






关注公众号,发现CV技术之美
本文转自机器之心。
Transformer 在深度学习领域取得巨大成功的关键是注意力机制。注意力机制让基于 Transformer 的模型关注与输入序列相关的部分,实现了更好的上下文理解。然而,注意力机制的缺点是计算开销大,会随输入规模而二次增长,Transformer 也因此难以处理非常长的文本。
前段时间,Mamba 的出现打破了这一局面,它可以随上下文长度的增加实现线性扩展。随着 Mamba 的发布,这些状态空间模型 (SSM) 在中小型规模上已经可以与 Transformer 匹敌,甚至超越 Transformer,同时还能维持随序列长度的线性可扩展性,这让 Mamba 具有有利的部署特性。
简单来说,Mamba 首先引入了一个简单却有效的选择机制,其可根据输入对 SSM 进行重新参数化,从而可让模型在滤除不相关信息的同时无限期地保留必要和相关的数据。
最近,一篇题为《The Mamba in the Llama: Distilling and Accelerating Hybrid Models》的论文证明:通过重用注意力层的权重,大型 transformer 可以被蒸馏成大型混合线性 RNN,只需最少的额外计算,同时可保留其大部分生成质量。
由此产生的混合模型包含四分之一的注意力层,在聊天基准测试中实现了与原始 Transformer 相当的性能,并且在聊天基准测试和一般基准测试中优于使用数万亿 token 从头开始训练的开源混合 Mamba 模型。此外,该研究还提出了一种硬件感知推测解码算法,可以加快 Mamba 和混合模型的推理速度。

论文地址:https://arxiv.org/pdf/2408.15237
该研究的性能最佳模型是从 Llama3-8B-Instruct 中蒸馏出来的,在 AlpacaEval 2 上相对于 GPT-4 实现了 29.61 的长度控制(length-controlled)胜率,在 MT-Bench 上实现了 7.35 的胜率,超越了最好的指令调整线性 RNN 模型。
方法
知识蒸馏(KD)作为一种模型压缩技术,用于将大型模型(教师模型)的知识迁移到较小的模型(学生模型)中,旨在训练学生网络模仿教师网络的行为。该研究旨在对 Transformer 进行蒸馏,使其性能与原始语言模型相当。
该研究提出了一种多级蒸馏方法,结合了渐进式蒸馏、监督微调和定向偏好优化。与普通蒸馏相比,这种方法可以获得更好的困惑度和下游评估结果。
该研究假设来自 Transformer 的大部分知识都保留在从原始模型迁移而来的 MLP 层中,并专注于蒸馏 LLM 的微调和对齐步骤。在此阶段,MLP 层保持冻结状态,Mamba 层进行训练。
