







这篇文章是2019年的ICCVW,其为了视频超分的实时性而只追求速度,放弃了表现力。作者提出了一种高效的VSR模型——Recurrent Latent Space Propagation(RLSP),其是一种典型的无对齐方法,因此相对于经典VSR那些基于flow或者DCN的模型来说,其相对高效。RLSP的将VSR建模成RNN模型,其核心是Shuffling和Hidden-state。
参考文档:
①源码
②视频超分:RLSP(Efficient Video Super-Resolution through Recurrent Latent Space Propagation)
Efficient Video Super-Resolution through Recurrent Latent Space Propagation
Abstract
RLSP是一种无对齐的VSR方法:无对齐最大的好处就是高效,速度快;缺陷就是表现了不足——PSNR相对于对齐的VSR模型会差一些。
作者给出了3个理由来阐述推出RLSP的必要性:
- 实时性。无论是显式还是隐式的运动补偿,都会占据一定的计算资源与显存需求,故取消对齐模块可以加快VSR重建的速度以及节省一定的GPU-Memory。
- FLow-based对齐方法高度依赖于运动估计的准确性。一旦运动估计不精确则会引入artifacts;无论是Flow-based还是Flow-free的对齐方式都会使用插值运算,则不能避免的损失高频细节。
- 当数据集中运动幅度不大的时候,相邻帧之间十分相近,不进行对齐影响也不大。
故作者推出了一种基于RNN的VSR模型——RLSP,其将视频超分建模成序列问题(Sequence-to-Sequence),其有如下特点:
- 无对齐,速度快,具有实时性,其比当时推出的DUF要快将近70倍!
- RLSP的核心就是使用一个高维的(
C
=
128
C=128
C=128)的隐藏状态
h
h
h来传播过去的特征信息;以及使用基于ESPCN提出的
PixelShuffle来完成上采样的Shuffle_up和Feedback的Shuffle_down。
1. Introduction
复杂的运动补偿往往需要昂贵的计算资源,因此这样的模型并不具备实时性场合,比如游戏超分领域。
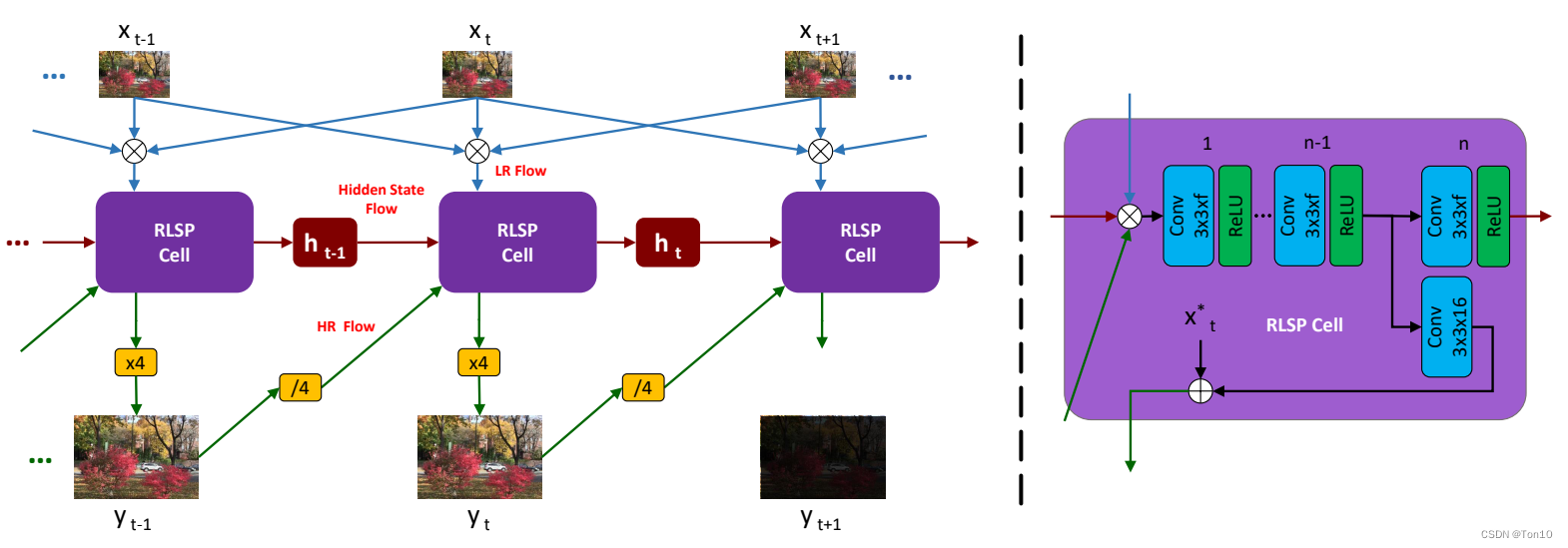
RLSP就是针对实时性要求设计的VSR模型。不同于VESPCN、TDAN、Robust-LTD、EDVR这些使用sliding-windows的特征传播方式,RLSP基于循环网络结构,属于单向特征传播的VSR方法,具体传播是通过隐藏状态(Latent-State)来做的。
下图是RLSP、FRVSR、DUF在PSNR-Runtime上的实验结果:

- 从上图可以看出RLSP比FRVSR和DUF分别快10倍和70倍左右。
- “
7-128”表示融合之后使用7层的CNN网络,每一层使用128个滤波器,因此RLSP的表现性能可以通过提升网络的复杂度来实现。
2. Related Work
略
3. Method
对于每一次迭代,RLSP的目标就是将当前帧
