






关注公众号,发现CV技术之美
本文转自知乎位作者投稿,作者:jianlong.yuan。原链接:https://zhuanlan.zhihu.com/p/656917825。
本篇论文Viewpoint Integration and Registration with Vision Language Foundation Model for Image Change Understanding提出一种视角融合与配准方法,以解决多模态图文大模型多图理解能力不足的问题,使其适用于图像变化理解场景。提出方法在两个图像变化描述数据集达到 sota 性能,并且在没有使用问答数据训练的情况下,展示出图像变化问答能力。
论文链接: https://arxiv.org/abs/2309.08585
动机
近期,多模态图文大模型(Vision Language Foundation Models, VLFMs)在许多任务中取得了显著表现,它们在对单幅图像的全局特征提取和理解方面表现出色,但对多幅图像之间关联信息的提取和理解能力不足,因此不能直接应用于图像变化理解场景(Image Change Understanding, ICU)。ICU要求模型在排除视角、光照变化等干扰的情况下捕捉图像之间的实际变化并用语言进行描述。
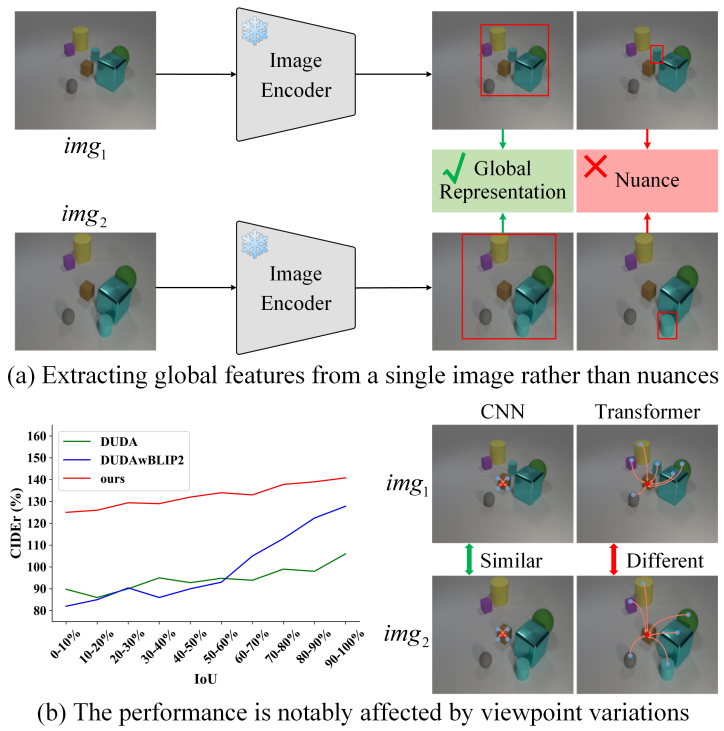
现有的VLFMs在直接应用于ICU时性能不佳,如下图所示,主要由于
VLFMs通常学习单幅图像的全局特征表示,而ICU需要捕捉多个图像之间的细微差异;
由于全局自注意力在整幅图像范围内聚合特征,当图像视角变化时,物体之间的关系也发生变化,VLFMs提取的特征会显著不同,因此VLFMs对视角变化非常敏感。
如图(b)所示,将经典方法DUDA中的图像编码器和语言解码器替换为BLIP-2预训练的图像编码器和大语言模型,修改后的模型在视角变化增加时性能下降明显。
为了解决这些问题,我们提出了一种视角融合与配准方法,增强 VLFMs 的多图理解能力,使其适用于图像变化理解。具体地,我们提出了一个融合adapter图像编码器(Fused Adapter Image Encoder, FAIE),通过引入可训练的adapter和fused adapter对预训练图像编码器进行微调,以利用少量的额外可训练参数学习捕捉图像对之间的变化特征,消除图像编码器预训练和ICU之间的差异。
