






关注公众号,发现CV技术之美
本篇分享论文Tora: Trajectory-oriented Diffusion Transformer for Video Generation,阿里提出轨迹可控的DiT视频生成模型Tora。

论文链接:https://arxiv.org/abs/2407.21705
项目链接:https://ali-videoai.github.io/tora_video/

背景
视频生成模型最近取得了显著进展。例如,OpenAI 的 Sora 和国内的 Vidu、可灵等模型,通过利用 Diffusion Transformer 的扩展特性,不仅能够满足各种分辨率、尺寸和时长的预测要求,同时生成的视频更符合物理世界的表现。
视频生成技术需要在一系列图像中创造一致的运动,这凸显了运动控制的重要性。当前已有一些优秀的方法如 DragNUWA 和 MotionCtrl 已经实现了轨迹可控的视频生成,但这些方法受限于传统 U-Net 去噪模型,大多只能生成 16 帧长度、固定低分辨率的视频,难以应对长距离轨迹。
此外,如果轨迹过于不规则或存在偏移过大等情况,这些方法十分容易出现运动模糊、外观失真和不自然的运动如漂移闪现等。
为了解决这些问题,阿里云提出了一种基于 DiT 架构的轨迹可控视频生成模型 Tora。Tora能够根据任意数量的物体轨迹,图像和文本条件生成不同分辨率和时长的视频,在 720p分辨率下能够生成长达204 帧的稳定运动视频。值得注意的是,Tora继承了DiT的scaling特性,生成的运动模式更流畅,更符合物理世界。
方法介绍
Tora 整体结构
如下图所示,Tora包括一个Spatial-Temporal Denoising Diffusion Transformer,(ST-DiT,时空去噪扩散变换器)、一个Trajectory Extractor(TE,轨迹提取器)和一个Motion-guidance Fuser(MGF,运动引导融合器)。
Tora 的 ST-DiT 继承了 OpenSora v1.2 的设计,将输入视频在时空维度上压缩成Spacetime visual patches(时空视觉补丁),再通过交替的spatial transformer block(空域变换器块) 和temporal transformer block(时域变换器块)进行噪声预测。
为了实现用户友好的轨迹控制,TE 和 MGF 将用户提供的轨迹编码为多层次的Spacetime motion patches(时空运动补丁),再通过自适应归一化层将这些patches无缝整合到每个DiT block中,以确保生成视频的运动与预定义的轨迹一致。
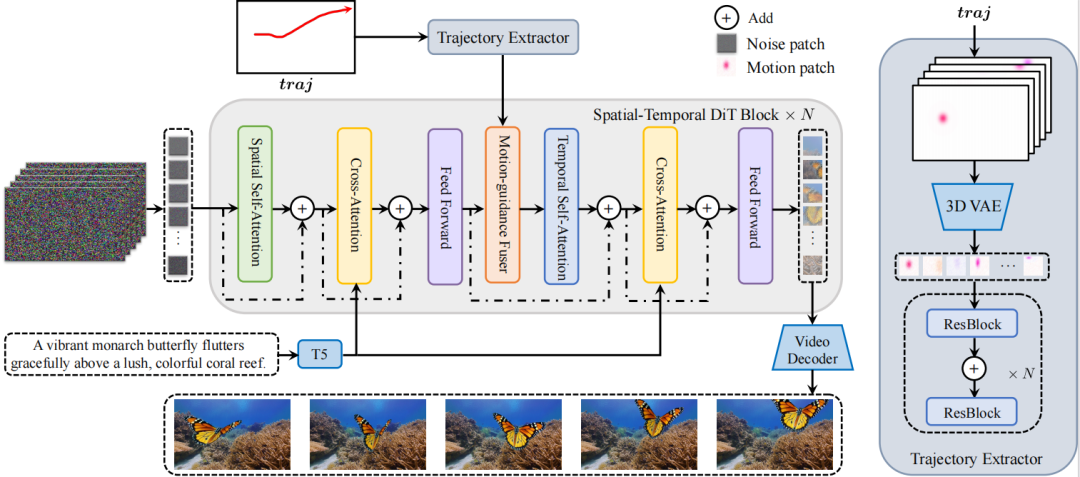
Trajectory Extractor
