







新型冠状病毒可以通过空气中的飞沫、气溶胶等载体进行传播,在公共场所下正确佩戴口罩可以有效地防止病毒的传播。本实验介绍了一种自然场景下人脸口罩佩戴检测方法,该方法对 RetinaFace 算法进行了改进,增加了口罩人脸识别检测任务,优化了损失函数。在特征金字塔网络中引入了一种改进的自注意力机制,增强了特征图的表达能力。建立了包含 3000 张图片的数据集,并进行手工标注,用于网络训练。实验结果表明该算法可以有效进行口罩佩戴检测,在自然场景视频中也取得了不错的检测效果。
三、引言
自 2019 年 12 月以来,在我国爆发了新型冠状病毒肺炎(COVID-19)传播疫情,到目前为止(2021 年 6 月 13 日),根据世界卫生组织发布的最新消息,全球最新数据 | 每日更新截至北京时间 6 月 13 日 16 时:全球累计确诊 176,302,983 例,累计死亡病例 3,805,609 例,现有确诊病例 12,204,415 例。新型冠状病毒具有极强的传染性,它可以通过接触或者空气中的飞沫、气溶胶等载体进行传播,而且在适宜环境下可以存活 5 天。因此勤洗手、佩戴口罩可以有效降低被病毒传染的机率。国家卫生健康委员会发布的《新型冠状病毒感染肺炎预防指南》中强调,个人外出前往公共场所、就医和乘坐公共交通工具时,佩戴医用外科口罩或 N95 口罩。因此在疫情期间公共场所佩戴口罩预防病毒传播是每个人的责任,这不仅需要个人自觉遵守,也需要采取一定的手段监督和管理。随着深度学习在计算机视觉领域的发展,基于神经网络的目标检测算法在行人目标检测、人脸检测、遥感图像目标检测、医学图像检测和自然场景文本检测等领域都有着广泛的应用,本实验介绍介绍一种有效的目标检测算法。
3.1 国内研究现状分析
随着新型冠状病毒的爆发和蔓延,越来越多的人们意识到传统人脸识别系统的局限性,其中一部分人已经开始研究在 iPhone 设置中再添加一个戴着口罩情况下的 FaceID 的方法,然而并未实现。与此同时,国内的汉王科技致力于打造出“人形识别 + 口罩检测 + 疫情上报 + 大数据联动”综合系统,并且采用“社区管理 + 门禁考勤”的模式,将 AI 贯彻落实到防疫工作中。此外,百度还宣布免费开源业内首个口罩人脸检测及分类模型,致力于缓解国内疫情现状。
3.2 国外研究现状分析
国外针对基于深度学习的人脸识别方法的研究成果颇丰。尼德.米勒研究小组首先将深度学习应用于人脸识别领域,并取得了一定的识别准确率,推进了当时的科学研究。最近几年,基于深度学习的人脸识别算法识别准确率得到了很大的提升。Facebook 提出了一种采用基于检测点的人脸检测方法,被称为 DeepFace;此外,Google 提出了 FaceNet 警技术,该技术再次刷新了 LFW 上人脸验证的效果记录。再者是国外对于基于深度学习的目标检测算法的研究,Girshick 等人首先提出了在 R-CNN 的模型,随后又在其基础上提出 FastR-CNN 模型,引入目标区域池化(ROI)和单层金字塔池化层解决了候选框重复计算的问题。近几年,国外通过构建精巧的区域建议网络(RegionProposalNetwork,RPN)取代时间开销大的选择性搜索方法,提出了 FasterR-CNN 模型,使实时检测识别成为可能。而上述三种模型都是基于区域建议的方法,还有一种方法是无区域建议的方法,此方法的标志性的算法有 SSD、YOLO,核心思想是用单一的卷积网络直接基于整幅图像来预测目标的位置及其属性,也称为 one-stage 目标检测。YOLO 和 SSD 是目前为止最先进的目标检测方案之二,能够在一幅图像中同时检测和分类对象,并且通过不断改进,能够在原有的基础上引用锚点(anchor)和残差网络,进一步提高模型的表现。
四、RetinaFace 算法原理
