







 本文介绍了WAV文件的内部结构及解析方法,包括文件头信息、音频采样数据的处理等,并探讨了不同编码方式对音频质量的影响。
本文介绍了WAV文件的内部结构及解析方法,包括文件头信息、音频采样数据的处理等,并探讨了不同编码方式对音频质量的影响。
wav文件解析——————-
# 如何处理二进制文本
# wav是一种音频文件的格式,音频文件为二进制文件
# wav文件由头部信息和音频采样数据构成,前44个字节为头部信息
# 包括声道数 采样频率 PCM位宽等等,后面是音频采样数据
#
# 使用python 分析一个wav文件头部信息 处理音频数据
import struct
import array
def main():
with open('卡农.wav','rb') as f:
info=f.read(44)
f.seek(0,2)
print(f.tell())
n=int((f.tell()-44)/2)
buf=array.array('h',(0 for _ in range(n)))
f.seek(44)
f.readinto(buf)
print(buf[0])
print(buf[1])
print(buf[2])
for x in range(n):
buf[x]= int(buf[x]/8)
with open('demo2.wav','wb') as f2:
f2.write(info)
buf.tofile(f2)
info2=struct.unpack('h',b'\x01\x02')
info3=struct.unpack('>h',b'\x01\x02')
print(struct.unpack('h',info[22:24]))
print(struct.unpack('i',info[24:28]))
print(struct.unpack('h',info[34:36]))
print(info2)
print(info3)
pass
main()
Useful References:
1.File Format Specifications: WAVE or RIFF WAVE sound file. Site includes pointers to and local copies of significant documents.
2.page for WAVE audio file format.
3.WAVE PCM soundfile format..
4.The WAVE file specifications came from Microsoft. The WAVE file format use RIFF chunks, each chunk consisting of a chunk identifier, chunk length and chunk data.
WAVE specifications, Version 1.0, 1991-08: riffmci.rtf.
Q&A
- 8bit/16 bit 样值的二进制编码表示一样吗?
- 现有的wav支持哪几种音频编码方法?
data format
- 在数据域中除了单声道-量化位数为8音频数据之外PCM存储格式按照补码的形式存放。
- 于单声道、量化位数为8的情况,使用offset binary(偏移二进制码)。
PCM data is two’s-complement except for resolutions of 1-8 bits, which are represented as offset binary.
The data format and maximum and minimums values for PCM waveform samples of various sizes are as follows:
| Sample Size | Data Format | Maximum Value | Minimum Value |
|---|---|---|---|
| one to eight bits | unsigned integer | 255(0xFF) | 0 |
| Nine or more bits | Signed integer i | Largest positive value of i | Most negative value of i |
For example, the maximum, minimum, and midpoint values for 8-bit and 16-bit PCM waveform data are as follows:
| Sample Size | Data Format | Maximum Value | Minimum Value |
|---|---|---|---|
| 8-bit PCM | 255(0xFF) | 0 | 128(0x80) |
| 16-bit PCM | 32767(0x7FFF) | -32768(-0x8000) | 0 |
Format Code
WAV对音频流的编码没有硬性规定,除了PCM之外,还几乎所有支持ACM规范的编码都可以为WAV的音频流进行编码。
The standard format codes for waveform data are given below. The references above give many more format codes for
compressed data, a good fraction of which are now obsolete(部分现在已经过时了~).
