






关注公众号,发现CV技术之美
本篇分享最新综述The Role of World Models in Shaping Autonomous Driving: A Comprehensive Survey,世界模型如何推动自动驾驶。

论文链接:https://arxiv.org/abs/2502.10498
最新汇总论文:https://github.com/LMD0311/Awesome-World-Model
背景
驾驶世界模型(Driving World Models, DWM)是预测驾驶场景演化的关键技术,能够帮助自动驾驶系统感知、理解并与动态驾驶环境交互。
近年来,DWM 在提升自动驾驶安全性和可靠性方面的重要性日益凸显。然而,现有研究仍面临诸多挑战,包括多模态数据的高效融合、稀缺数据场景的建模以及模型在复杂场景中的鲁棒性。
为此,本文对DWM 的研究现状进行了全面梳理,系统性总结了方法分类、应用场景、数据集与指标,并深入探讨了未来研究方向,为研究者提供了宝贵的参考。
此外,本文还公开了一个名为Awesome World Models for Autonomous Driving的GitHub仓库,现在已经收获超700 star,并保持持续更新。
核心内容
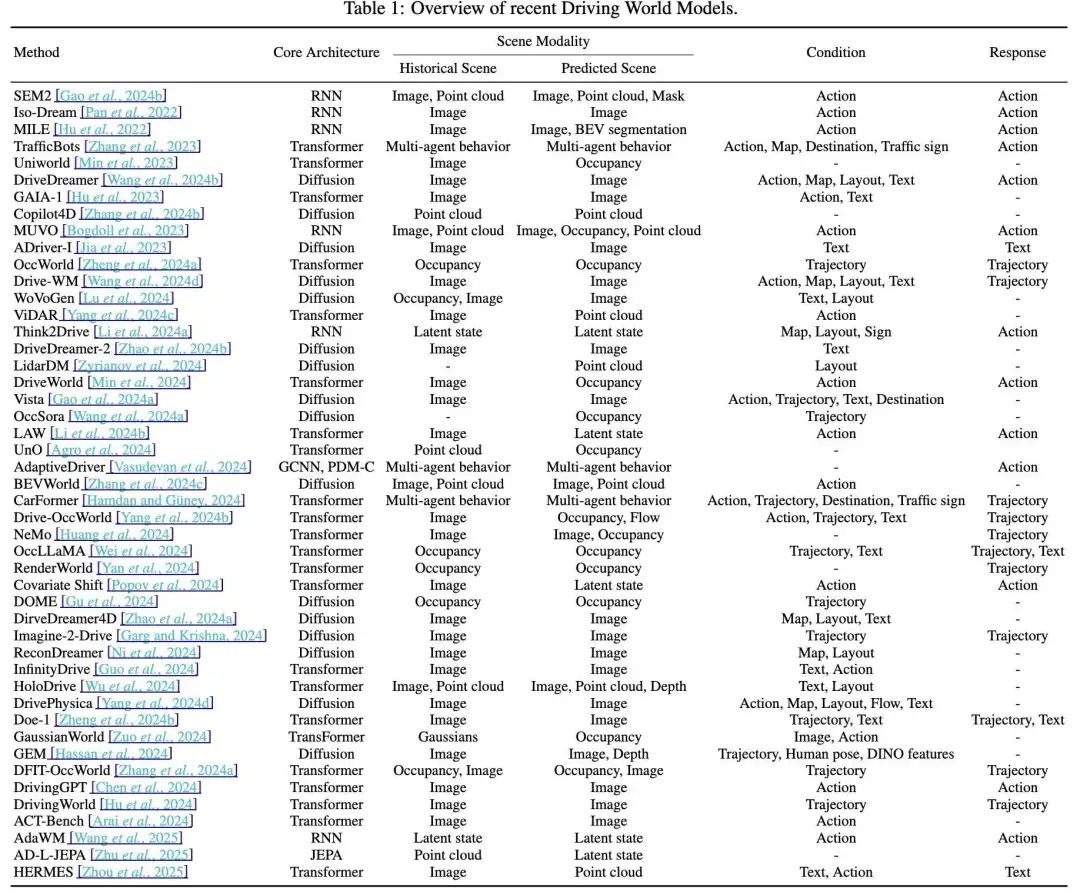
1. 方法分类与最新进展
本综述系统性地对 DWM 方法进行了分类,涵盖了 2D 场景、3D 场景和无场景范式,并详细介绍了每种方法的核心技术和最新进展:
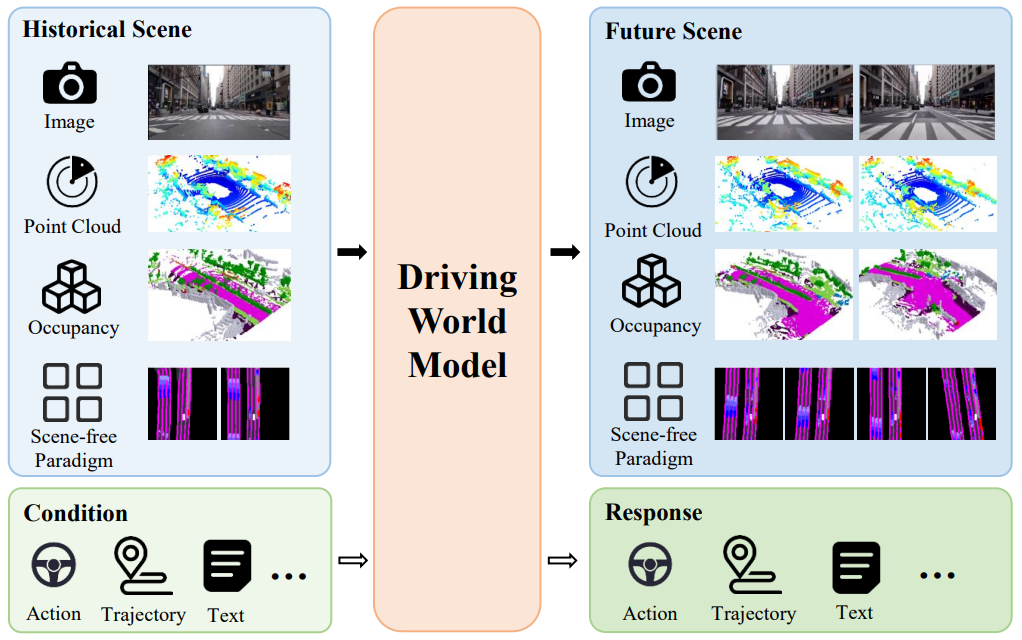
2D 场景演化
2D 场景方法主要利用生成技术(如自回归 Transformer 和diffusion模型)生成高保真、物理一致的驾驶场景:
时空动态捕获:GAIA-1 通过diffusion解码器捕获驾驶场景中的时空动态和高层结构。
多模态控制:DriveDreamer 扩展了条件diffusion框架,支持多模态控制和合成数据生成。
一致性提升:Vista 通过stable video diffusion 和新颖的损失函数,提升了场景生成的结构完整性和动态合理性。
3D 场景演化
3D 场景方法利用occupancy和点云数据,捕获精确的空间几何关系和动态信息:
Occupancy生成 OccWorld 使用时空 Transformer 生成未来场景和自车位姿,确保全局一致性。
点云生成:Copilot4D 通过离散diffusion实现高效的点云生成和预测。
基于视觉的3D生成:ViDAR 从多视图图像预测未来点云演变,捕捉语义、3D结构和时间动态的协同学习。
多模态融合:BEVWorld 将图像和点云数据融合为统一的鸟瞰视图(BEV)表示,生成未来场景并支持自监督学习。
无场景(Scene-free)范式
无场景方法不关注细致的场景预测,而是关注潜在状态的预测或多智能体行为的建模,提升自动驾驶系统的效率和泛化能力:
潜在状态预测:Think2Drive使用DWM预测未来的潜在状态,与想象的环境进行并行化的高效交互,从而提升规划性能。
多智能体行为建模:TrafficBots 从预测多智能体的行为,模拟现实驾驶场景中的复杂交互。
2. 应用场景
DWM在自动驾驶中的应用场景广泛,涵盖仿真、数据生成、预测与规划以及4D预训练等多个方面:
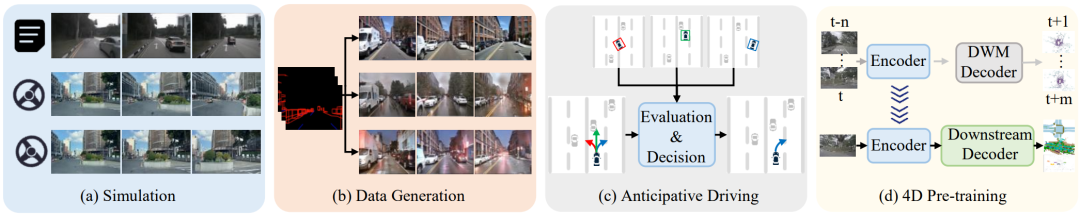
仿真
DWM通过生成多样化、高保真的驾驶场景,支持自动驾驶模型的训练与评估。如Vista提供高保真的视频仿真,支持动作评估;ACT-Bench关注动作保真度,准确遵守condition的控制;TrafficBots模拟多智能体行为,提升动作仿真真实性。