Retinaface 是来自 insightFace 的又一力作,基于 one-stage 的人脸检测网络。同时开源了代码与数据集,在 widerface 上有非常好的表现。实现的功能:检测人脸。Retinaface 与普通的目标检测算法类似,Retinaface 会在图片上预先设定好一些先验框,这些先验框密密麻麻的分布在图片的各处,网络的预测结果会判断这些先验框的内部是否包含人脸并对这些先验框进行调整获得最终的预测框。以以下图片为例:

这张图片有若干个先验框,四周的先验框并不包含人脸,在网络的预测结果当中,四周的先验框置信度就比较低,就可以对这些先验框进行剔除,而中间的先验框内部包含人脸,所以网络的预测结果中中间的先验框的置信度会比较高,就会把这些先验框保留下来,并对这些先验框进行调整获得最终的预测框。在 Retinaface 人脸检测算法中,我们不仅要获得人脸框之外,还需要获得五个人脸关键点的位置这五个关键点分别是左眼、右眼、鼻尖、左嘴角、右嘴角,其获得方式是对先验框中心进行偏移获得五个关键点的 x 轴、y 轴的坐标。
Retinaface 网络对待检测的图片 ① 首先使用 mobilenet0.25 或者 Resnet50 进行主干特征网络提取,② 然后使用 FPN(FeaturePyramidNetwork)和 SSH(SingleStageHeadless)进行加强特征提取,③ 其次使用 ClassHead、BoxHead、LandmarkHead 网络从特征获取预测结果,最后 ④ 对预测结果进行 decode 解码并 ⑤ 通过 NMS 非极大抑制去除重复检测值得出最终结果。

4.1 预测部分
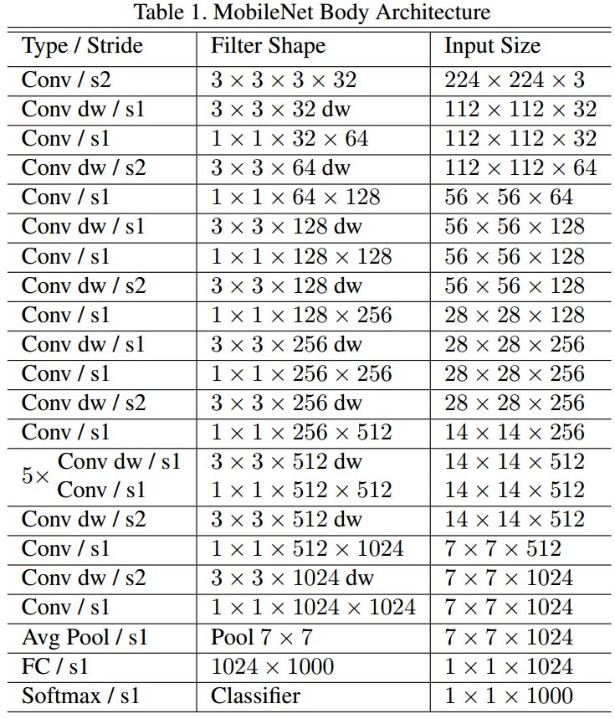
4.1.1 主干网络 Mobilene 介绍
- adepthwiseseparableconvolution(深度可分离卷积)
Retinaface 在实际训练的时候使用两种网络作为主干特征提取网络。分别是 MobilenetV1-0.25 和 Resnet。使用 Resnet 可以实现更高的精度,使用 MobilenetV1-0.25 可以在 CPU 上实现实时检测。MobileNet 模型是 Google 针对手机等嵌入式设备提出的一种轻量级的深层神经网络,其使用的核心思想便是 depthwiseseparableconvolution。深度可分离卷积(depthwiseseparableconvolution)可以用一句话概括:对我们输入进来的特征层的每一个通道进行单独的卷积。
对于一个卷积点而言:假设有一个 3×3 大小的卷积层,其输入通道为 16、输出通道为 32。具体为,32 个 3×3 大小的卷积核会遍历 16 个通道中的每个数据,最后可得到所需的 32 个输出通道,所需参数为 16×32×3×3=4608 个。
应用深度可分离卷积,用 16 个 3×3 大小的卷积核分别遍历 16 通道的数据,得到了 16 个特征图谱。在融合操作之前,接着用 32 个 1×1 大小的卷积核遍历这 16 个特征图谱,所需参数为 16×3×3+16×32×1×1=656 个。可以看出来 depthwiseseparableconvolution 可以减少模型的参数。如下这张图就是 depthwiseseparableconvolution 的结构。

在建立模型的时候,可以将卷积 group 设置成 in_filters 层实现深度可分离卷积,然后再利用 1x1 卷积调整 channels 数。通俗地理解就是 3x3 的卷积核厚度只有一层,然后在输入张量上一层一层地滑动,每一次卷积完生成一个输出通道,当卷积完成后,在利用 1x1 的卷积调整厚度。
- MobileNet 网络结构