x
t
∈
R
H
×
W
×
C
x_t\in\mathbb{R}^{H\times W\times C}
xt∈RH×W×C超分到
y
t
∈
R
r
H
×
r
W
×
C
y_t\in\mathbb{R}^{rH\times rW\times C}
yt∈RrH×rW×C。关于RLSP的pipeline如下图所示,由于RLSP基于RNN结构,故其最重要的部分就是下图紫色框——RLSP-Cell:
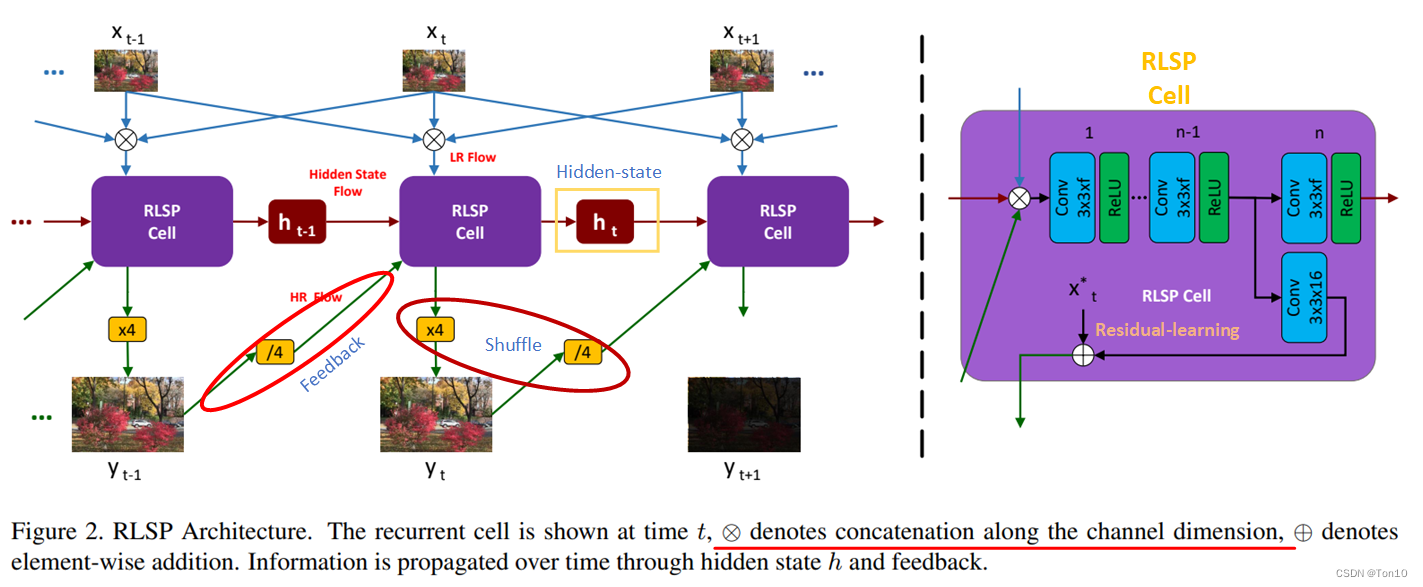
接下来大致描述下RLSP的pipeline(假设每个batch的帧数为10,输入为RGB图像
64
×
64
64\times 64
64×64,超分倍率为
r
=
4
r=4
r=4,滤波器个数
f
=
128
f=128
f=128):
- RLSP吸取sliding-windows的经验:将前后相邻各1帧和当前帧做通道融合,不同的是直接免去了对齐过程,之所以敢这么做是假设相邻帧相似度高。因此cell的其中一个输入是 R b × 3 × 3 × 64 × 64 \mathbb{R}^{b\times 3\times 3\times 64\times64} Rb×3×3×64×64。
- Cell的第二个输入是来自上一帧的超分结果
y
t
−
1
y_{t-1}
yt−1——
R
b
×
3
×
256
×
256
\mathbb{R}^{b\times 3\times 256\times 256}
Rb×3×256×256通过
shuffle_down之后的结果—— R b × ( 3 ∗ 4 ∗ 4 ) × 64 × 64 \mathbb{R}^{b\times (3*4*4)\times 64\times 64} Rb×(3∗4∗4)×64×64。 - Cell的第三个输入是上一个隐藏状态
h
t
−
1
h_{t-1}
ht−1——
R
b
×
128
×
64
×
64
\mathbb{R}^{b\times 128\times 64\times 64}
Rb×128×64×64。同RNN结构中的细胞一样,隐藏状态的获取也是通过一些全连接层或者卷积层去预测。由于其本身是一个递归循环的过程,故我们直接分析
h
t
h_t
ht的产生。如上图紫色框所示,cell一共有
n
=
7
n=7
n=7层,第一层是将三方在通道融合之后进行
(
3
∗
3
+
f
+
3
∗
r
2
)
×
128
×
(
3
∗
3
)
×
1
×
1
(3*3+f+3*r^2)\times 128\times (3*3) \times 1\times 1
(3∗3+f+3∗r2)×128×(3∗3)×1×1的卷积;接下来5层卷积都是
128
×
128
×
(
3
∗
3
)
×
1
×
1
128\times 128\times (3*3)\times 1\times1
128×128×(3∗3)×1×1;第三层卷积为
128
×
(
3
∗
r
2
+
f
)
×
(
3
×
3
)
×
1
×
1
128\times (3*r^2+f)\times (3\times 3)\times 1\times 1