Sora 的技术报告中指出,visual patches(视觉补丁)是一种高度扩展且有效的表示方式。为了将高维的视频数据表示为 visual patches,Sora 将原始视频在时间和空间上均进行了压缩。这是 Sora 类的DiT算法能够生成比U-Net方法更长视频的关键。
现有的 U-Net方法往往通过注入两帧间的运动向量来控制运动轨迹,在时域上没有任何的潜在嵌入编码,这在DiT架构中并不适用。
为了将运动轨迹信息与visual patches配对,Tora的轨迹提取器采用了一个3D motion VAE(运动变分自编码器),将轨迹向量嵌入到与visual patches相同的潜在空间中,确保连续帧之间的运动信息得以保留和传递。
为了利用已有的3D VAE权重,轨迹位移通过流可视化的方案转换到 RGB 域,Tora进一步对RGB轨迹位移引入高斯滤波以减轻发散问题。RGB轨迹位移图将作为 3D motion VAE 的输入,生成motion patches。
Tora的3D motion VAE参考了谷歌提出的Magvit-v2架构并取消了码本压缩设计,通过3D因果卷积提取丰富的时空运动补丁。
如上图右侧所示,轨迹提取器继而通过堆叠的卷积块处理这些 motion patches,提取出分层次的运动特征,从而捕捉更复杂和细致的运动模式。
Motion-guidance Fuser
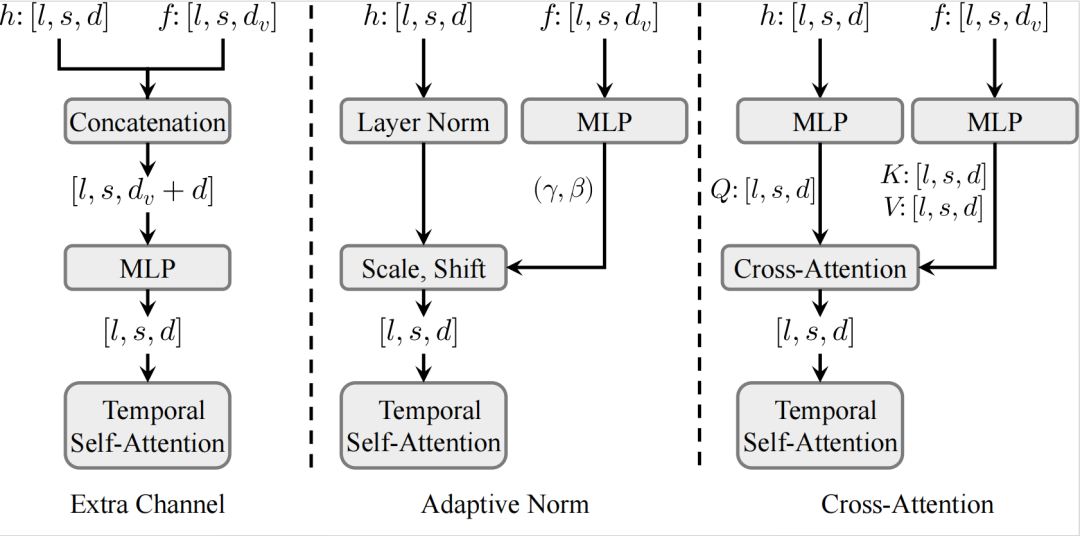
有了与visual patches共享特征空间的运动特征后,下一步需要将多层次的运动特征引入到相应的 DiT 块中,使生成的运动能够遵循预定义的轨迹,同时不影响原有的视觉效果。
Tora 参考了transformer的多种特征注入结构,如上图所示,Motion-guidance Fuser实验了包括额外通道连接、自适应归一化和交叉注意力三种架构。
实验结果显示,自适应归一化在视觉质量和轨迹跟随程度方面表现最佳,同时计算效率最高。自适应归一化层能够根据多样化的条件(文本&轨迹&图像)动态调整特征,确保视频生成的时间一致性。这在注入运动线索时尤为重要,能够有效维持视频运动的连续性和自然性。
训练数据处理与策略
为了训练 Tora 模型,需要带有描述和运动轨迹的注释视频。Tora 在 OpenSora 的数据处理流程基础上进行了改进,以更好地获取物体轨迹。
结合motion segmentation(运动分割)结果和flow score(光流分数),Tora 移除了主要包含摄像机运动的实例,从而提高了对前景物体轨迹的跟随准确率。
对于某些剧烈运动的视频,考虑其存在严重的光流偏差,它们以 (1 − score/100) 的概率被保留。筛选后的视频采用 PLLaVA13B 生成视频描述。Tora 的训练视频来源于高质量的互联网视频数据(如 Panda70M、pixabay 和 MixKit)以及公司内部数据。