如下就是 mobilenetV1-1 的结构,其中 Convdw 就是分层卷积,在其之后都会接一个 1x1 的卷积进行通道处理。
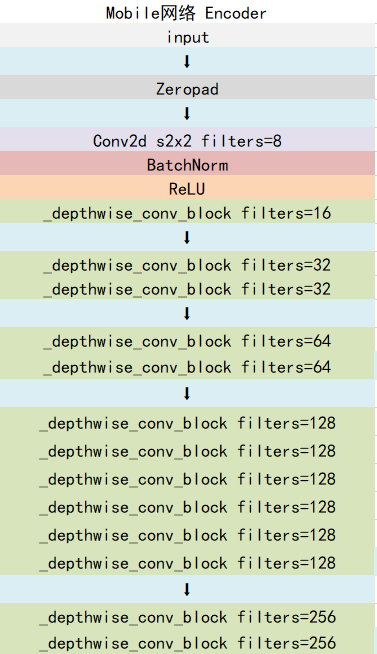
Mobilenet 会对我们输进去的图片不断地进行特征提取,在进行特征提取的同时不断进行下采样,即对我们输入进来的图片进行长和宽的压缩,然后进行通道数的扩张,整个 mobilenet 会对我们输进来的图片进行五次长和宽的压缩,然后会取最后三个 shape 的特征层作为有效特征层传入到加强特征提取网咯里面进行加强特征提取。
4.1.2 FPN 特征金字塔
FPN(Featurepyramidnetwork)特征金字塔网络会对主干网络输出的特征层进行 1x1 卷积后的通道数调整以及上采样 + 特征融合来进行特征加强提取。FPN 对 Mobilenet 最后三个 shape 的有效特征层进行构建,构建方式很简单,首先利用 1x1 卷积对三个有效特征层进行通道数的调整。调整后利用 Upsample 和 Add 进行上采样的特征融合。

利用 mobilenet 可以获得单个有效特征层分别是是 C3、C、C5。
构建 FPN 特征金字塔:对获取的特征层进行特征融合。对三个特征层进行通道数的调整,对获取到的张合宽最小的有效特征层进行上采样的操作同时进行一个 64 通道的卷积,经理上采样后有效特征层的长和宽就变大了,变大之后就可以把它和第二个有效特征层调整通道数后的结果进行相加。
特征融合完之后我们又会进行一个 64 通道的卷积。
卷积完之后又进行上采样,接着有何第一个特征层进行相加。
继续又进行一个 64 通道的卷积。
对获取的三个 64 通道的卷积进行特征提取。

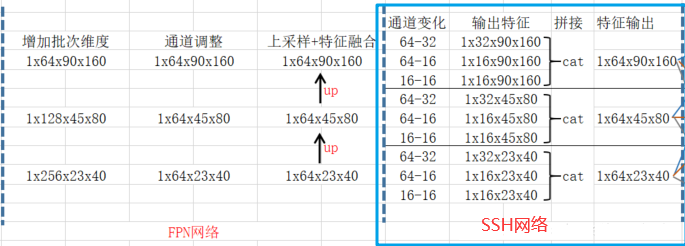
4.1.3 SSH 进一步加强特征提取
SSH(SingleStageHeadless)网络对特征层继续进一步加强特征提取。SSH 使用并行的三个卷积:第一个是 3x3 卷积,第二个是用两次 3x3 卷积代替 5x5 卷积,第三个是用 3 次 3x3 卷积代替 5x5 卷积。
通过 SSH 网络特征提取示意图:
4.1.4 从特征获取预测结果
通过第三步,我们已经可以获得 SSH1,SSH2,SHH3 三个有效特征层了。在获得这三个有效特征层后,我们需要通过这三个有效特征层获得预测结果。
Retinaface 的预测结果分为三个,分别是分类预测结果,框的回归预测结果和人脸关键点的回归预测结果。
分类预测结果用于判断先验框内部是否包含物体,原版的 Retinaface 使用的是 softmax 进行判断。此时我们可以利用一个 1x1 的卷积,将 SSH 的通道数调整成 num_anchorsx2,用于代表每个先验框内部包含人脸的概率。
框的回归预测结果用于对先验框进行调整获得预测框,我们需要用四个参数对先验框进行调整。此时我们可以利用一个 1x1 的卷积,将 SSH 的通道数调整成 num_anchorsx4,用于代表每个先验框的调整参数。
人脸关键点的回归预测结果用于对先验框进行调整获得人脸关键点,每一个人脸关键点需要两个调整参数,一共有五个人脸关键点。此时我们可以利用一个 1x1 的卷积,将 SSH 的通道数调整成 num_anchorsx10(num_anchorsx5x2),用于代表每个先验框的每个人脸关键点的调整。
4.1.5 对预测结果进行解码
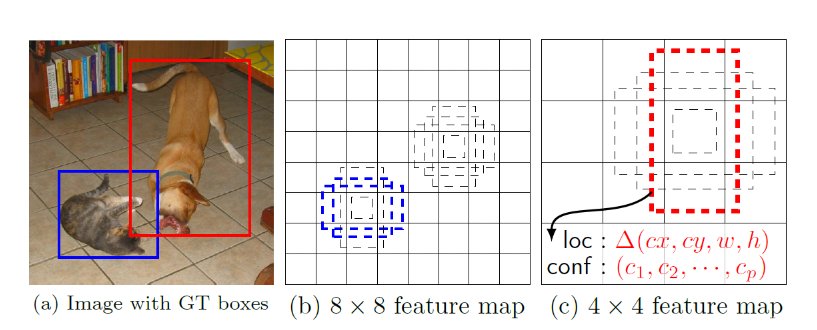
通过第四步,我们可以获得三个有效特征层 SSH1、SSH2、SSH3。这三个有效特征层相当于将整幅图像划分成不同大小的网格,当我们输入进来的图像是(640,640,3)的时候。