数据生成
DWM通过合成多样化的数据,弥补真实数据的不足。例如,DrivePhysica生成高质量驾驶视频,LidarDM生成真实的点云数据,增强下游任务(如3D检测)的性能。此外,DriveDreame4D还能合成新的驾驶行为视频,强化下游模型对长尾场景的适应能力。
预见性规划
DWM通过未来场景预测优化车辆规划与决策。例如,DriveWM结合奖励函数选择最优轨迹,ADriver-I通过多模态预测实现长时间规划。也可以将场景预测与训练过程结合,例如AdaWM通过对比预测场景和真实场景的差异来进行微调,LAW通过监督场景预测和未来真实场景一致以强化端到端规划。
4D预训练
利用多模态数据进行自监督学习,DWM提升了下游任务性能并降低了对人工标注的依赖。例如,ViDAR通过视觉点云预测学习3D几何信息,BEVWorld在多传感器数据上进行统一的BEV表示预训练。
3. 数据集与评估指标
高质量的数据集和科学的评估指标是推动 DWM 研究的重要基石。本综述全面梳理了 DWM 领域的主流数据集和常用指标:
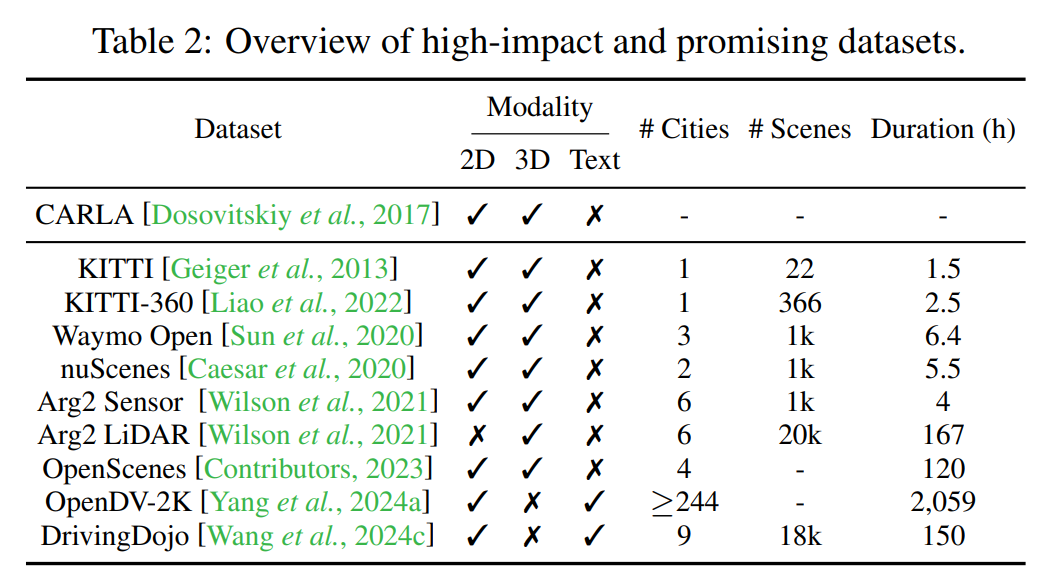
多模态数据集:如 nuScenes、Waymo Open Dataset,涵盖图像、点云和 occupancy 等多种模态。
定制化数据集:如 DrivingDojo 专为 DWM 训练设计,包含复杂的驾驶动态场景。
评估指标:DWM的评估指标因任务不同而多样化,主要包括生成指标和规划指标:
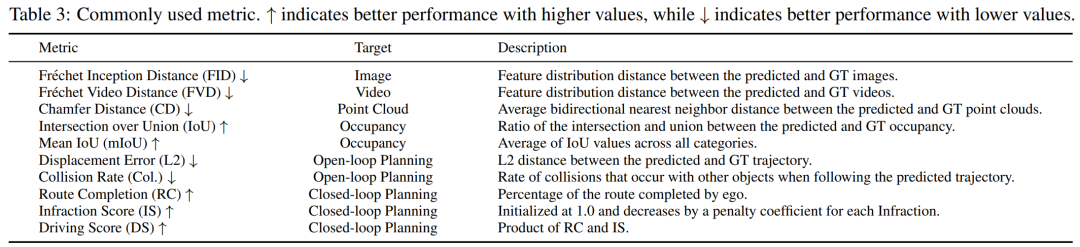
生成质量:如FID(Fréchet Inception距离)、FVD(Fréchet视频距离)等衡量生成数据与真实数据的分布差异。