该研究认为线性 RNN 和注意力机制之间天然存在一些联系。通过删除 softmax 可以线性化注意力公式:
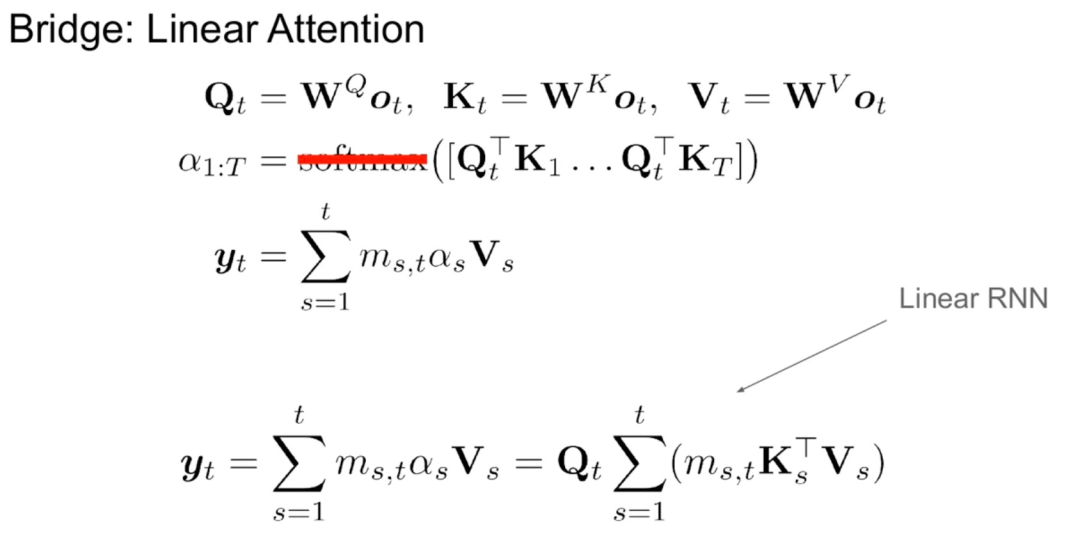
但线性化注意力会导致模型能力退化。为了设计一个有效的蒸馏线性 RNN,该研究尽可能接近原始 Transformer 参数化,同时以有效的方式扩展线性 RNN 的容量。该研究没有尝试让新模型捕获精确的原始注意力函数,而是使用线性化形式作为蒸馏的起点。
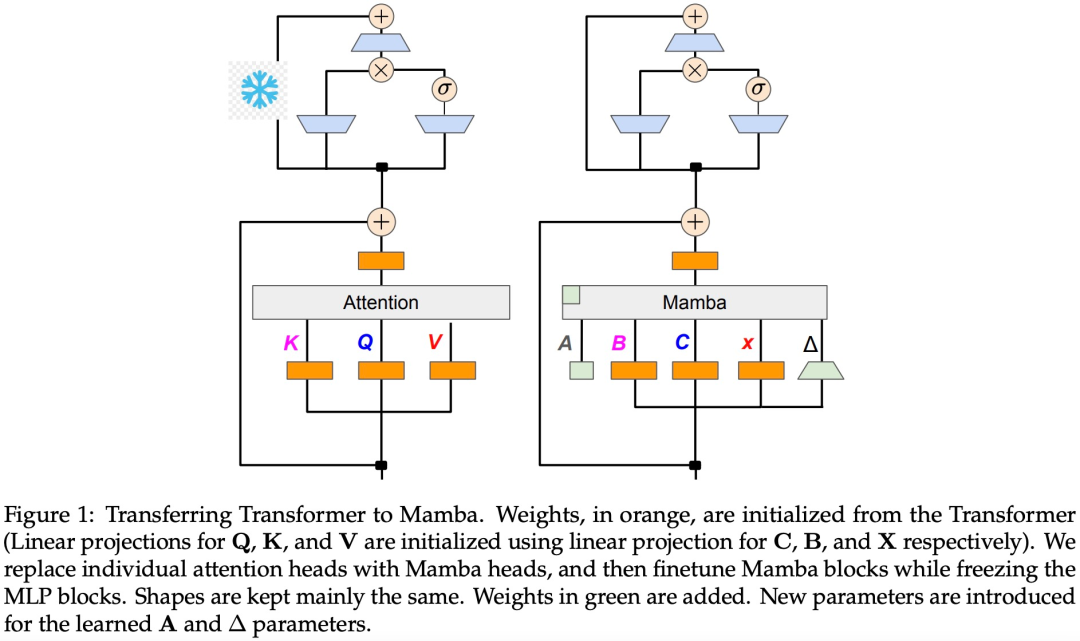
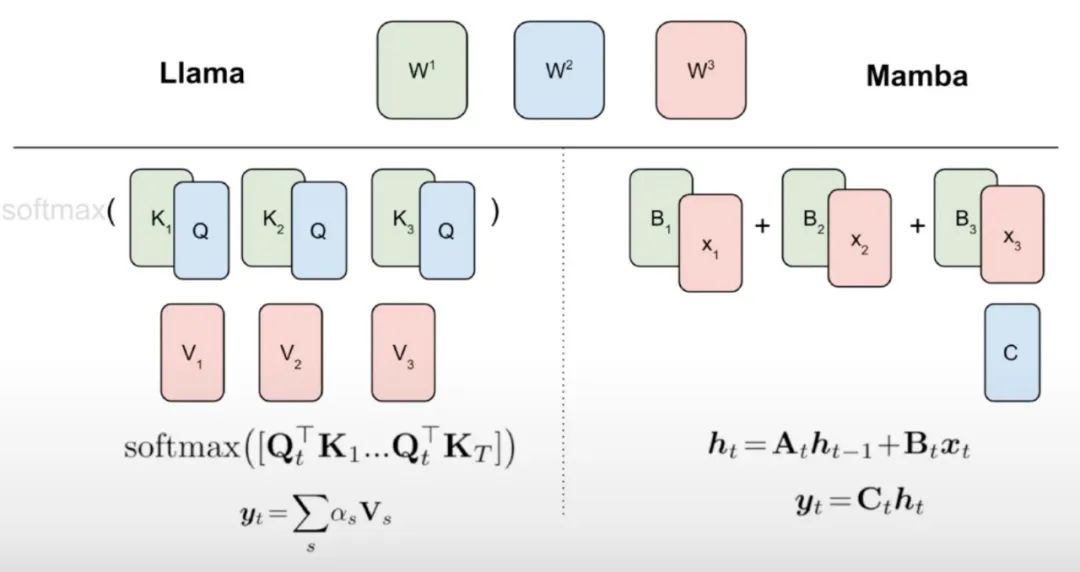
如算法 1 所示,该研究将来自注意力机制的标准 Q、K、V 头直接馈入到 Mamba 离散化中,然后应用得到的线性 RNN。这可以看作是使用线性注意力进行粗略初始化,并允许模型通过扩展的隐藏状态学习更丰富的交互。

该研究用微调线性 RNN 层直接替换 Transformer 注意力头,保持 Transformer MLP 层不变,不训练它们。这种方法还需要处理其他组件,例如跨头共享键和值的分组查询注意力。研究团队注意到,这种架构与许多 Mamba 系统中使用的架构不同,这种初始化允许用线性 RNN 块替换任何注意力块。
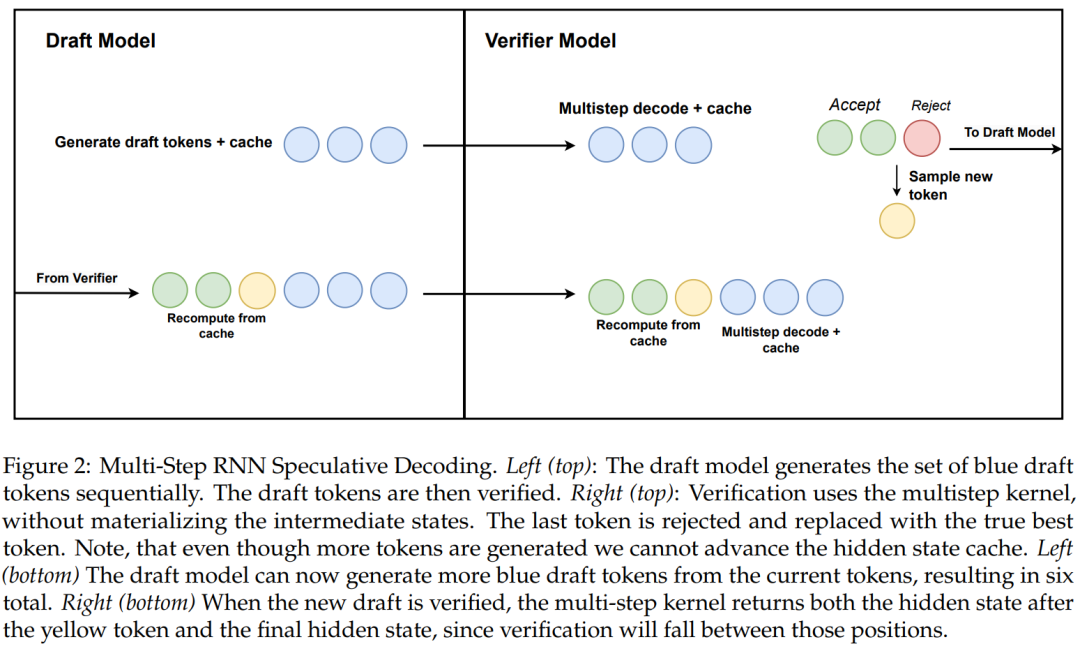