SSH1 的 shape 为(80,80,64);SSH2 的 shape 为(40,40,64);SSH3 的 shape 为(20,20,64)
SSH1 就表示将原图像划分成 80x80 的网格;SSH2 就表示将原图像划分成 40x40 的网格;SSH3 就表示将原图像划分成 20x20 的网格,每个网格上有两个先验框,每个先验框代表图片上的一定区域。Retinaface 的预测结果用来判断先验框内部是否包含人脸,并且对包含人脸的先验框进行调整获得预测框与人脸关键点。
分类预测结果用于判断先验框内部是否包含物体,我们可以利用一个 1x1 的卷积,将 SSH 的通道数调整成 num_anchorsx2,用于代表每个先验框内部包含人脸的概率。
框的回归预测结果用于对先验框进行调整获得预测框,我们需要用四个参数对先验框进行调整。此时我们可以利用一个 1x1 的卷积,将 SSH 的通道数调整成 num_anchorsx4,用于代表每个先验框的调整参数。每个先验框的四个调整参数中,前两个用于对先验框的中心进行调整,后两个用于对先验框的宽高进行调整。
人脸关键点的回归预测结果用于对先验框进行调整获得人脸关键点,每一个人脸关键点需要两个调整参数,一共有五个人脸关键点。此时我们可以利用一个 1x1 的卷积,将 SSH 的通道数调整成 num_anchorsx10(num_anchorsx5x2),用于代表每个先验框的每个人脸关键点的调整。每个人脸关键点的两个调整参数用于对先验框中心的 x、y 轴进行调整获得关键点坐标。完成调整、判断之后,还需要进行非极大移植。未经过非极大抑制的图片有许多重复的框,这些框都指向了同一个物体。所以非极大抑制的功能就是:筛选出一定区域内属于同一种类得分最大的框。
4.2 训练部分
4.2.1 真实框的处理
真实框的处理过程可以分为 3 步:
- 计算所有真实框和所有先验框的重合程度,和真实框 iou 大于 0.35 的先验框被认为可以用于预测获得该真实框。
- 对这些和真实框重合程度比较大的先验框进行编码的操作,所谓编码,就是当我们要获得这样的真实框的时候,网络的预测结果应该是怎么样的。
- 编码操作可以分为三个部分,分别是分类预测结果,框的回归预测结果和人脸关键点的回归预测结果的编码。
4.2.2 利用处理完的真实框与对应图片的预测结果计算 loss
loss 的计算分为三个部分:
- BoxSmoothLoss:获取所有正标签的框的预测结果的回归 loss。
- MultiBoxLoss:获取所有种类的预测结果的交叉熵 loss。
- LamdmarkSmoothLoss:获取所有正标签的人脸关键点的预测结果的回归 loss。
由于在 Retinaface 的训练过程中,正负样本极其不平衡,即存在对应真实框的先验框可能只有若干个,但是不存在对应真实框的负样本却有几千上万个,这就会导致负样本的 loss 值极大,因此我们可以考虑减少负样本的选取,常见的情况是取七倍正样本数量的负样本用于训练。
在计算 loss 的时候要注意,BoxSmoothLoss 计算的是所有被认定为内部包含人脸的先验框的 loss,而 LamdmarkSmoothLoss 计算的是所有被认定为内部包含人脸同时包含人脸关键点的先验框的 loss。(在标注的时候有些人脸框因为角度问题以及清晰度问题是没有人脸关键点的)。
- 多任务损失函数
对于一个训练的先验框 i,多任务联合损失函数定义为:
![]()
(1)
其中,
![]()
是分类损失函数,
![]()
是先验框中包含预测目标的概率,
![]()
∈(0,1)分别表示是负先验框和正先验框。
![]()
是目标检测框回归损失函数,其中
![]()
![]()
![]()
![]()
}i 表示与正先验框相关的预测框的坐标信息,同理
![]()
![]()
