。
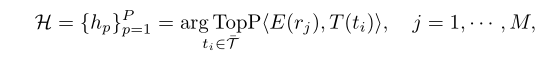
其中是内积,P表示获得的区域标签的数量,h表示检索到的区域标签。
作为对局部文本描述的补充,作者采用caption模型来明确描述主要对象之间的关系,并提供更多的上下文:
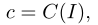
其中,C(·)是caption模型。例如,在上图中,“Two brown dogs fighting over a red frisbee”提供了对象之间的基本关系。这里,作者采用Vinvl作为标题模型C(·)。
总的来说,提取区域视觉和位置信息为和,对象的文本描述以及对象之间的关系为和。这些是区域信息源检索外部知识。
3.2 Object-Centric Knowledge Retrieval Module
在本文中,作者同时考虑了显性知识和隐性知识。
3.2.1 Explicit Knowledge
由于基于知识的VQA提出的问题是一般性和开放性的,因此引入外部知识对于模型通过提供输入图像视觉内容之外的额外补充知识来生成准确答案非常重要。
External Knowledge Base
作者从Wikidata构建一个子集,从而构建一个外部知识库Q。具体而言,作者提取了8个常见的类别,即角色、兴趣点、工具、车辆、动物、服装、公司、运动,以形成子集Q。Q中的每个项目都由一个实体和相应的描述组成,例如,一个实体及其描述可以分别为“钉板”和“带固定间距孔的板墙,用于插入钉或钩”。
Regional Knowledge Retrieval
像CLIP这样的视觉语言模型能够从一组文本中选择最相关的文本。作者将知识库Q中的条目重新格式化为“{entity}是{description}”,并将重新格式化的文本集表示为。作者检索所有区域proposal中最相关的前K个知识条目,作为显式知识:
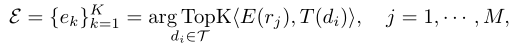
其中K表示检索到的显式知识样本数。
3.2.2 Implicit Knowledge
大型语言模型,如GPT-3,不仅在许多语言任务中表现出色,而且还从其训练语料库中记忆了大量常识知识。因此,作者利用GPT-3作为隐式知识库,将任务重新表述为开放领域的问答。
Context-Aware Prompt with Regional Descriptions
根据问题Q、标题c和区域标记H设计文本提示。具体来说,作者采用提示X为“context: {caption} + {tags}. question: {question}”。这样,语言模型还补充了区域视觉信息。
Implicit Knowledge Retrieval
最后,作者将重新编制的提示X输入到GPT-3模型,并获得预测答案。由于一些问题可能有歧义,作者采用了prompt tuning过程,得到候选答案。除了答案预测之外,作者还希望从GPT-3模型中获得相应的解释,以获得更多的上下文信息。
更具体地说,通过向GPT-3中输入文本提示“{question} {answer candidate}. This is because”,可以获得相应的解释。注意,{question}和{answer candidate}分别是图像I的输入问题Q和GPT-3的答案。最终检索到的隐式知识可以表示为。
3.3 Encoder-Decoder Module
一旦检索到显性和隐性知识以及区域信息,就利用FiD网络结构对检索到的知识和区域信息进行编码和解码。
Knowledge Encoder
对于显式知识,作者将输入文本重新格式化为“entity: {entity} description: {description}”,其中实体和描述来自检索到的显式知识中的条目。作者将该文本表示为,其中。
对于隐性知识,作者采用“candidate: {answer} evidence: {explanation}”的输入格式,其中答案是检索到的答案,解释是。这里,,其中是GPT-3提供的答案数。将输入文本表示为。
然后,通过FiD编码器以文本格式对知识进行编码,该编码器表示为:
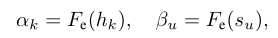
其中,D表示嵌入维度
Visual Encoder
作者为视觉嵌入和位置坐标引入了一个视觉编码器。作者将和馈入两个不同的全连接层,将输出叠加成一系列向量,然后将其馈入Transformer编码器:
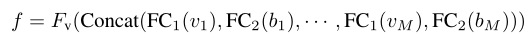
其中,和是两个不同的全连接层,是沿新维度的concat操作。
Context-aware Question Encoder
为了更好地利用上下文信息,作者将输入问题Q替换为上下文感知提示X,然后使用相同的Transformer编码器对其进行编码:
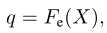
其中,表示编码的上下文感知问题。
Generative Decoder
现在获得了知识编码、视觉编码和上下文感知问题编码。注意,作为编码器的输出,它们都是向量序列。然后,作者将这些向量沿第一维concat起来,并将它们输入FiD的解码器:
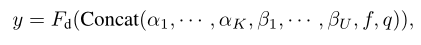
其中y表示生成的答案。采用交叉熵损失函数对模型进行训练:
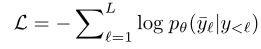
其中,L是 ground truth答案文本的长度,是位置处的 ground truth文本,θ是模型参数。
Model Ensemble
为了生成更准确的答案,一种很有效的方法是利用多个经过训练的模型,即模型集成。在实验中,作者只训练三个初始化种子不同的模型,然后从这三个模型生成的结果中选择最频繁的结果作为每个样本的最终答案预测。
04
实验
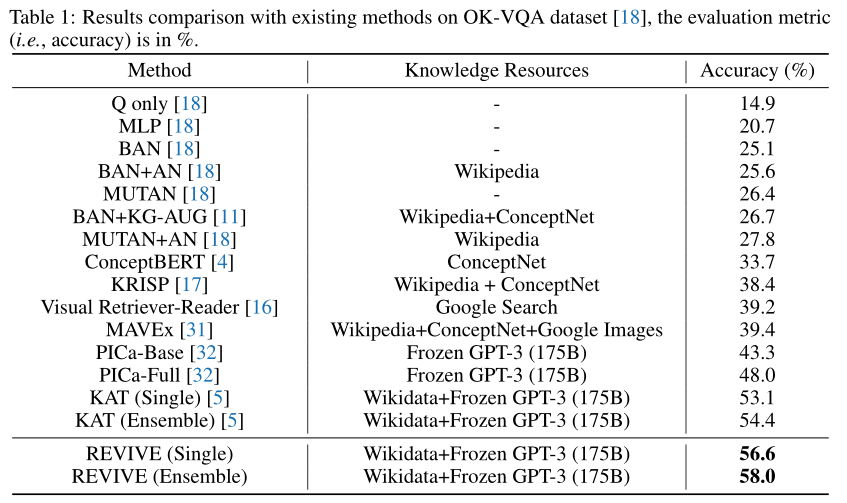
如表所示,可以看到之前的工作(例如,KRISP、Visual Retriever Reader和MAVEx)实现了类似的性能,准确率约为38.4%至39.4%。
最近,PICa是第一个利用预训练好的语言模型GPT-3作为基于知识的VQA任务的知识库,而KAT进一步引入Wikidata作为外部知识资源,这两部作品与之前的作品相比取得了显著的成绩。REVISE可以大大优于所有现有方法。
具体而言,即使使用相同的知识资源(即Wikidata和GPT-3)本文们的单一模型也可以达到56.6%的准确率,而之前最先进的方法KAT的准确率为53.1%。使用模型集成时,本文的方法可以达到58.0%的准确率,而KAT的准确率为54.4%。这些结果证明了所提方法的有效性。
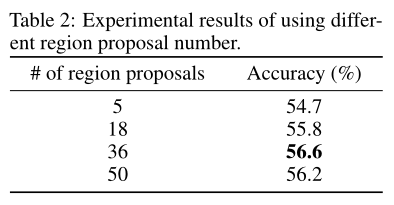
作者进行了消融研究,以了解使用不同区域proposal的效果。结果如上表所示。可以观察到,当区域proposal数为36时,该模型实现了最佳性能。注意这个推测,当区域proposal的数量太大时,会有一些无意义和噪声的区域proposal,而如果区域proposal的数量太小,会忽略许多以对象为中心的重要区域,这都会影响模型的性能。
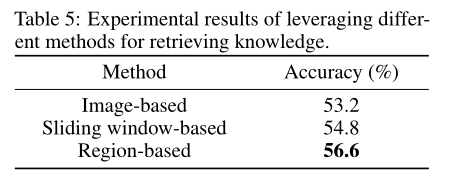
利用视觉表示检索知识的方法在基于知识的VQA中起着重要的作用。上表显示了使用三种知识检索方法的结果,即基于图像的、基于滑动窗口的和基于区域的。