该研究还提出了一种使用硬件感知多步生成的线性 RNN 推测解码新算法。
算法 2 和图 2 显示了完整的算法。该方法仅在缓存中保留一个 RNN 隐藏状态以进行验证,并根据多步内核的成功来延迟推进它。由于蒸馏模型包含 transformer 层,该研究还将推测解码扩展到 Attention/RNN 混合架构。在此设置中,RNN 层根据算法 2 执行验证,而 Transformer 层仅执行并行验证。

为了验证这种方法的有效性,该研究使用 Mamba 7B 和 Mamba 2.8B 作为目标模型进行推测。结果如表 1 所示。
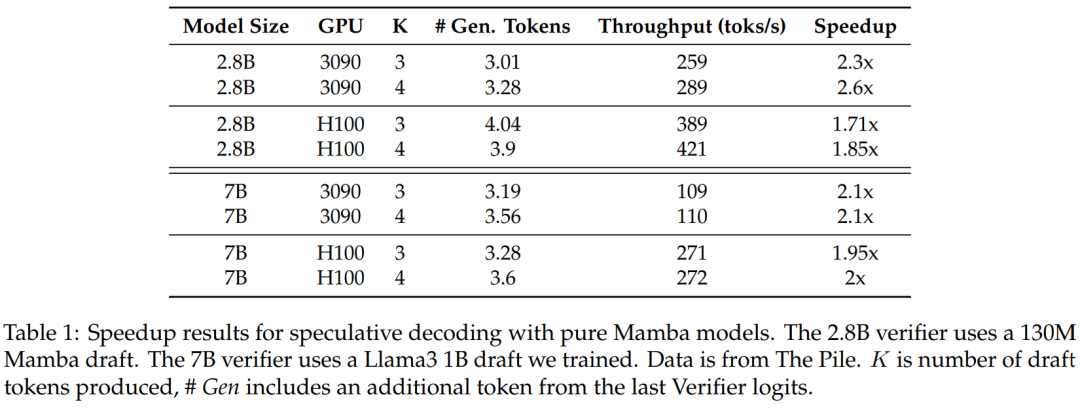
图 3 显示了多步内核本身的性能特征。
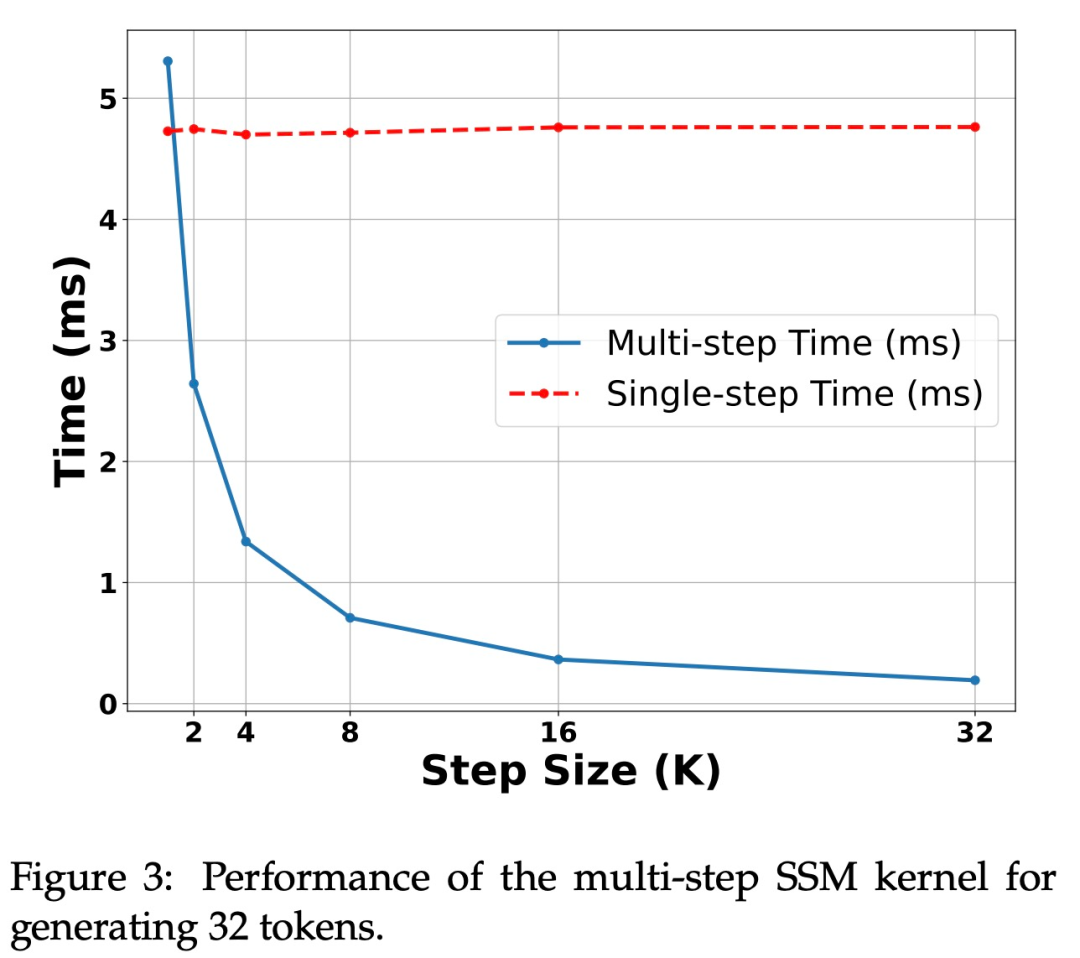
H100 GPU 上的加速。该研究提出的算法在 Ampere GPU 上表现出强大的性能,如上表 1 所示。但在 H100 GPU 上面临巨大挑战。这主要是因为 GEMM 操作速度太快,这使得缓存和重新计算操作产生的开销更加明显。实际上,该研究的算法的简单实现(使用多个不同的内核调用)在 3090 GPU 上实现了相当大的加速,但在 H100 上根本没有加速。
实验及结果