为了支持任意数量的视觉条件(visual condition)引导,Tora 在训练期间随机选取visual patches,并对其取消加噪处理。在运动条件训练方面,Tora 遵循 MotionCtrl 和 DragNUWA 的两阶段训练策略。
第一阶段从训练视频中提取密集光流作为运动轨迹,提供了丰富的信息,加速了运动学习过程。
第二阶段根据motion segmentation结果和flow score,随机采样 1 到 N 条目标物体的轨迹样本,从而能够灵活地使用任意轨迹进行运动控制。
实验
实现细节与测试数据
Tora 基于 OpenSora v1.2 权重,使用分辨率从 144p 到 720p、帧数从 51 帧到 204 帧不等的视频进行训练。为平衡不同分辨率和帧数的训练 FLOP和所需内存,批次大小调整为 1 到 25。
训练过程分为两个阶段,首先使用密集光流进行 2 个 epoch 的训练,然后使用稀疏光流进行 1 个 epoch 的微调。
在推理过程中,精选了 185 个包含多样化运动轨迹和场景的长视频片段,作为评估运动可控性的新基准。
对比实验结果
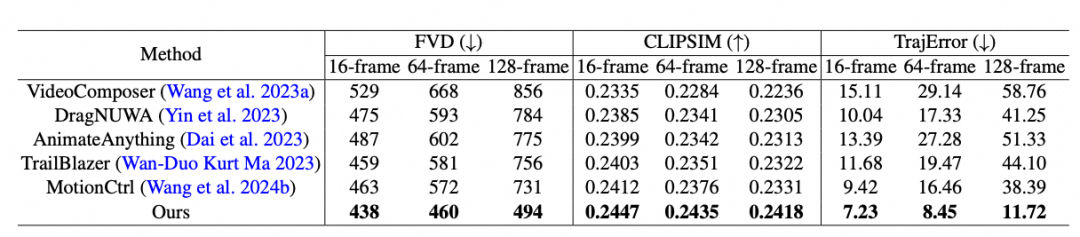
作者团队将 Tora 与当前流行的运动引导视频生成方法进行对比,在 16、64 和 128 帧三个设置下评估,所有视频分辨率均为 512×512,以确保公平对比,测试轨迹依据视频帧数进行相应的切分。
对于大多数基于 U-Net 的方法采用顺次推理方式,即前一个批次生成的最后一帧作为当前批次的条件。在 U-Net常用的16帧设置下,MotionCtrl 和 DragNUWA 与提供的轨迹对齐效果较好,但仍不如 Tora。随着帧数增加,基于U-Net的方法出现严重地误差累计传播,导致后续序列中出现变形、模糊或物体消失问题。
相反,Tora 由于集成了 transformer的 scaling 能力,对帧数变化表现出高度鲁棒性,生成的运动更平滑且符合物理世界规律。在 128 帧测试下,Tora 的轨迹准确度比其他方法高出 3 至 5 倍。
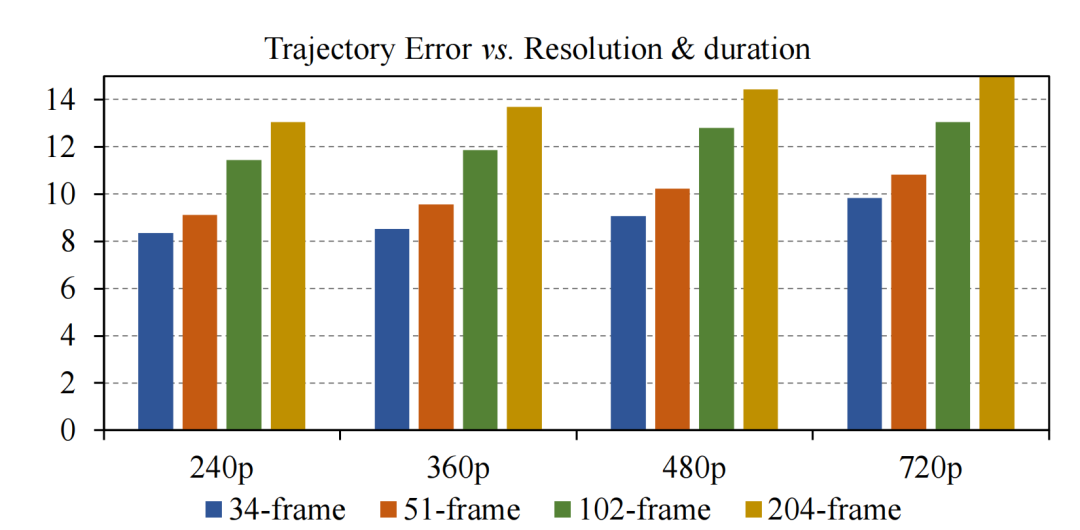
作者团队提供了Tora不同分辨率和时长下的轨迹误差分析,显示 Tora 随时长增加仅表现出逐渐的误差增加,这与DiT模型在延长视频时质量下降的趋势一致,这表明 Tora 在更长时间内保持了有效的轨迹控制。
更多实验结果
下方视频为16:9尺寸下的单轨迹对应多文本实例效果 。
下方视频为9:16尺寸下的单轨迹对应多文本实例与1:1尺寸下的单图像对应多轨迹实例效果。
最新 AI 进展报道
请联系:amos@52cv.net

END
欢迎加入「视频生成」交流群👇备注:生成



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