规划性能:如Collision Rate(碰撞率)、Driving Score(驾驶得分)等评估模型在规划任务中的表现。
一致性与可控性:除了通用的生成与规划指标外,DWM还需考虑预测场景演变的时空一致性和可控性。为此提出了一些指标,如关键点匹配(KPM)和对象操作控制(COM)。
4. 当前挑战与未来方向
尽管DWM取得了显著进展,但仍面临以下挑战:
数据稀缺:高质量、多模态对齐数据的采集成本高昂,如何通过合成数据弥补数据不足是开放问题。
运行效率:生成任务的高计算成本限制了实时应用,未来需要探索更高效的表示方法和模型架构。
高质量仿真:进一步提高仿真的真实度,解决退化、幻觉等问题,为研究者提供值得信任的依据。
统一任务框架:预测与规划、感知结合以相互促进;与规划结合以联合优化,统一的DWM任务框架具有广阔研究前景。
多模态建模:现有方法对多模态数据的融合仍不充分,未来可探索非对齐甚至非配对数据的有效利用。
对抗攻击与防御:针对DWM的对抗攻击研究较少,开发防御策略以确保驾驶安全性至关重要。
总结与展望
Driving World Models作为自动驾驶领域的核心技术,正在推动感知、预测与规划的深度融合。
本综述不仅回顾了DWM的研究进展,还系统性地总结了应用、数据集和指标,并指出了当前的限制与未来的研究机遇。
我们相信,这篇综述将为DWM领域的初学者提供充实的资料,为研究者和工程师提供有价值的结论和观点,加速自动驾驶技术的发展。
最新 AI 进展报道
请联系:amos@52cv.net

END
欢迎加入「自动驾驶」交流群👇备注:AD



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