该研究使用两个 LLM 聊天模型进行实验:Zephyr-7B 是在 Mistral 7B 模型的基础上微调而来, 以及 Llama-3 Instruct 8B。对于线性 RNN 模型,该研究使用 Mamba 和 Mamba2 的混合版本,其中注意力层分别为 50%、25%、12.5% 和 0%,并将 0% 称为纯 Mamba 模型。Mamba2 是 Mamba 的一种变体架构,主要针对最近的 GPU 架构而设计。
在聊天基准上的评估
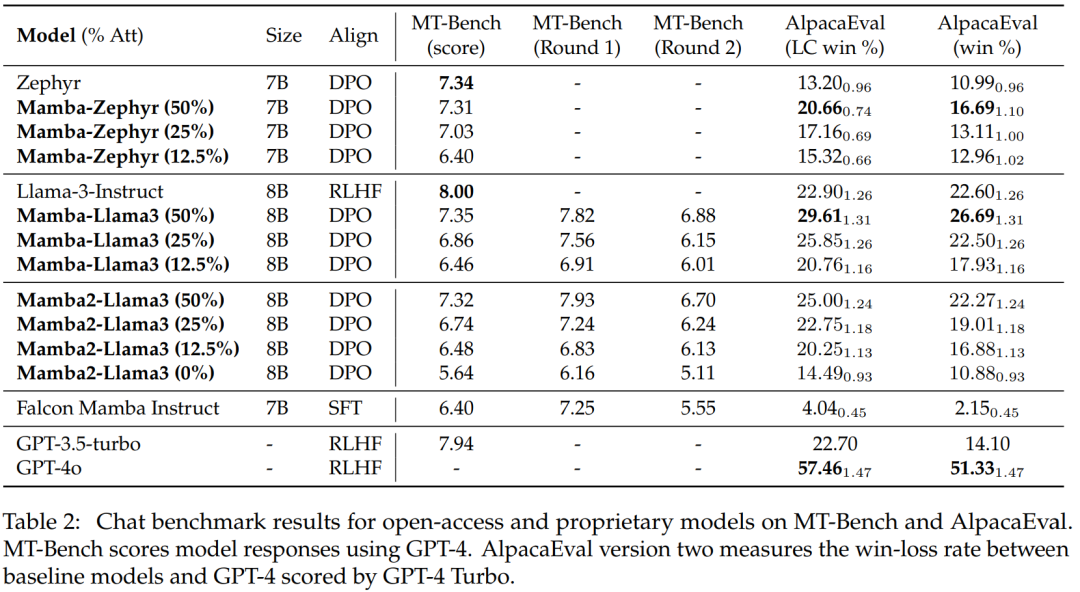
表 2 显示了模型在聊天基准上的性能,主要对比的模型是大型 Transformer 模型。结果显示:
蒸馏后的混合 Mamba 模型 (50%) 在 MT 基准测试中取得的分数与教师模型相似,在 LC 胜率和总体胜率方面都略优于 AlpacaEval 基准测试中的教师模型。
蒸馏后的混合 Mamba (25% 和 12.5%) 的性能在 MT 基准测试中略逊于教师模型,但即使在 AlpcaaEval 中具有更多参数,它仍然超越了一些大型 Transformer。
蒸馏后的纯 (0%) Mamba 模型的准确性确实显著下降。
值得注意的是,蒸馏后的混合模型的表现优于 Falcon Mamba,后者是从头开始训练的,使用了超过 5T 的 token。
一般基准评估
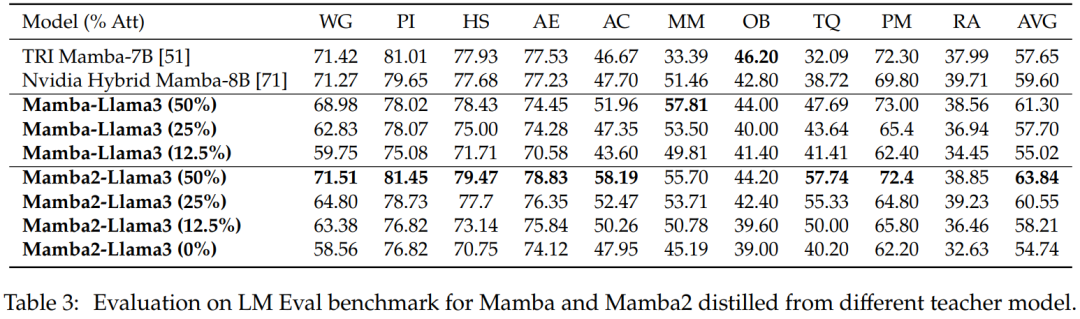