为了在上下文中引入更多语义,作者提出在给定上下文后面添加区域感知描述(即区域标记,regional tags)。作者在上表中报告了对文本提示X使用不同区域标标记的结果。结果表明,当区域标签数为30时,该算法的性能最优。事实上,当区域标记的数量太大时,将检索相对不相关的对象标记,从而牺牲模型的性能。

除了将以对象为中心的区域proposal的视觉表示纳入模型之外,作者还采用了位置信息(即位置坐标)。上表中报告了是否使用位置坐标的结果。引入区域坐标可以将性能提高0.8个百分点。

为了更好地显示REVISE各成分的效果,作者在上表中报告了实验结果。请注意,作者选择基于区域的方式来检索不同类别的知识。可以观察到,引入的组件可以持续改进模型的性能。

本文的方法的成功案例如上图所示。可以观察到,本文的方法能够准确地检索与检测到的对象区域相对应的隐式和显式知识,并处理这些对象区域之间的关系。

上图中展示了失败示例。如左例所示,即使预测结果Cabin没有出现在ground truth答案中,本文方法生成的答案对于这种情况仍然是合理的。
05
总结
在本文中,作者提出了一种称为REVIVE的方法,该方法重新审视了基于知识的VQA任务的区域视觉表示。具体而言,作者进行了综合实验,以展示所提出方法中不同组件的效果,这可以证明所提出的基于区域的知识检索方法的有效性。此外,REVISE将以对象为中心的区域视觉特征和两种知识,即内隐知识和外显知识,整合到预测的答案生成模型中。本文的方法在OK-VQA数据集上实现了最先进的性能。
参考资料
[1]http://arxiv.org/abs/2206.01201

END
欢迎加入「视频问答」交流群👇备注:VQA















 162
162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