128×(3∗r2+f)×(3×3)×1×1,然后从通道为分为2部分,其中一块通过Relu输出
R
b
×
128
×
64
×
64
\mathbb{R}^{b\times 128\times 64\times 64}
Rb×128×64×64——
h
t
h_t
ht,另一块和
x
t
∗
x_t^*
xt∗相加做残差连接输出
R
b
×
(
3
∗
r
2
)
×
64
×
64
\mathbb{R}^{b\times (3*r^2)\times 64\times 64}
Rb×(3∗r2)×64×64,其中
x
t
∗
x^*_t
xt∗是
x
t
x_t
xt复制
r
2
r^2
r2倍之后的结果——
R
b
×
(
3
∗
r
2
)
×
64
×
64
\mathbb{R}^{b\times (3*r^2)\times 64\times 64}
Rb×(3∗r2)×64×64:
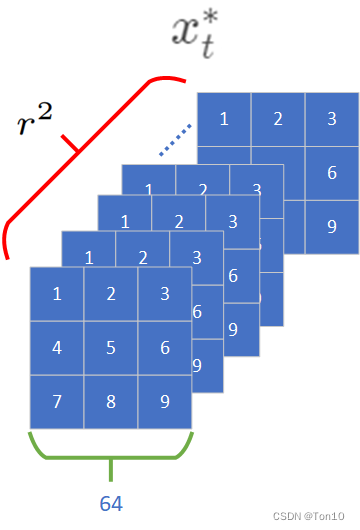
- Shuffle-up等效于PixelShuffle的过程;而Shuffle-down是和Shuffle-up相反的过程,类似于Understanding DCN-Alignment in VSR中具备统一性的可变形卷积表达的过程。Feedback处使用了shuffle-down来降采样,shuffle-up则用于 x t → y t x_t\to y_t xt→yt的上采样部分。
Note:
- 残差连接可以让网络直接去学习残差部分,从而让训练更加稳定;此外直接将 x t x_t xt的信息添加进来来你补CNN造成的信息损失。
- RLSP每次只超分1帧。
3.1 Shuffling
Shuffling主要包括shuffle-up来上采样和shuffle-down来降采样。
Shuffle-up的原理就是ESPCN的亚像素卷积层,其并不改变像素,而是将通道上的所有像素copy并进行组合产生:
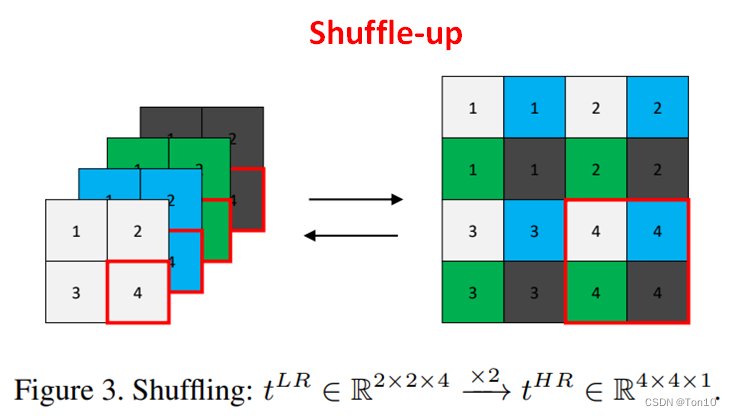
Shuffle-up
\colorbox{springgreen}{Shuffle-up}
Shuffle-up
t
L
R
∈
R
H
×
W
×
Z
→
×
r
t
H
R
∈
R
r
H
×
r
W
×
Z
/
r
2
.
(1)
t^{LR} \in \mathbb{R}^{H\times W\times Z} \;\;\;\mathop{\rightarrow}\limits^{\times r}\;\;\; t^{HR} \in \mathbb{R}^{rH\times rW \times Z/r^2}.\tag{1}
tLR∈RH×W×Z→×rtHR∈RrH×rW×Z/r2.(1)源码:
def shuffle_up(x, factor):
# format: (B, C, H, W)
b, c, h, w = x.shape
assert c % factor**2 == 0, "C must be a multiple of " + str(factor**2) + "!"