零样本评估。表 3 显示了从不同教师模型中蒸馏出的 Mamba 和 Mamba2 在 LM Eval 基准中的零样本性能。从 Llama-3 Instruct 8B 中蒸馏出的混合 Mamba-Llama3 和 Mamba2-Llama3 模型与从头开始训练的开源 TRI Mamba 和 Nvidia Mamba 模型相比表现更好。
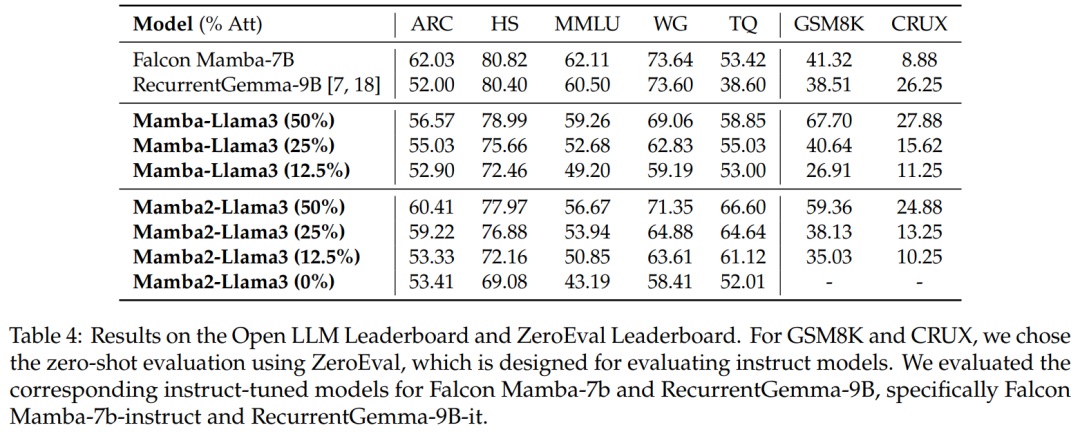
基准评估。表 4 显示经过蒸馏的混合模型的性能与 Open LLM Leaderboard 上最好的开源线性 RNN 模型相匹配,同时在 GSM8K 和 CRUX 中优于相应的开源指令模型。
混合推测性解码
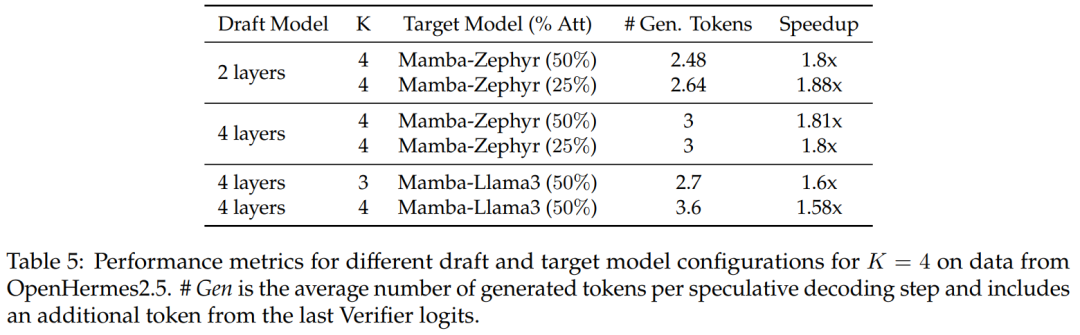
对于 50% 和 25% 的蒸馏模型,与非推测基线相比,该研究在 Zephyr-Hybrid 上实现了超过 1.8 倍的加速。
实验还表明,该研究训练的 4 层 draft 模型实现了更高的接收率,不过由于 draft 模型规模的增加,额外开销也变大了。在后续工作中,该研究将专注于缩小这些 draft 模型。
与其它蒸馏方法的比较:表 6(左)比较了不同模型变体的困惑度。该研究在一个 epoch 内使用 Ultrachat 作为种子提示进行蒸馏,并比较困惑度。结果发现删除更多层会使情况变得更糟。该研究还将蒸馏方法与之前的基线进行了比较,发现新方法显示出较小的退化,而 Distill Hyena 模型是在 WikiText 数据集中使用小得多的模型进行训练的,并且显示出较大的困惑度退化。