| Format Code | PreProcessor Symbol | Data |
|---|---|---|
| 0x0001 | WAVE_FORMAT_PCM | PCM |
| 0x0003 | WAVE_FORMAT_IEEE_FLOAT | IEEE float |
| 0x0006 | WAVE_FORMAT_ALAM | 8-bit ITU-T G.711 A-law |
| 0x0007 | WAVE_FORMAT_MULAW | 8-bit ITU-T G.711 µ-law |
| 0xFFFE | WAVE_FORMAT_EXTENSIBLE | Determined by SubFormat |
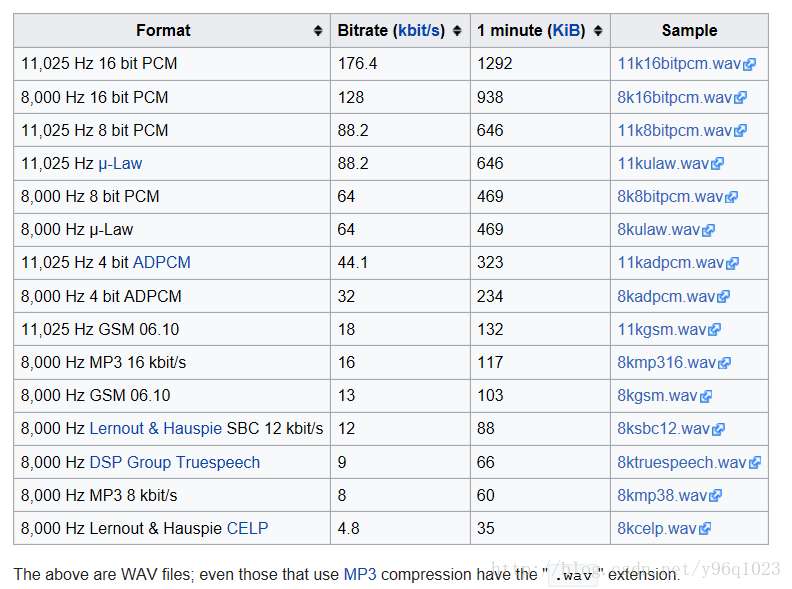
下面维基百科提供的一份参考资料:
几种不同编码方式下得到的单声道monophonic(not sterophonic)wav音频audio quality声音质量与压缩比特率compression bitrates的对比
code知识补充 :
- 我们熟知的数字信号本质上是对连续变化的模拟信号进行抽样、量化和编码得到的,称为PCM(Pulse-code modulation),即脉冲编码调制,这种电的数字信号被叫做数字基带信号,由PCM电端机产生。
- 音频编码:针对频率范围较宽的音频信号进行的编码。主要应用于数字广播和数字电视广播、消费电子产品、音频信息的存储、下载等。
- 语音编码:对模拟的语音信号进行编码,将模拟信号转化成数字信号,从而降低传输码率并进行数字传输。语音编码的基本方法可分为波形编码(Waveform Coding)、参量编码(Parametric Coding)和混合编码(Hybrid Coding)。
- 波形编码是将时域的模拟话音的波形信号经过取样、量化、编码而形成的数字话音信号;
- 参量编码是基于人类语言的发音机理,找出表征语音的特征参量,对特征参量进行编码;
- 混合编码则是结合了两种编码方式的优点,基于语音产生模型的假定采用了分析合成技术,同时又利用了语音的时间波形信息,增强了重建语音的自然度,使得语音质量有明显的提高,代价是编码速率相应上升。
- Microsoft GSM 06.10 The low-level speech compression algorithm of the GSM suite is called GSM 06.10 RPE-LTP (Regular-Pulse Excitation Long-Term Predictor).
- ADPCM (adaptive difference pulse code modulation)自适应差分PCM
- SBC(sub-band coding)子带编码
- CELP(Code Excited Linear Prediction,码激励线性预测编码)
- Truespeech(a proprietary audio codec produced by the DSP Group). It is designed for encoding voice data at low bitrates, and to be embedded into DSP chips. True speech has been integrated into Windows Media Player in older versions of Windows, but no longer supported since Windows Vista. It is also the format used by the voice chat features of Yahoo! Messenger
wav格式详细分析
-
trouble
-
因为老师推荐所以第一次尝试阅读英文文档,自我感觉看了相当多的东西但是仔细整理起来非常杂乱,总结下来有三个问题:1速度慢,2句子含义理解不够,3短时记忆很快忘……所以应该要逐渐锻炼自己文献阅读的能力,每周读一定数量的paper,知识的积累很重要~
format description
The WAVE file format is a subset子集 of Microsoft’s RIFF specification规格详细说明书 for the storage of multimedia多媒体 files. A RIFF file starts out with a file header followed by a sequence of 一串data chunks. A WAVE file is often just a RIFF file with a single “WAVE” chunk which consists of two sub-chunks – a “fmt ” chunk specifying the data format and a “data” chunk containing the actual实际的样点数据 sample data. Call this form the “Canonical标准的典范性的格式 form”. Who knows how it really all works. An almost complete description which seems totally useless unless you want to spend a week looking over it can be found at MSDN (mostly describes the non-PCM 非PCM格式, or 已登记的拥有所有权的数据格式registered proprietary data formats). I use the standard WAVE format as created by the sox program: PCM 脉冲编码调制 pulse code modulation
WAVE文件作为Windows多媒体中使用的声音波形文件格式之一,它是以RIFF(Resource Interchange File Format)格式为标准的。
RIFF全称为资源互换文件格式(ResourcesInterchange FileFormat),
RIFF文件是windows环境下大部分多媒体文件遵循的一种文件结构,RIFF文件所包含的数据类型由该文件的扩展名来标识,
能以RIFF文件存储的数据包括:
音频视频交错格式数据(.AVI)
波形格式数据 (.WAV)
位图格式数据 (.RDI)
MIDI格式数据 (.RMI)
调色板格式 (.PAL)
多媒体电影 (.RMN)
动画光标 (.ANI)
其它RIFF文件 (.BND)
wav结构
A WAVE file is often just a RIFF file with a single “WAVE” chunk which consists of two sub-chunks – a “fmt ” chunk specifying the data format and a “data” chunk containing the actual sample data. Call this form the “Canonical form”.
