






关注公众号,发现CV技术之美
在文档理解领域,多模态大模型(MLLMs)正以惊人的速度进化。从基础文档图像识别到复杂文档理解,它们在扫描或数字文档基准测试(如 DocVQA、ChartQA)中表现出色,这似乎表明MLLMs已很好地解决了文档理解问题。 然而,现有的文档理解基准存在两大核心缺陷:
脱离真实场景:现实中文档多为手机/相机拍摄的纸质文件或屏幕截图,面临光照不均、物理扭曲(褶皱 / 弯曲)、拍摄视角多变、模糊 / 阴影、对焦不准等复杂干扰;
无法评估鲁棒性:现有基准未模拟真实环境的复杂性和多样性,导致模型在实际应用中表现存疑;

这些缺陷引出了一个关键疑问:当前MLLMs模型距离在自然环境中实现全面且鲁棒的文档理解能力到底还有多远?
为了揭开这个谜底,字节跳动OCR团队联合华中科技大学打造了WildDoc——首个真实世界场景文档理解的基准数据集。WildDoc选取了3个常用的具有代表性的文档场景作为基准(Document/Chart/Table), 包含超过 12,000 张手动拍摄的图片,覆盖了环境、光照、视角、扭曲和拍摄效果等五个影响真实世界文档理解效果的因素,且可与现有的电子基准数据集表现进行对比。
为了严格评估模型的鲁棒性,WildDoc构建了一致性评估指标(Consistency Score)。实验发现主流 MLLMs 在 WildDoc 上性能显著下降,揭示了现有模型在真实场景文档理解的性能瓶颈,并为技术改进提供可验证的方向。本工作不仅填补了真实场景基准的空白,更推动文档理解研究向 “实用化、泛化性” 迈出关键一步。

论文标题:WildDoc: How Far Are We from Achieving Comprehensive and Robust Document Understanding in the Wild?
论文链接:https://arxiv.org/abs/2505.11015
项目主页:https://bytedance.github.io/WildDoc/
Github:https://github.com/bytedance/WildDoc
WildDoc数据构造与组成
WildDoc数据包含超 1.2 万张手动采集的真实文档图像,模拟自然环境中的复杂挑战,并引入一致性分数指标,量化评估模型在跨场景下的鲁棒性。WildDoc目前已开源全部12K+图像与48K+问答对,其构造过程如下:
数据采集:
场景多样化:在自然环境(如户外、室内不同光照条件)中手动拍摄文档,确保覆盖环境、光照、视角等多维度干扰因素。
基准对齐:复用现有基准的电子文档,通过物理打印后拍摄,保证与传统基准的可比性。
多条件拍摄:
对同一文档进行四次拍摄,每次改变环境参数(如光照强度、拍摄角度、纸张扭曲程度),获取各种不同效果的对比样本。
标注与验证:
对图像中的文本、布局等关键信息以及对于问题的可回答性进行人工验证,确保准确性。
通过一致性分数计算,评估模型在不同条件下的稳定性,辅助筛选高质量数据。

