







先上图
优化之前
找不到当时的图了,当时一个接口的处理需要花费14s的处理时间,排除网络消耗

优化之后

业务需求背景
我们有一个订单列表是针对业务员的,正常情况下不需要什么优化,但是有一个需求是:相同的人下的单(这样理解简单一些)进行聚合返回数据支持展开,同时业务员下单的数据不支持合并,那么就存在两个问题。
1.无法分页,因为部分合并部分不合并,没办法通过数据库查询出来结果分页。
2. 数据如果在分页完之后在合并可能存在第二页的数据没有合并到一起的问题。
3. 因为第二个问题的原因,导致需要从数据库一次取出来大批量的数据放入内存中处理,SQL检索缓慢、内存可能存在OOM,无法从物理层面直接分页等问题。
改造思路
过去的解决方案
过去的代码,高耦合,低内聚,不可扩展,违反设计模式多个原则导致根本无人敢动,伪代码如下:
if (userType == user) {
// 此处是用户端的处理
if (orderStatus == toBeCollection) {
// 此处是待揽收的代码
} else if (orderStatus == toBeWrehousing) {
// 此处是待入库的业务逻辑代码
}
} else if (userType == staff) {
//此处是员工的业务处理,其次后面是状态和特殊处理,比如:查出符合的全部订单之后,内存进行合并等操作
}
SQL层面:拆分多个大批量的查询数据,因为sql层面无法分页,可能导致查询出的结果上千甚至上万条记录,随后大批量的读取到Java内存中,会导致存在以下问题
- 将JDBC层面的ResultSet解析成为Java对象,那么意味着需要创建上万个Java对象的集合,最后还要对这上万记录进行合并排序等个性化操作,导致数据量过大。对这么庞大的集合进行处理操作实在是太慢
改造之后的方案
接口层面
由接口层面直接区分user和staff两个不同的群体直接拆开,因为从职责划分本身就毫不相干的两个群体写在一起过于难看和耦合了。