表 6(右)展示了单独使用 SFT 或 DPO 不会产生太大的改进,而使用 SFT + DPO 会产生最佳分数。
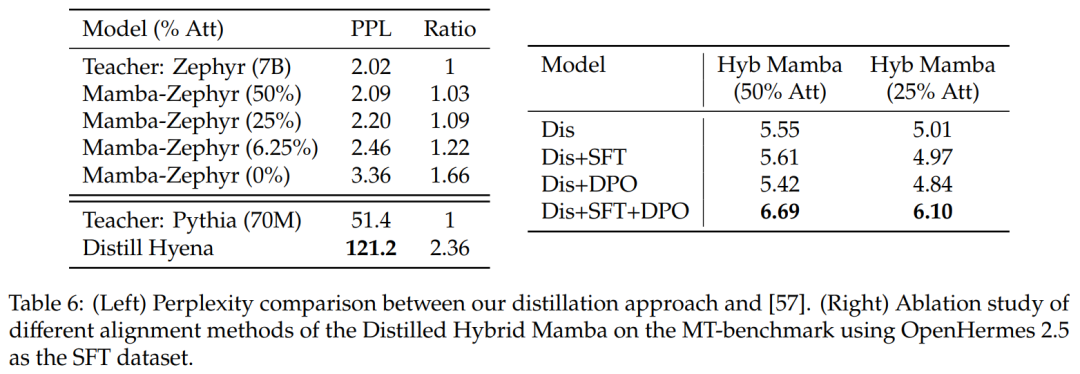
表 7 比较了几种不同模型的消融研究。表 7(左)展示了使用各种初始化的蒸馏结果,表 7(右)显示渐进式蒸馏和将注意层与 Mamba 交错带来的收益较小。
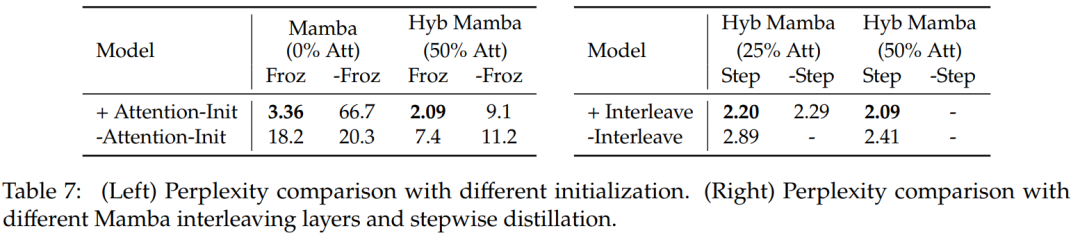
表 8 比较了使用两种不同初始化方法的混合模型的性能:结果证实注意力权重的初始化至关重要。

表 9 比较了有 Mamba 块和没有 Mamba 块的模型的性能。有 Mamba 块的模型性能明显优于没有 Mamba 块的模型。这证实了添加 Mamba 层至关重要,并且性能的提高不仅仅归功于剩余的注意力机制。

感兴趣的读者可以阅读论文原文,了解更多研究内容。

END
加入「计算机视觉」交流群👇备注:CV
















 804
804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