此外,还设计了一个视角配准流(Viewpoint Registration Flow, VRF)和一个语义增强模块(Semantic Emphasizing Module, SEM)分别在视觉空间和语义空间减少视角变化引起的性能下降。VRF在视觉空间对两个图像的特征进行视角对齐,SEM进一步在语义空间突出真正发生变化的特征。
方法
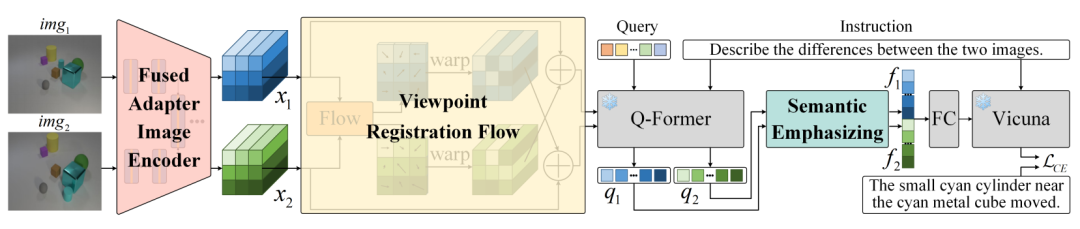
为了提升 VLFMs 的多图理解能力,基于 BLIP-2 提出一种视角融合与配准方法,称为 VIR-VLFM。如上图所示,VIR-VLFM 使用 BLIP-2 中的 EVA-ViT-g/14 作为原始图像编码器,Vicuna 语言模型作为语言解码器,还加入了 BLIP-2 预训练的 Q-Former 和全连接层以消除模态之间的差异。在此基础上,VIR-VLFM 提出了融合 adapter 图像编码器、视角配准流和语义增强模块。
融合adapter图像编码器
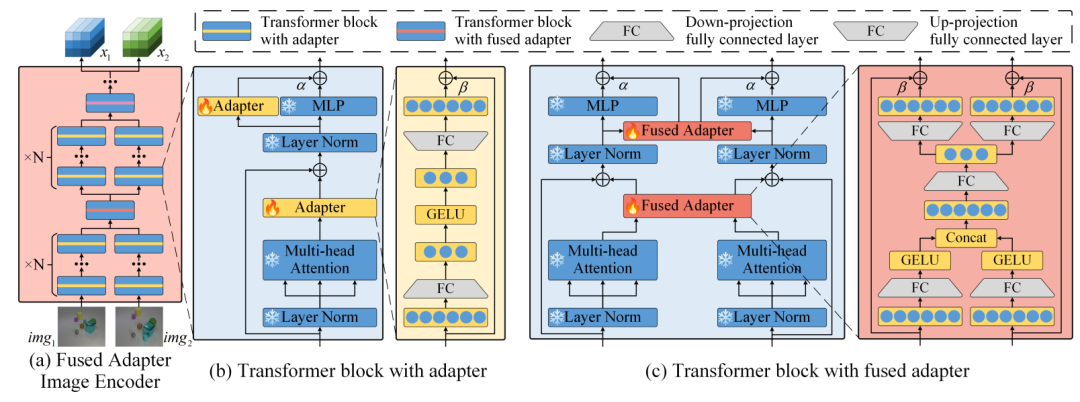
如上图所示,在每个transformer block中插入adapter以适当提取每幅图像的特征,并且每隔N个block使用一个fused adapter以融合两个特征,促使编码器捕捉两幅图像之间的差异。如上图(b)所示,在每个block中插入两个adapter,一个在MSA后,另一个与MLP并行。adapter是一个bottleneck结构,其公式如下:
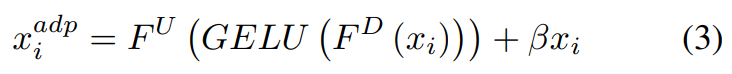
因此,插入adapter的transformer block可以表示如下:
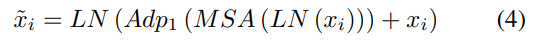
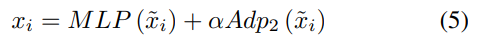
此外,为了促进图像编码器学习捕捉两幅图像之间的差异,设计了fused adapter来替代一些block中的adapter。如图(c)所示,fused adapter是一个双输入双输出模块,公式如下:
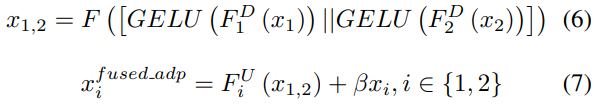
