







原理
UDAF函数,简单地理解就是多行输入一行输出,其实就是一个聚合的过程,但聚合的过程可以在mapreduce任务中的多个地方可以实现,要了解UDAF的过程还需要清楚mapreduce的模型,请看下图
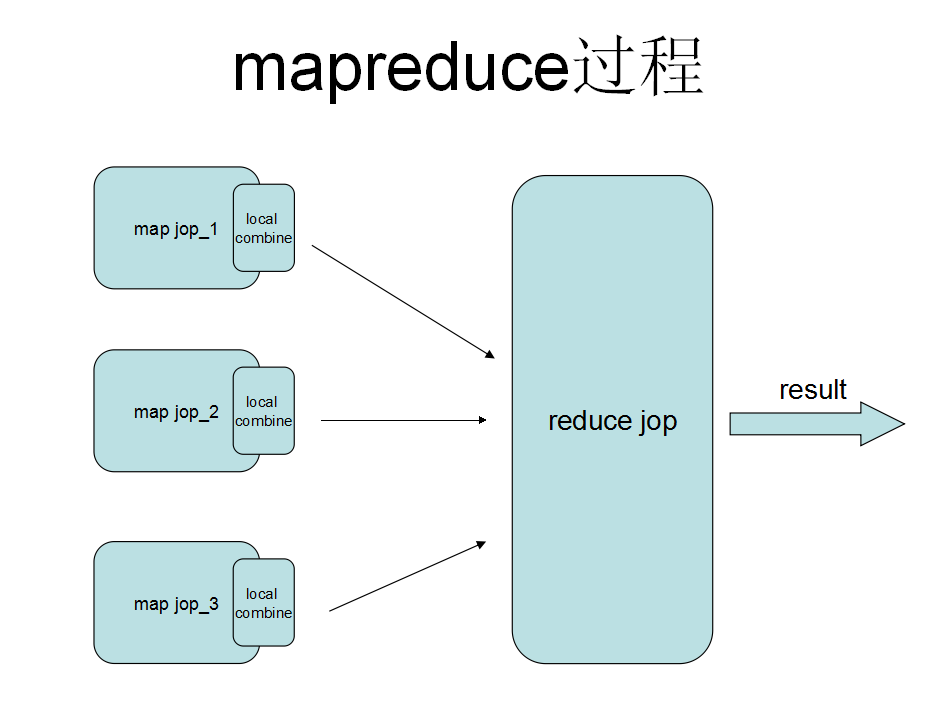
详解
聚合的过程在上述的图中,可以发生在map阶段,可以发生在local combie阶段,也可以发生在reduce阶段,不同阶段的聚合需要不同的实现函数,在源码里也表现定义抽象类:GenericUDAFEvaluator
public abstract class GenericUDAFEvaluator implements Closeable {
......
//用于初始化类;
public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException {
// This function should be overriden in every sub class
// And the sub class should call super.init(m, parameters) to get mode set.
mode = m;
return null;
}
//开辟新空间存储计算结果
public abstract AggregationBuffer getNewAggregationBuffer() throws HiveException;
//重置计算状态
public abstract void reset(AggregationBuffer agg) throws HiveException;
//map阶段调用,只要把保存当前和的对象agg,再加上输入的参数,就可以了。
public abstract void iterate(AggregationBuffer agg, Object[] parameters) throws HiveException;
//mapper结束要返回的结果,还有combine结束返回的结果
public abstract Object terminatePartial(AggregationBuffer agg) throws HiveException;
//combiner合并map返回的结果,还有reducer合并mapper或combine返回的结果。
public abstract void merge(AggregationBuffer agg, Object partial) throws HiveException;
//reducer返回结果,或者是只有mapper,没有reducer时,在mapper端返回结果。
public abstract Object terminate(AggregationBuffer agg) throws HiveException;
......
