






关注公众号,发现CV技术之美
论文 FastScene: Text-Driven Fast 3D Indoor Scene Generation via Panoramic Gaussian Splatting已被国际人工智能顶级学术会议IJCAI-2024主会收录,由中山大学智能工程学院完成。论文第一作者为2023级硕士研究生马义坤,通讯作者为其导师金枝副教授。

原文链接:https://arxiv.org/abs/2405.05768
Code:https://github.com/Mr-Ma-yikun/FastScene
三维模型在虚拟现实增强、游戏电影行业、智能家居等有着广泛应用。生成式模型的发展使得建立三维模型更加便捷,例如根据文本或图像生成三维物体。然而三维场景的生成仍具有较大挑战性。
该工作提出了一种新颖的三维场景快速生成方法,基于文本提示,利用全景图和空间运动约束,提出了渐进式全景修复策略,旨在得到高质量的多视角图像。此外,设计了全景图的高斯训练方法,能够更好的解决高斯泼溅无法处理非透视视角的问题。
Abstract
本文提出了一种快捷有效的3D室内场景生成算法,称为FastScene。对于用户,只需要输入一段描述室内的文本,便能快速且高质量的生成3D高斯场景。
本文的贡献与创新点如下:
提出了一个新颖的文本到3D室内场景生成框架FastScene,能够较为快速且高质量的生成3D高斯场景,且不需要预定义相机参数和运动轨迹,是一种友好的场景生成范式。
提出了一种渐进式的全景图新视角修复算法PNVI,能够逐渐得到不同视角的干净全景图。并且合成了一个大规模的球面掩码数据集。
通过引入多视角投影策略,解决了3D高斯无法使用全景图重建的问题。
Method
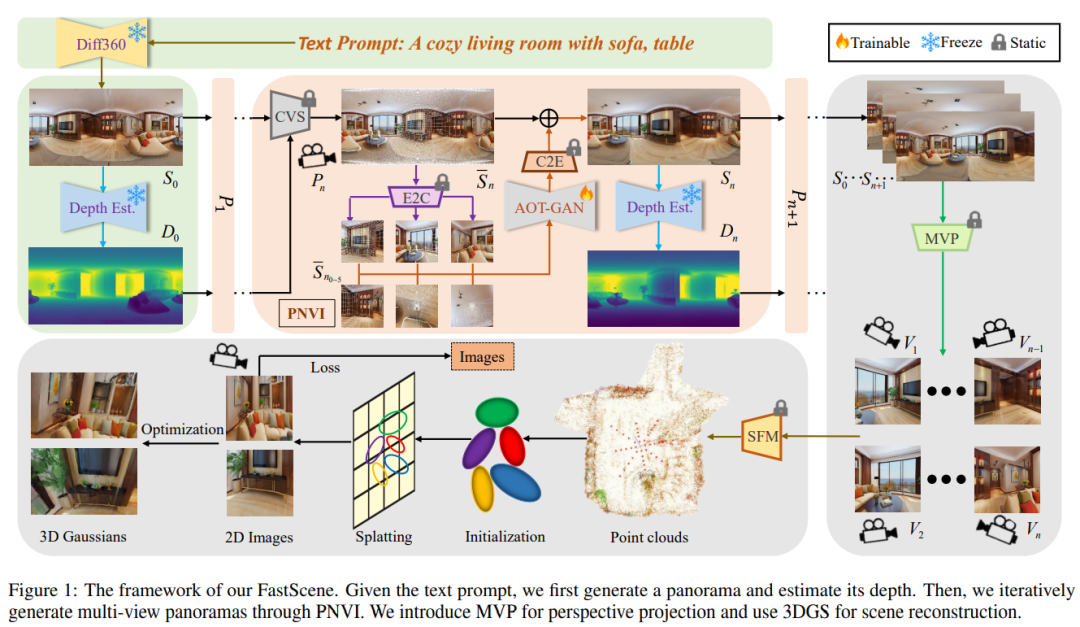
Network Architecture
图1给出了本文所提出的FastScene框架,包括:根据文本生成全景图与粗视角合成、渐进式新视角全景图修复、以及使用全景图进行3D高斯重建。
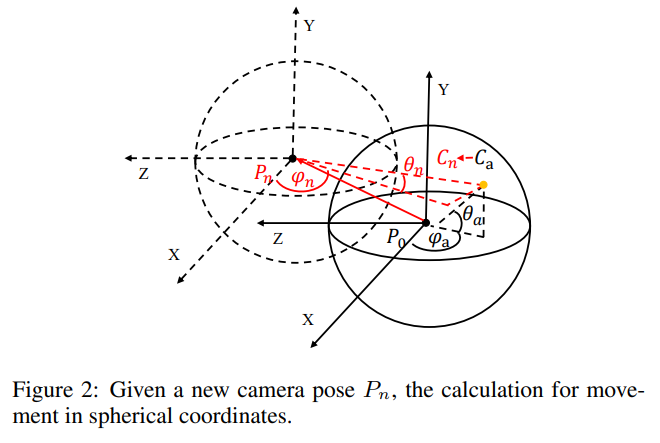
文本生成全景图与粗视角合成。与透视视角相比,全景图的一个关键几何特性是边界的连续性。此外,全景图囊括了整个场景表面的信息,相比透视图具有更加显式的几何约束。因此,我们选择全景图作为本文的操作对象。具体来说,首先输入一段文本,例如“一个带有沙发和桌子的舒适的客厅”,然后使用Diffusion360算法生成一张具有连续边界的全景图。然后,我们使用EGformer估计其深度,从而得到空间的立体信息。