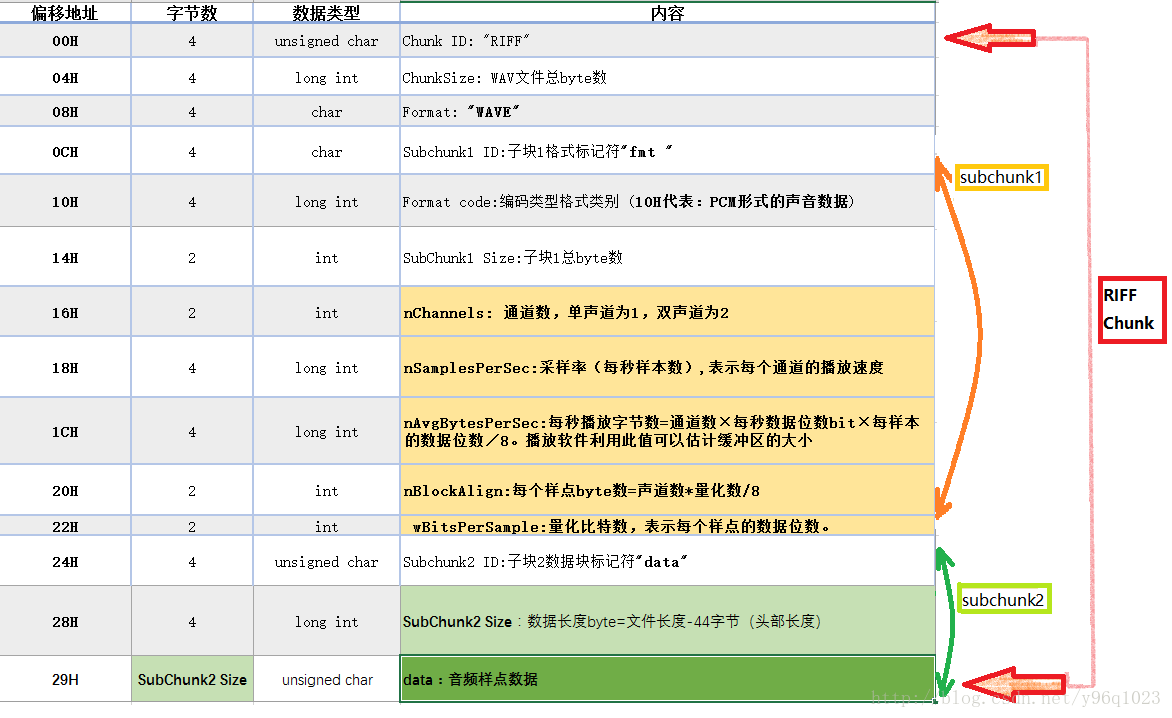

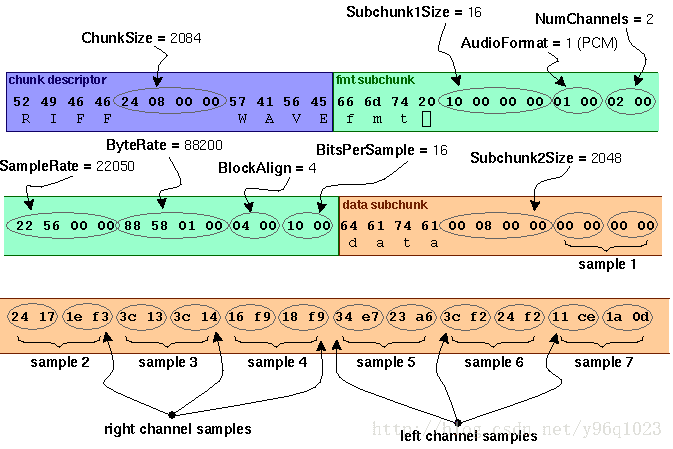
chunk 结构


















 1423
1423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