}表示与负先验框相关的预测框的坐标信息。
![]()
是面部标志回归损失函数,其中
![]()
![]()
}i 和
![]()
![]()
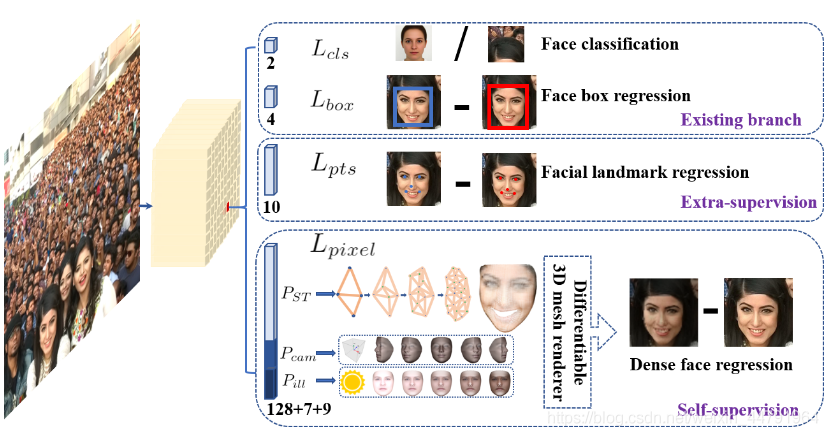
}分别表示正先验框中预测的五个人脸标志点和标注的五个人脸标志点。Lpixel 表示的是面部密集点回归损失函数。λ1、λ2 和 λ3 表示的是损失平衡权值参数,在 RetinaFace 算法中分别设置为 0.25、0.1 和 0.01,意味着在有监督的学习中再加关注检测框和面部标志点的信息。
五、改进 RetinaFace 算法用于口罩佩戴检测
为了实现对人脸口罩佩戴进行检测,在 RetinaFace 算法的基础上进行了改进,改进后的网络结构如下图所示,整个框架分为特征金字塔网络、上下文网络和多任务联合损失三个部分。其中在特征金字塔中的主干网络为 ResNet-512,用于特征提取并引入了注意力机制模块,增强特征图的表达能力。在多任务联合损失中舍去了无关的面部密集点回归损失,提高算法模型的训练速度和效率。
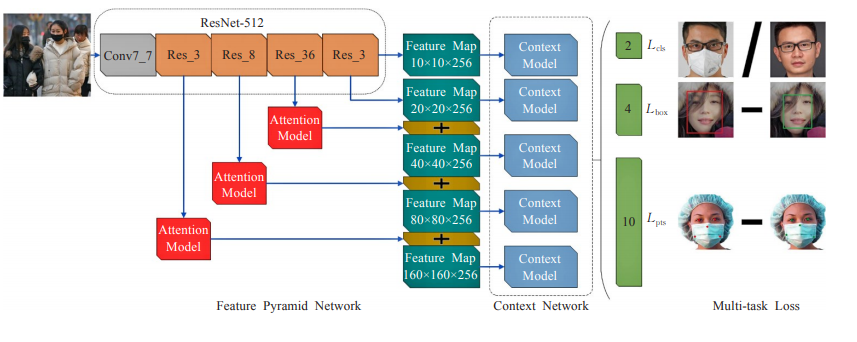
5.1 改进的自注意力机制
在特征金字塔网络中引入了注意力机制模块,其内部结构如图 3-2 所示,主要包括金字塔注意力机制(PyramidAttentionMechanism,PAM)和自注意力机制(Self-Attention,SA)。金字塔注意力机制可以增强特征图的表达能力,自注意力可以更好地利用特征的上文关系,提高注意力特征图的描述能力。
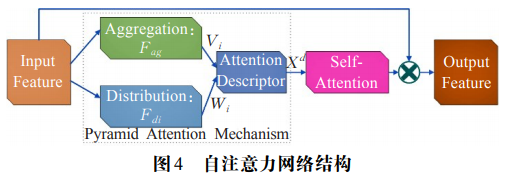
在金字塔注意力机制中包括聚合操作、分布操作和描述操作。设输入的特征图包含 C 个通道,其中的单个通道特征可表示为
![]()
,i=1,2,,C,其中聚合操作利用空间池化
![]()
生成一个 k 级的空间特征图描述,具体计算方式为:
![]()
(2)
空间特征图描述随着 k 的增长会更加详细,为了进一步满足在多任务上的不同需要求,引入敏感性 m 来度量描述的详细程度,对于敏感性 m 可以用来描述金字塔池化后的特征向量的集合:
![]()
(3)
则包含多级特征上下文的空间注意力特征图描述为:
![]()
(4)
空间特征分布的表达式为:
![]()
(5)
其中,X∈
![]()
表示输入特征图,
![]()
表示内核为 1×1 的深度卷积。
![]()
表示与聚合操作具有相同敏感性的空间池化特征的集合。δ 表示用于归一化 Softmax 函数。最后每个空间特征的描述
![]()
可以表示为:
![]()
(6)
其中表示点积运算,所有通道描述的集合可以表示为
![]()
= {
![]()
}|i=1,2,,C。为了增强空间注意力特征描述包含上下文联系,本实验加入了自注意力机制,经过自注意力机制的特征向量可以表示为:
S=δ(MLP(
![]()
=δ(
![]()
δ(
![]()
(
![]()
))) (7)
其中,δ 表示 Sigmod 函数,
![]()
是由公式(5)获得的所有通道描述的集合。
![]()
∈
![]()
,
![]()
∈
![]()
,σ 表示 ReLU 函数。r 定义为平衡因子,在所有实验中将其设置为 16,以平衡准确性和复杂性之间的关系。最后的输出特征图可表示为:
![]()
=
![]()
(8)
其中
![]()
表示逐通道乘法。
5.2 多任务联合损失
参考了 RetinaFace 算法损失函数的设计,为了提高算法的训练速度和检测效率,只保留了相关的分类损失、检测框回归损失和面部标志回归损失,并进行了优化。去掉了面部密集点回归损失。总的损失函数表示为:
L=
![]()
(9)
各变量定义如公式(1),其中分类损失
