






关注公众号,发现CV技术之美
在数字媒体和⼈⼯智能技术飞速发展的今天,视频内容的创作和表达⽅式正经历着翻天覆地的变化。Sora的出现不仅代表了⽂本到视频转换技术的重⼤进步,更开启了视频创作的全新时代。想象⼀下,只需通过简单的⽂字描述,就能⽣成⽣动、⾼质量的视频,这将为故事讲 述、沉浸式体验和内容创作带来⾰命性的变⾰。
然⽽,这项激动⼈⼼的技术发展背后,有⼀个关键要素不容忽视——那就是“提⽰词”。提⽰词是指导视频⽣成的⽂字指令,它们对于创作出符合⽤户期望的视频⾄关重要。尽管如此,⽬前我们却⾯临⼀个问题:缺乏⼀个公开的、针对这些提⽰词进⾏研究的⼤规模数据集。为了填补这⼀空⽩,我们构建了⾸个⼤规模⽂本到视频提⽰数据集VidProM。

VidProM 数据集汇集了来⾃真实⽤户的167万个独特的提⽰词,以及由四种最先进的扩散模型⽣成的669万个视频。这些资源为视频创作者和研究⼈员提供了灵感和机会,使他们能够深⼊探索和优化视频⽣成的过程。
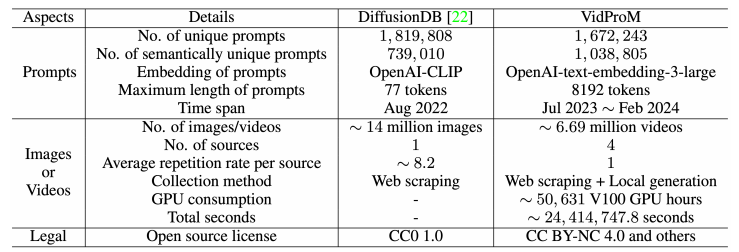
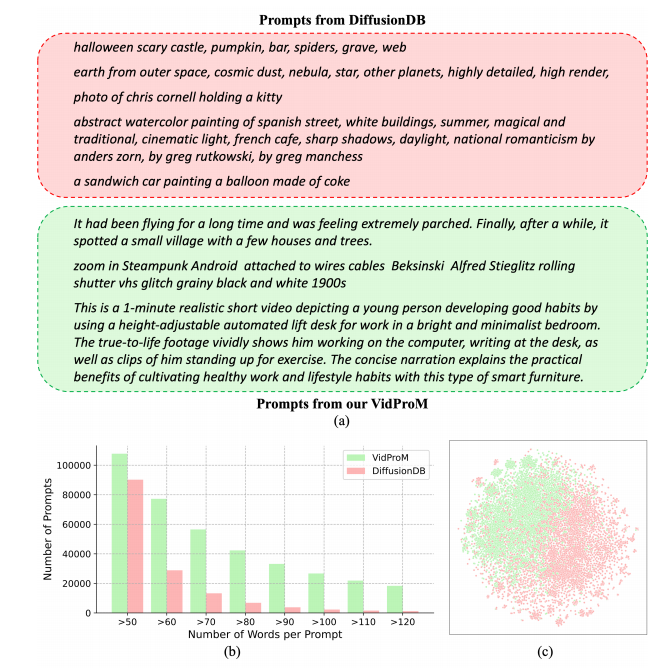
通过对VidProM的分析,我们不仅发现了⽤户在视频创作中的偏好,⽽且还揭⽰了与现有图像⽣成提⽰词数据集DiffusionDB之间的显著差异。这些发现突出了收集专门针对⽂本到视频转换的新提⽰数据集的必要性,并为未来的技术发展提供了洞察。
VidProM的推出为⽂⽣视频领域带来了新的研究⽅向和可能性。研究⼈员现在可以利⽤这个数据集来评估和改进⽂⽣视频模型,探索更⾼效的视频⽣成⽅法,以及开发专门的模型来保障视频内容的安全性和真实性。此外,这些⽂本-视频对还可以⽤于多模态学习任务,如视 频⽂本检索和视频描述,帮助缓解在线视频使⽤中的版权问题,降低收集⾼质量视频⽂本数据的难度。
通过公开分享这个资源,我们希望激发更多的创意和创新,共同推动视频⽣成技术的发展和应⽤。
论文标题:VidProM: A Million-scale Real Prompt-Gallery Dataset for Text-to-Video Diffusion Models
项⽬论⽂:https://arxiv.org/abs/2403.06098
项⽬地址:https://github.com/WangWenhao0716/VidProM
数据集公开下载地址:https://huggingface.co/datasets/WenhaoWang/VidProM

END
欢迎加入「文生视频」交流群👇备注:生成















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