//此函数是主要是对某条件范围内进行聚合时调用的(只是猜测,还没测试出来)
public GenericUDAFEvaluator getWindowingEvaluator(WindowFrameDef wFrmDef)
}当然可以从GenericUDAFEvaluator的内部枚举当中获取当前阶段的状态;
public static enum Mode {
/**
* PARTIAL1: 这个是mapreduce的map阶段:从原始数据到部分数据聚合
* 将会调用iterate()和terminatePartial()
*/
PARTIAL1,
/**
* PARTIAL2: 这个是mapreduce的map端的Combiner阶段,负责在map端合并map的数据::从部分数据聚合到部分数据聚合:
* 将会调用merge() 和 terminatePartial()
*/
PARTIAL2,
/**
* FINAL: mapreduce的reduce阶段:从部分数据的聚合到完全聚合
* 将会调用merge()和terminate()
*/
FINAL,
/**
* COMPLETE: 如果出现了这个阶段,表示mapreduce只有map,没有reduce,所以map端就直接出结果了:从原始数据直接到完全聚合
* 将会调用 iterate()和terminate()
*/
COMPLETE
};一般情况下,完整的UDAF逻辑是一个mapreduce过程,如果有mapper和reducer,就会经历PARTIAL1(mapper),FINAL(reducer),如果还有combiner,那就会经历PARTIAL1(mapper),PARTIAL2(combiner),FINAL(reducer)。而有一些情况下的mapreduce,只有mapper,而没有reducer,所以就会只有COMPLETE阶段,这个阶段直接输入原始数据,出结果。
下面以count的功能的UDAF函数进行详解;
hive sql任务:select chepai.oil_type,mcount(chepai.oil_type) from chepai group by chepai.oil_type;
sql任务由一个map,三个reduce任务组成;
//调试源码
package org.hive.segment;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.parse.SemanticException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFParameterInfo;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFResolver2;
import org.apache.hadoop.hive.ql.util.JavaDataModel;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.LongObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.typeinfo.TypeInfo;
import org.apache.hadoop.io.LongWritable;;
/**
* This class implements the COUNT aggregation function as in SQL.
*/
@Description(name = "count",
value = "_FUNC_(*) - Returns the total number of retrieved rows, including "
+ "rows containing NULL values.\n"
+ "_FUNC_(expr) - Returns the number of rows for which the supplied "
+ "expression is non-NULL.\n"
+ "_FUNC_(DISTINCT expr[, expr...]) - Returns the number of rows for "
+ "which the supplied expression(s) are unique and non-NULL.")
public class udafCount implements GenericUDAFResolver2 {
private static final Log LOG = LogFactory.getLog(udafCount.class.getName());
@Override
public GenericUDAFEvaluator getEvaluator(TypeInfo[] parameters)
throws SemanticException {
// This method implementation is preserved for backward compatibility.
return new udafCountEvaluators();
}
@Override
public GenericUDAFEvaluator getEvaluator(GenericUDAFParameterInfo paramInfo)
throws SemanticException {
TypeInfo[] parameters = paramInfo.getParameters();
if (parameters.length == 0) {
if (!paramInfo.isAllColumns()) {
throw new UDFArgumentException("Argument expected");
}
assert !paramInfo.isDistinct() : "DISTINCT not supported with *";
} else {
if (parameters.length > 1 && !paramInfo.isDistinct()) {
throw new UDFArgumentException("DISTINCT keyword must be specified");
}
assert !paramInfo.isAllColumns() : "* not supported in expression list";
}
return new udafCountEvaluators().setCountAllColumns(
paramInfo.isAllColumns());
}
/**
* GenericUDAFCountEvaluator.
*
*/
public static class udafCountEvaluators extends GenericUDAFEvaluator {
private boolean countAllColumns = false;
//用于反序列化数据对象
private LongObjectInspector partialCountAggOI;
private LongWritable result;
//Mode mode;
@Override
public ObjectInspector init(Mode m, ObjectInspector[] parameters)
throws HiveException {
super.init(m, parameters);
LOG.info("..............job at part:"+m.name()+"..........");
if (m == Mode.PARTIAL2 || m == Mode.FINAL) {
partialCountAggOI = (LongObjectInspector)parameters[0];
}
result = new LongWritable(0);
return PrimitiveObjectInspectorFactory.writableLongObjectInspector;
}
private udafCountEvaluators  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 275
275











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