![]()
是由交叉熵损失函数做的二分类(完整人脸和佩戴口罩人脸),检测框回归损失
![]()
使用了 Smooth-L 损失函数,面部标志回归损失
![]()
同样使用了 Smooth-L1 损失函数对五个检测的人脸标志点做了归一化处理。另外,本实验将损失平衡权值参数 λ1 和 λ2 分别设置为 0.3 和 0.1
六、实验分析
6.1 数据集分析
由于目前没有公开的自然场景人脸口罩佩戴数据集,本实验参考 WIDERFACE 数据集和 RetinaFace 算法对数据集的处理方法,制作了人脸口罩佩戴数据集。首先从 WIDERFACE 人脸数据集和 MAFA(MaskedFaces)遮挡人脸数据集中分别随机抽取 1400 张人脸图片和 1600 张人脸佩戴口罩图片,共包含 16344 张人脸目标和 3127 张口罩佩戴目标。然后对数据集进行统一的标注,标注的信息主要有目标框的中心坐标、长度、宽度、类别和五个人脸标注点,示例如图 4-1 所示,对应的标注数据如表 1 所示。其中 80% 图片用于模型训练,剩余 20% 的图片用于测试。
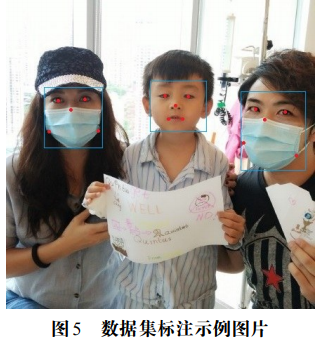
表 1 示例图片标注数据
| Object | Box | Landmark |
|---|---|---|
| Mask1 | 96,167,83,86,1 | 74,143;112,141;92,156;61,187;131,186 |
| Face1 | 245,133,80,36,0 | 226,136;259,137;241,150;231,169;251,169 |
| Mask2 | 186,380,92,112,1 | 355,155;397,159;368,170;33,8203;413,221 |
6.2 网络模型训练
训练方式采用随机梯度下降(StochasticGradientDescent,SGD)优化模型对网络进训练,动量为 0.9,权重衰减为 0.0005,批量为 8×4。学习率从 10-3 开始,当网络更新 5 个轮次(epoch)后上升到 10-2,然后在第 34 和第 46 个轮次除以 10,整个训练过程一共进行 60 个轮次结束。另外,在相同的实验环境下,使用相同的训练方式,实验训练了一个原始的 RetinaFace 网络模型,用于对比分析。
6.3 实验结果分析
实验结果:




本实验将数据集中 20% 的图片用于实验测试分析,共 600 张图片,其中包含标注的 3196 个人脸目标和 684 个佩戴口罩目标。评估指标使用目标检测领域常用的 ROC 曲线(ReceiverOperatingCharacteristiccurve)、平均精度 AP(AveragePrecision)、平均精度均值 mAP(MeanAveragePrecision)和每秒帧率 FPS(FramePerSecond)来客观评价本实验算法对于人脸和口罩佩戴检测的效果。其中 AP 的值反映单一目标的检测效果,其计算方式为:
AP=
![]()
(10)
其中,p(r)表示真正率(TruePositiveRate)和召回率的映射关系,真正率 p 和召回率 r 的计算方式为:
p=
![]()
(11)
r=
![]()
(12)
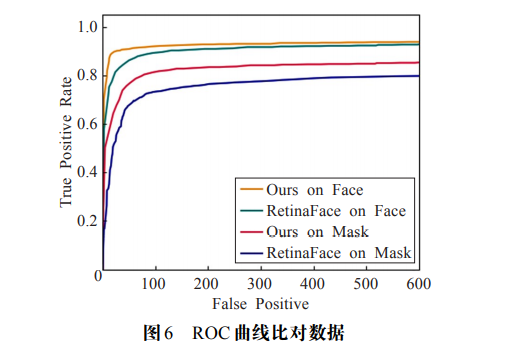