实验结果
研究团队对众多具有代表性的MLLMs进行了测试,包括通用MLLMs(如Qwen2.5-VL、InternVL2.5)、专注文档理解的MLLMs(如Monkey、TextHarmony)和领先的闭源MLLMs(如GPT4o、Doubao-1.5-pro)。实验结果揭示了当前多模态大模型在真实场景下的诸多不足。
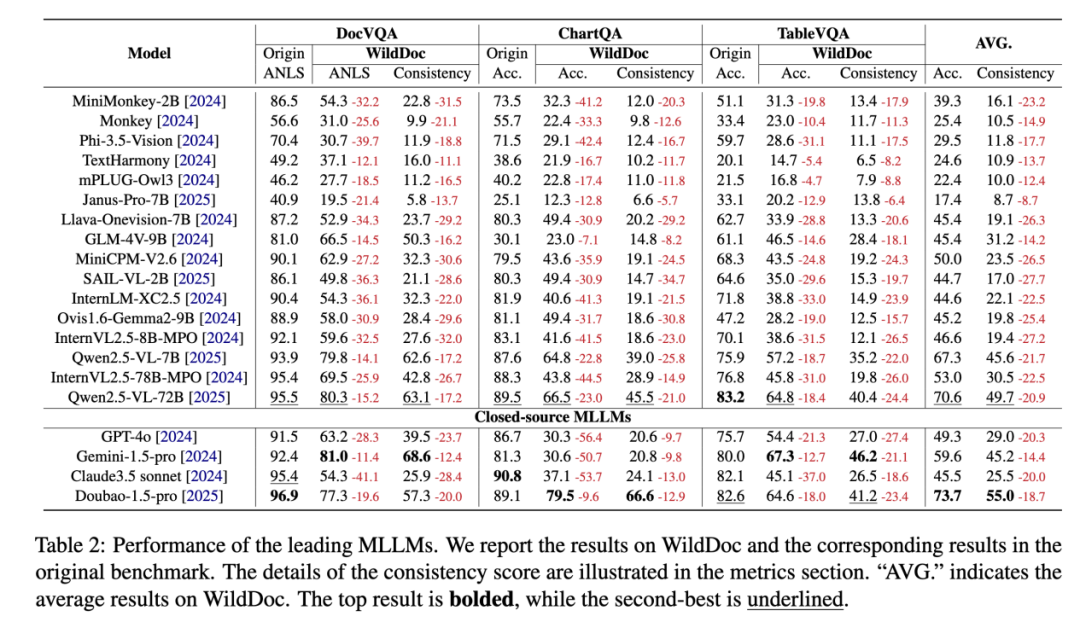
首先,现有MLLMs在WildDoc上的性能相比传统文档基准(如 DocVQA)测试大幅下降。例如,GPT-4o 平均准确率下降 35.3,ChartQA 子集下降达 56.4;开源模型 Qwen2.5-VL-72B 平均准确率 70.6,为开源最佳,但仍低于原始基准约 15%。目前最优的闭源模型为 Doubao-1.5-pro 表现最优(平均准确率 73.7%),但其一致性分数仅 55.0,这也意味着它在一半多的情况下都不能在不同条件下保持准确回答。这表明,当前MLLMs模型在面对真实场景的变化时,缺乏足够的稳定性和适应性。
实验结果揭示了在真实世界文档理解中MLLMs模型的表现,有以下几点发现:
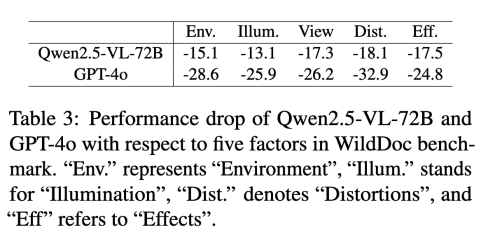
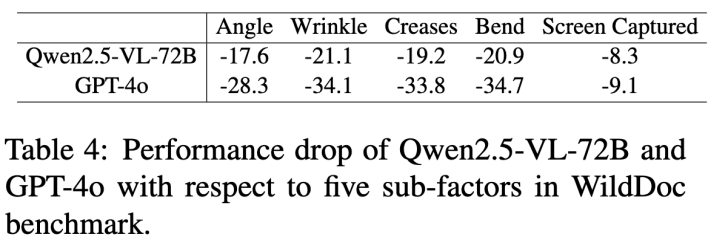
物理扭曲最具挑战性:皱纹、褶皱、弯曲等物理变形导致模型性能下降最显著(如 GPT-4o 下降 34.1-34.7),远超光照(-25.9)或视角(-26.2)变化的影响。
非正面视角与图像质量:非正面拍摄(如倾斜视角)因文本形变和模糊导致性能下降(Qwen2.5-VL-72B 下降 17.6),但屏幕捕获图像因数据增强算法成熟,性能下降较小(-8.3 至 - 9.1)。
语言模型规模影响有限:大参数量模型(如 72B 参数的 Qwen2.5-VL)在 WildDoc 上表现略优,但未完全克服真实场景挑战,表明模型架构需针对性优化。
|
|
另外,一些模型在原始基准测试上表现差异不大,甚至已经接近饱和,但在WildDoc上却出现了显著的性能差异。这说明传统基准测试已经难以区分模型的真实能力,而WildDoc则能更敏锐地捕捉到模型在真实场景下的不足。
未来之路:如何让MLLMs更好地理解真实世界的文档?
面对这些挑战,研究团队提出了几点改进策略,为未来的研究指明了方向。
一是数据增强。通过更多的增强技术来模拟真实世界的条件,如变化的光照、阴影等,让模型在训练中接触到更多样化的场景,从而提高其适应能力。
二是鲁棒特征学习。让模型学会提取对真实世界变化不敏感的特征,这样即使文档图像发生了一些变化,模型也能准确理解其内容。
三是真实数据引入。收集更多的真实世界文档图像,丰富训练数据集,让模型在更多的“实战”中积累经验,提升性能。
WildDoc 数据集有效揭示了 MLLMs 在真实文档理解中的不足,为后续研究提供了关键基准和优化方向,更推动文档理解研究向 “实用化、泛化性” 迈出关键一步。
附录:更多的可视化数据

最新 AI 进展报道
请联系:amos@52cv.net

END
欢迎加入「文档理解」交流群👇备注:OCR



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