n = x.reshape(b, factor, factor, int(c/(factor**2)), h, w)
n = n.permute(0, 3, 4, 1, 5, 2)
n = n.reshape(b, int(c/(factor**2)), factor*h, factor*w)
return n
Shuffle-down
\colorbox{orange}{Shuffle-down}
Shuffle-down
t
H
R
∈
R
H
×
W
×
Z
→
×
r
t
L
R
∈
R
H
/
r
×
W
/
r
×
r
2
Z
.
(2)
t^{HR} \in \mathbb{R}^{H\times W\times Z} \;\;\;\mathop{\rightarrow}\limits^{\times r}\;\;\; t^{LR}\in \mathbb{R}^{H/r \times W/r \times r^2 Z}.\tag{2}
tHR∈RH×W×Z→×rtLR∈RH/r×W/r×r2Z.(2)源码:
def shuffle_down(x, factor):
# format: (B, C, H, W)
b, c, h, w = x.shape
assert h % factor == 0 and w % factor == 0, "H and W must be a multiple of " + str(factor) + "!"
n = x.reshape(b, c, int(h/factor), factor, int(w/factor), factor)
n = n.permute(0, 3, 5, 1, 2, 4)
n = n.reshape(b, c*factor**2, int(h/factor), int(w/factor))
return n
3.2 Residual Learning
就是在Cell中将 x t ∗ x_t^* xt∗和CNN的输出相结合,使得网络去学习残差部分;残差连接除了缓解梯度消失问题以外可以增加一定的稳定性,让残差的学习范围缩小从而减小方差;此外由于CNN会将输入信息进行不可避免地衰减,故将输入直接加进来也有助于保存下来原始输入信息。
3.3 Feedback
Feedback就是将 y t − 1 y_{t-1} yt−1进行shuffle-down地过程,由于相邻帧高度相关,因此将这部分信息融合进来也有助于当前帧 x t x_t xt的超分。
3.4 Hidden State
和RNN一样,隐藏状态 h t − 1 h_{t-1} ht−1记忆了过去的特征信息,它通过和当前帧信息进行合并来利用过去的特征信息来帮助当前帧的超分过程。在RLSP中,作者使用了7层卷积层来学习hidden-state,最终的输出格式为: R b × f × 64 × 64 , f = 128 \mathbb{R}^{b\times f\times 64\times 64},f=128 Rb×f×64×64,f=128。
3.5 Loss
RLSP的损失函数采用MSE:
L
=
1
k
∣
∣
y
∗
−
y
∣
∣
2
2
.