其中 TP(TruePositive,真正数)表示正样本被预测为正样本的个数,FP(FalsePositive,假正数)表示负样本被预测为了正样本的个数,FN(FalseNegative,假负数)表示正样本被预测为负样本的个数。本实验根据真正率和假正数的关系绘制 ROC 曲线用来表示对目标检测的性能,如图 4-3 所示,其中横轴表示假正数,纵轴表示真正率。总体上看本实验算法和 RetinaFace 算法对人脸的检测效果明显优于口罩佩戴检测,原因是在数据集中人脸目标多于口罩佩戴目标,在模型训练过程中可以学到更多的人脸特征信息。当假正数到达 600 时,在人脸目标检测上本实验算法和 RetinaFace 的检出率分别为 0.938 和 0.928,在口罩佩戴目标检测上本实验算法和 RetinaFace 的检出率分别为 0.853 和 0.798,可以看出本实验算法的检测性能相比 RetinaFace 算法均有所提高。
mAP 表示所有类别平均精度的均值,反映了总体上的目标检测效果,其计算方式为:
mAP=
![]()
(13)
其中,n 表示类别的个数,i 表示某个类别。每秒帧率(FPS)表示每秒处理的图片数量,用来衡量算法的检测效率。本实验将 IoU 设置为 0.5 时的实验结果如表 4 所示。可以看出,由于本实验在训练好的 RetinaFace 网络基础上进行初始化训练,因此在人脸类别的检测上 AP 值分别高达 90.6% 和 87.3%,在人脸口罩佩戴检测上的取值分别为 84.7% 和 76.5%。总体而言,本实验改进的网络模型与 RetinaFace 相比 mAP 值提高了 5.8 个百分点。在检测效率上,本实验算法使用注意力机制增加了计算量,检测效率略低于 RetinaFace 算法。
表 2 实验对比数据
| 算法 | Face% | Mask | mAP% | FPS(帧.s^-1) |
|---|---|---|---|---|
| RetinaFace | 87.3 | 76.5 | 81.9 | 17.9 |
| 本算法 | 90.6 | 84.7 | 87.7 | 18.3 |
从 ROC 曲线和平均精度均值两个指标上看,本算法改进后在人脸检测和口罩佩戴检测方面 RetinaFace 均有一定程度的提高,具体检测示例效果如图 4-2 所示,第一行图片中的正常目标,本实验算法和 RetinaFace 均取得了不错的检测效果,正确检测出了图片中的目标信息。对于第二行图片中当包含小尺寸目标时本实验算法的检测效果相比 RetinaFace 提升较大,正确检测出了 4 个小的人脸目标。对于第三行图片中部分受到遮挡的目标,本实验算法相比 RetinaFace 具有一定的检测能力,分别检测出了一个受遮挡的人脸目标和口罩佩戴目标。对于拍摄环境较差的第四行图片,本实验算法的检测能力优于 RetinaFace,可以检测出图片中清晰度低的目标。
七、总结与心得体会
7.1 实验总结
本实验通过改进 RetinaFace 算法,提出了一种自然场景下人脸口罩佩的检测方法,该方法通过在特征金字塔网络中引入注意力机制,分别使用了金字塔注意力机制增强特征图在通道上的表达能力,并抑制无用信息,使用自注意力机制在特征图的空间上增强了上下文联系和特征描述能力,最终提高了对多尺度目标的检测效果。本实验通过在建立的 3000 张图片的数据集上进行训练的结果表示,本方法可以有效检测自然场景下佩戴口罩的人脸和没有佩戴口罩的人脸,平均精度均值达到 87.7%,每秒帧率为 18.3 帧/s,另外在自然场景视频检测中也取得了不错的效果,证明了本实验算法框架的合理性。在未来的研究中,将进一步对网络结构进行优化,使用更多的数据集对网络模型进行训练,提高人脸口罩佩戴的检测能力和检测效率。
7.2 实验心得体会
简而言之,Retinaface 执行的过程其实就是在图片上预先设定好先验框,网络的预测结果会判断先验框内部是否包含人脸并且会对先验框进行调整获得预测框和五个人脸关键点。而本实验通过改进,我们人脸口罩佩戴数据集的五个关键点的位置和人脸的五个关键点的标记略有不同,我们是标记在左眼、右眼、鼻梁、以及口罩的左右两边,经过不断的训练是计算机能能够识别出哪些带了口罩的人脸和没有带口罩的人脸。在网络预测的时候,我们先识别当前输入的图像是否存在人脸的五个关键点或者戴了口罩的人脸的五个关键点,如果网络的预测结果是人脸的五个关键点,那么当前输入的图像为人脸,如果网络的预测结果是戴了口罩的人脸,那么当前的图像为带了口罩的人脸,并在图像上显示出来。