为了得到不同位姿下的新视角,我们设计了粗视角合成策略(图2)。首先根据全景图坐标计算每个点的经纬角度:
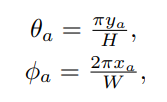
然后,根据这两种角度,计算三维球面基坐标:
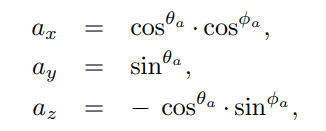
因此三维球面坐标可以表示为基坐标与深度值的相乘:
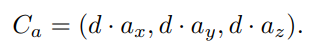
对于移动后的新坐标系,其基坐标可以用原坐标系表示为:
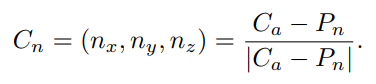
那么,新坐标系下的全景坐标可以表示为:
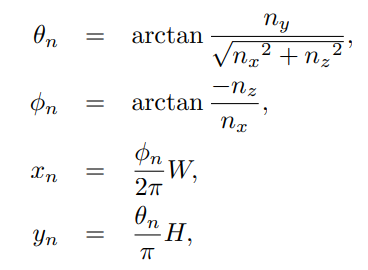
因此,接下来只需要判断哪些点位于有效坐标范围,并将无效坐标设为mask,从而得到带有孔洞的新视角全景图:
渐进式全景修复。 得到了带有Mask的全景图后,我们希望修复它获得干净视角。然而,
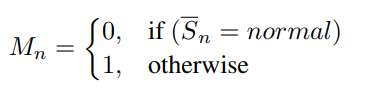
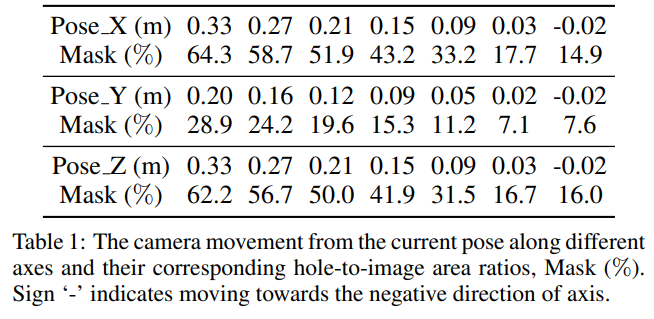
当我们尝试直接对大距离的全景图修复时,由于无效像素过多,因此修复质量并不理想。如表1所示,直接移动0.33m的孔洞占比为64.3%,这是不利于修复的。因此我们将大距离的移动划分为多个小微元的移动叠加,例如每次只移动0.02m。
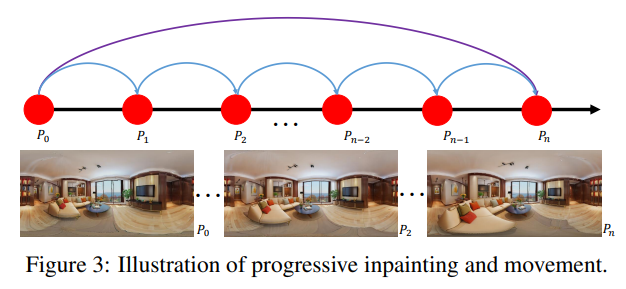
此外,我们发现直接对全景图修复,随着移动步数的增加,容易造成扭曲和伪影。因此我们提出使用等距投影,将全景图投影到六张cubemap图像,然后进行修复。
全景3D高斯重建。 得到了多视角的干净的全景图后,我们希望我使用3D高斯重建场景。3D高斯需要先使用COLMAP,从输入视角重建稀疏点云。然而,现在有的COLMAP架构只能处理透视视角输入,无法处理全景图结构。因此,我们引入了一种多视角投影策略,根据用户需求,将全景图投影为多张透视视角,继而使用COLMAP进行稀疏点云重建。图4表明,经过我们的多视角投影策略,可以较好的重建出场景与位姿:

Experiments
Main Results
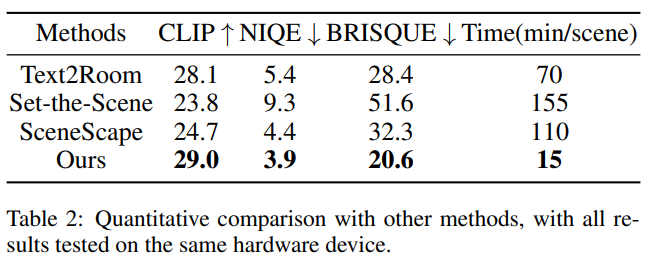
表2给出了FastScene和其它三维场景生成模型的对比,我们选择CLIP评分、NIQE以及BRISQUE作为评价指标。从表中可以发现,我们的方法不仅具有较好的指标评估性能,且生成速较快。
此外,为了更全面的展示我们的方法的性能,我进行了了定性的评估:

图5给出了不同场景生成方法的渲染视角的视觉效果对比,可以看到:我们的FastScene不仅生成的视角质量较高,且场景连续性也能够较好的保证。
更多的实验结果和实验细节,欢迎阅读我们的论文原文以及补充材料。
Ablation Studies
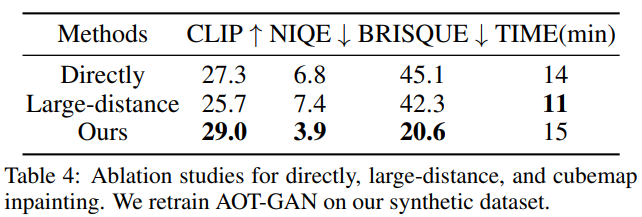
为了验证我们的渐进式全景视角合成策略的有效性,我们设计了两组消融实验:
直接对全景图修复。我们首先在合成的全景数据集上重新训练AOT-GAN。然而,我们发现小距离移动下的修复结果较好。但随着移动步数增加,图像扭曲和畸变越来越严重,我们认为这是由于移动过程中不可避免的深度估计误差以及全景特殊的形状结构导致的。
直接修复大距离移动的全景图。我们直接对大距离移动下全景图进行修复,由于其具有较大的孔洞占比,因此难以得到干净的图像。
表4和图8的对比结果可以进一步验证我们的渐进式修复方法的有效性。

中山大学智能工程学院的前沿视觉实验室( FVL: https://fvl2020.github.io/fvl.github.com/ )由学院金枝副教授建设并维护,实验室目前聚焦在图像/视频质量增强、视频编解码、3D 重建和无接触人体生命体征监测等领域的研究。
旨在优化从视频图像的采集、传输到增强以及服务后端应用的完整周期。我们的目标是开发通用的概念和轻量化的方法。为了应对这些挑战,我们将持之以恒地进行相关的研究,并与其他实验室进行合作,希望利用更多关键技术,解决核心问题。长期欢迎有志之士加入我们!
最新 AI 进展报道
请联系:amos@52cv.net

END
欢迎加入「3D场景」交流群👇备注:3D



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