(3)
\mathcal{L} = \frac{1}{k}||y^* - y||^2_2.\tag{3}
L=k1∣∣y∗−y∣∣22.(3)
4. Experimental Setup
我在复现的时候相关实验配置如下:
params = {"lr": 10 ** -4,
"bs": 2,
"crop size h": 64,
"crop size w": 64,
"sequence length": 5,
"validation sequence length": 20,
"number of workers": 8,
"layers": 7,
"kernel size": 3,
"filters": 128,
"state dimension": 128,
"factor": 4,
"save interval": 50000,
"validation interval": 1000,
"dataset root": "./dataset/",
"device": torch.device("cuda" if torch.cuda.is_available() else "cpu"),
}
由于源码部分对数据集没有写清楚,并且源码中对于数据集读取的内容是有问题的,因此我做了2处改动:
-
使用REDS数据集,数据集的位置如下:

-
使用PIL.Image.open()来读取图片。
5. Results and Discussion
5.1 Ablation
除了残差连接以外,RLSP还使用了3处tips:
- Adding adjacent frames。
- Feedback。
- Hidden-state。
为了研究上述3个点对RLSP的影响,ablation实验结果如下:
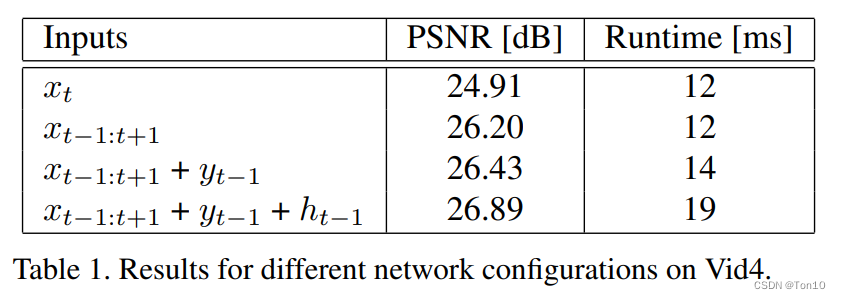
其中第一项是指所有帧都独立的去处理;第二项是增加相邻帧;第三项是增加feedback——
y
t
−
1
y_{t-1}
yt−1;第四项是增加feedback和隐藏状态
h
t
−
1
h_{t-1}
ht−1。实验结论如下:
- 上述3个点对于RLSP表现力的提升是有帮助的,但是也依次增加了计算量。
5.2 Temporal Consistency
略
5.3 Information Flow over Time
略
5.4 Initialization
略
5.5 Accuracy and Runtimes
- 实验在Vid4上验证,测试于vid4的全序列上。
- 最后统计的平均PSNR是平均于vid4中4个视频序列的结果;统计的runtime是每一帧重建所需要的时间(ms)。
- 最后恢复的目标是2K的视频序列。
实验结果如下:
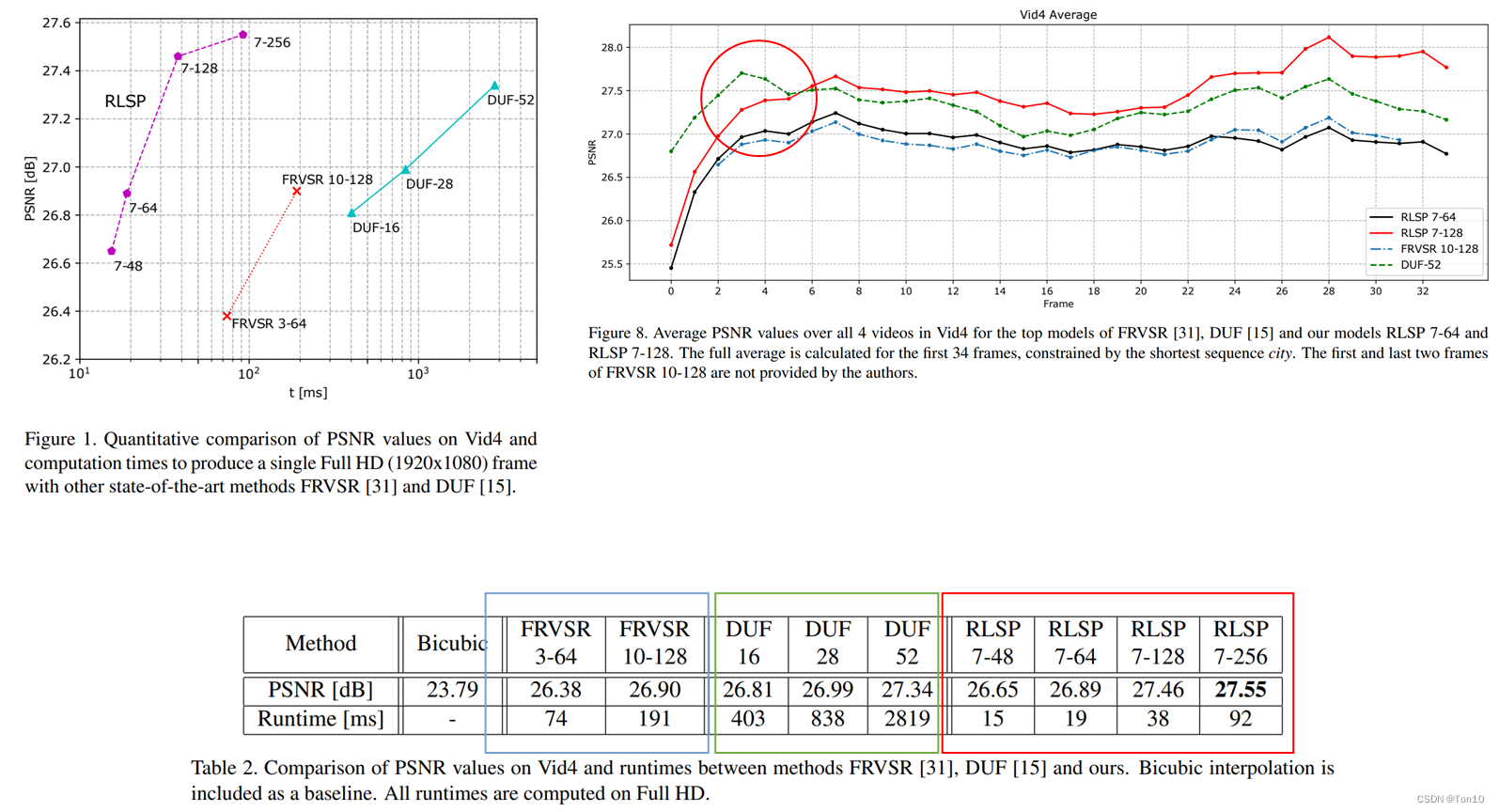
实验结论如下:
- RLSP-7-128每一帧的处理时间是38ms,故1s可以处理25帧,这说明了RLSP-7-128达到了25fps的实时性要求。
- RLSP-7-128在刚开始阶段的PSNR较低是因为其是单向传播模型,只能利用过去的信息,这意味着刚开始的阶段可利用的信息较少,后面阶段可利用的信息较多,所以如Figure 8所示,自然就会造成前几帧各自的PSNR较低,后期就会上升的现象——即信息利用的不公平性问题,可以通过增加后向分支来解决。
- 通过增加cell中滤波器的数量来提升RLSP的表现力。
可视化结果如下:

6. Conclusion
- 本文提出了一个无对齐的VSR模型——RLSP。其将VSR建模成Seq2Seq问题,从而构建RNN结构来实现视频超分。
- RLSP采用①Shuffling;②Residual-Learning;③Feedback;④Hidden-state,共4个tips来实现PSNR的提升。
- RLSP最大的特点就是牺牲了较高的PSNR来提升速度,其7-128模型刚好可以实现实时性要求;通过增加Cell的非线性度(提升深度或宽度)来提升RLSP的表现力。















 2028
2028











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