提出的fused adapter在transformer block中的插入位置与adapter相同。训练时,只有新嵌入的adapter和fused adapter的参数会进行更新,其余参数则加载预训练权重并冻结。
视角配准流
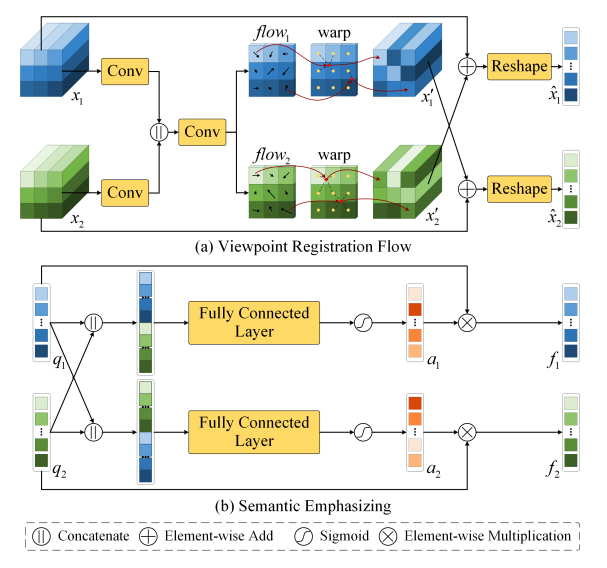
受光流启发,我们设计了一个视角配准流,用于在两幅图像之间进行视角对齐,以消除视角变化对ICU性能的影响。结构如上图(a)所示,利用卷积生成流场flow:

然后使用双线性采样机制通过线性插值四个相邻像素的值来估计每个位置的最终值。此外,大多数图像变化检测方法和ICU方法通常将两个特征相减作为后续解码器的输入。然而对于ICU任务,不仅需要识别变化区域,还需要理解变化区域与周围上下文之间在变化前后的关系。对视角对齐的特征做减法会导致未变化的上下文信息消失。因此,我们使用加法操作进行融合,这样既可以区分开变化区域和未变区域,同时不会丢失上下文信息。
语义增强模块
将视角对齐的特征送入Q-Former转换至语义空间。我们设计了一个语义增强模块,进一步在语义空间突出变化特征。如上图(b)所示,将转换后的语义特征作为输入,以“self-then-other”的方式拼接,然后经过一个全连接层和Sigmoid生成权重,其公式如下:
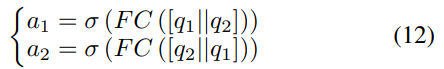
生成的特征充分涵盖了变化物体及其周围上下文信息,并消除了视角变化等干扰影响,将它们送入LLM生成最终的描述。
实验
为了验证提出方法的有效性,在CLEVR-Change和Spot-the-Diff两个数据集进行了消融实验并与先进方法比较。
模块消融实验
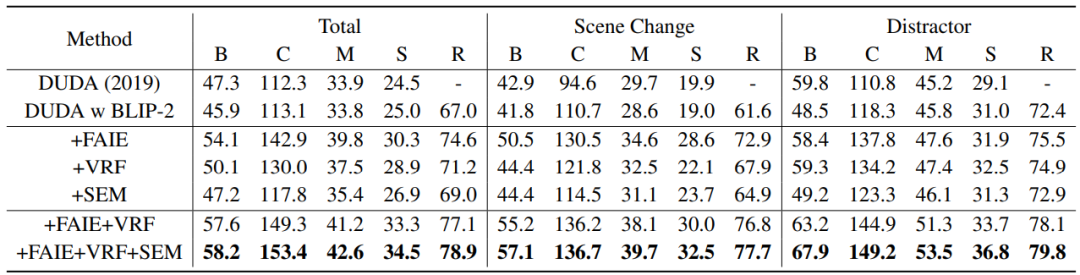
如上表所示,首先将BLIP-2嵌入DUDA中,称为DUDA w BLIP-2,性能与DUDA相当,这意味着直接将VLFMs应用于ICU任务无法获得性能提升。通过加入融合adapter图像编码器,性能显著提高。进一步分别使用视角配准流和语义增强模块,性能也有所提高,特别是在存在干扰项(Distractor)的情况下。同时使用三个模块在所有指标上都达到了最优性能。
融合adapter图像编码器的消融实验