经过此次实验的锻炼与实践,我深刻认识到机器学习对我们人类生活重要性,在我们日常生活中人工智能无处不在,时时刻刻都在改变着我们的衣食住行,以前我总是认为机器学习、人工智能、神经网络是多么高深的东西,只有专家才能理解与掌握的技能,可是经过此次实验我的这种想法完全改变了,其实它也没有那么难,原理也没那么复杂,神经网络无非就是原始数据输入个输入层,经过几个隐藏层对数据做一次次特征提取,隐藏层的意义,是把前一层的向量变成新的向量,就是坐标变换,把数据做平移,旋转,伸缩,扭曲,让数据变得线性可分,最后经过输出层输出预测结果。再比较输出结果与实际的差异进行反向传播更新权值与偏置,最终总能找到较合适的权值和偏执。神经网络的处理构造过程也深刻的体现了机器学习与人功智能。
此次实验使我对计算机视觉这门学科产生了浓厚的兴趣,由于计算机视觉最近比较火,当时选课的时候就是想着去了解一下,揭开计算机视觉背后神秘的面纱,加上去年大创的选题和这个挂钩,于是选择计算机视觉这门课是必然的。在课后不断的学习与了解中,过程也是比较辛苦的,一开始不断与研究生学长进行讨论,他给我们讲解我们应该怎么做,去学习哪些相关的知识,起初在 b 站上看视频挺无聊的,感觉人家很厉害,可能是因为他没有将基础的知识,后来一边学习计出知识一边看视频我觉得自己还是听的懂的。最后成了此次实验、也结束了大创,是真的很开心,感觉学习知识的过程辛苦且有收获感。从这门课中收获了不少的知识与经验,为今后进行下一阶段的学习打下了坚实的基础。
八、参考文献
刘全,翟建伟,章宗长,等.深度强化学习综述[J].计算机学报,2018,41(1):3-29.
牛作东,覃涛,李捍东,陈进军,等.改进 RetinaFace 的自然场景口罩佩戴检测算法.贵州大学电气工程学院,贵阳 550025
BhandaryA,SudeepaKB,ChokkadiS,etal.Astudyonvariousstateoftheartoftheartfacerecognitionsystemusingdeeplearningtechniques[J].InternationalJournalofAdvancedTrendsinComputerScienceandEngineering,2019,8(4):1590-16
RetinaFace:Single-stageDenseFaceLocalisationintheWildJiankangDeng*1,2,4JiaGuo*2YuxiangZhou1JinkeYu2IreneKotsia3StefanosZafeiriou,etal.ingle-stageDenseFaceLocalisationintheWild
AlpG uler,N.Neverova,andI.Kokkinos.Densepose:Densehumanposeestimationinthewild.InCVPR,2018.2,3
BulatandG.Tzimiropoulos.Howfararewefromsolv-ingthe2d&3dfacealignmentproblem(andadatasetof230,0003dfaciallandmarks).InICCV,2017.6















 731
731











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