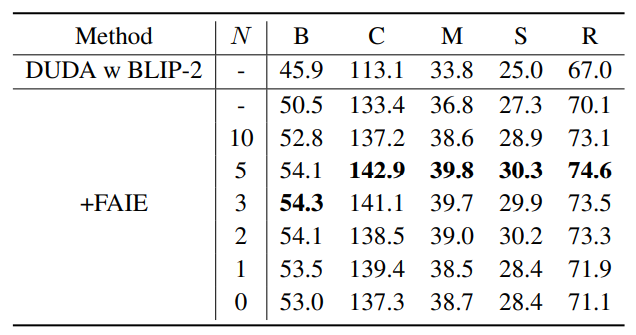
对fused adapter间隔的block数量N进行了消融实验。N=5时获得最佳性能,进一步减少N会导致性能略微下降,表明adapter和fused adapter的间隔使用对于提取图像内部特征和融合图像特征是十分重要的。
视角配准流的消融实验
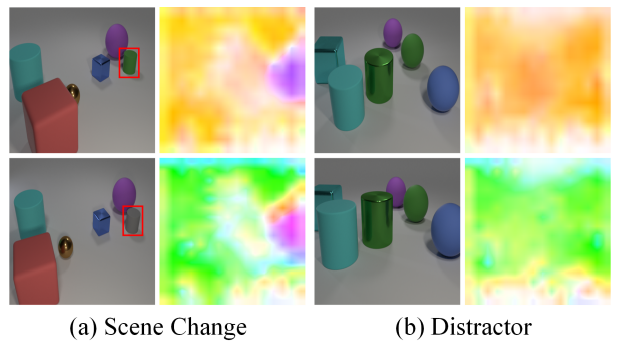
上图展示了在场景变化和视角变化干扰下预测的视角配准流场,可以有效消除图像之间的视角变化,并将发生变化的物体和仅有视角变化的区域区分开。
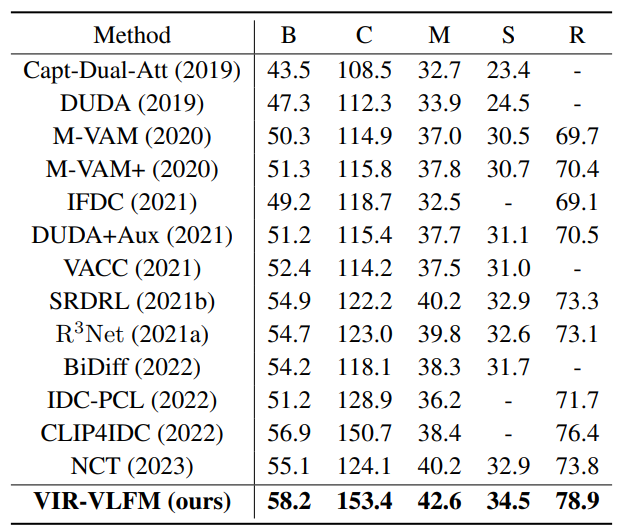
与先进方法比较
下表展示了在CLEVR-Change数据集上的实验结果。我们的方法在所有指标上都优于现有方法。这表明我们的方法有效增强了VLFMs的多图理解能力。
下图(a)中展示了图像变化描述的定性结果,我们的模型可以在大多数情境下准确描述图像之间的变化,包括颜色变化、位置移动以及物体出现或消失,但当发生变化的物体被严重遮挡时可能会出现错误描述。
值得注意的是,即使在没有使用问答数据训练的情况下,我们的模型在简单场景中展示出了回答问题的能力,如下图(b)所示。我们相信通过收集更多数据,提出模型有潜力获得更加鲁棒的多图理解能力。

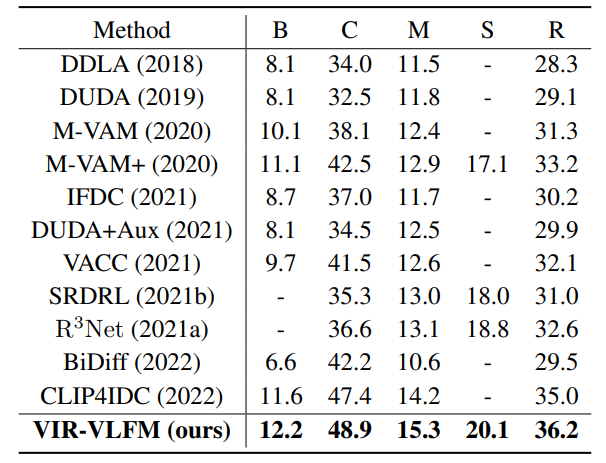
我们还在Spot-the-Diff数据集上进行了实验,结果如下表所示,提出方法在所有指标上仍然实现了最优性能。
总结
在本文中,我们提出了一种视角整合与配准方法,以增强VLFMs的多图像理解能力,使其适用于图像变化理解场景。
我们设计了一个融合adapter图像编码器,通过引入adapter和fused adapter对预训练图像编码器进行微调,以捕捉图像之间的变化信息。此外,我们还提出了一个视角配准流和一个语义增强模块,以减少视角变化引起的性能下降。
在两个数据集上的大量实验验证了我们方法的有效性。
在未来,我们将通过收集大量数据和优化模型架构来进一步增强VLFMs的多图理解能力以应对更加复杂的场景。

END
欢迎加入「大模型」交流群👇备注:LLM



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