代码设计改造
首先从代码结构上去改造,之前的代码结构可以说相当混乱。面对经常改动和拓展的多Tab分区无法满足随时变更和拓展,无法快速定位问题和优化。
因此设计了以下的解决方案,采用多策略对一级Tab和二级Tab的拓展和业务职责划分。
草图如下:
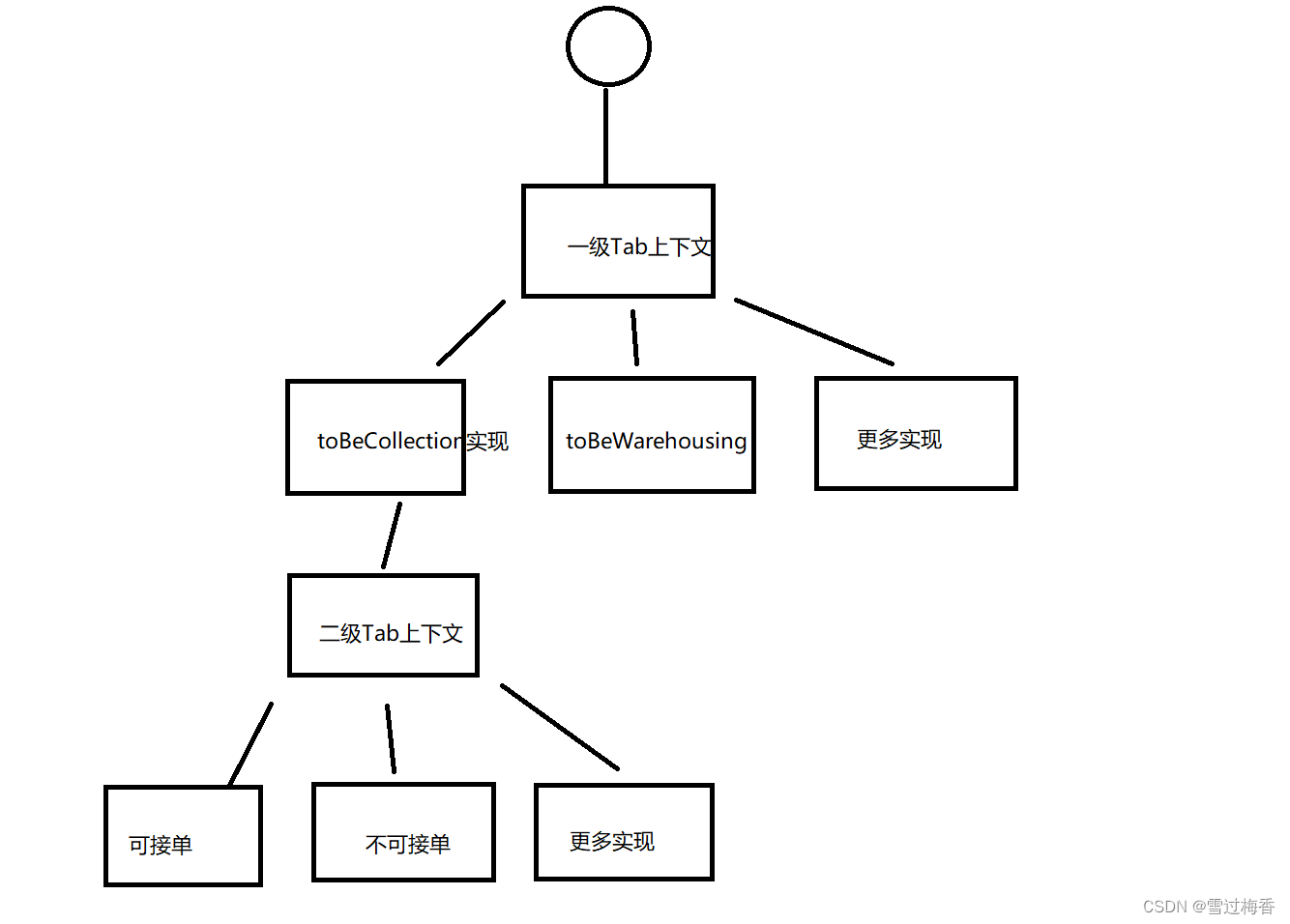
上下文是单例,互相之间可以直接引用共享的,无需多次创建和维护到内部成为其属性
这样当前端指定Tab就可以自动去匹配到最终的二级Tab的具体实现,最终查询出需要的结果。
该操作实现了一定程度的业务实现职责划分明确,高拓展,低耦合,对于日后的维护起到了很好的基础
借鉴过去
之前的逻辑不能说不对,分组拿到Java层面去处理大批量的数据创建对象没问题,因为这样可以实现对应的业务需求,但是存在的问题也很明显。
于是从该层面出发开始思考,能不能MySQL层面把数据合并之后Java在处理呢?但是MySQL返回结果没有那么丰富的数据结构啊?于是就有了以下的巧思:
假设是通过senderRegionId进行合并字段
- 原有的查询结果可能是这样的
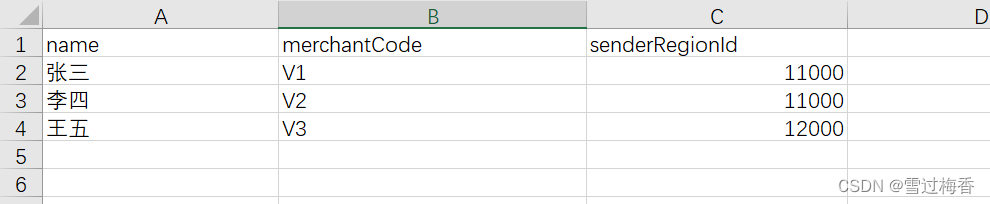
然后在Java层面通过Map结构对senderRegion进行合并就会形成以下2个的对象:
List<Object> list = {张三, 李四} 和 List<Object> list = {王五}
但是假设如果存在一万个行的结果,对于Java需要找出1万行对应的结果进行合并,单从大数据表查询出来一万行的sql执行实行都过于慢了,后续的合并代码逻辑也是极其复杂,如:合并的要在非合并的上面,合并里面的数据要时间倒序、非合并的也要倒序。
最关键的慢还是在于对于合并数据无法解决分页的问题导致查询的结果集行过于庞大
有人可能说,可以分页之后对结果分页啊?那么当前页需要合并的数据并不一定是全部的数据,同时当前页合并的数据可能从10条变成了8条,如何保证每一页是10条呢?同时还需要满足一个,所有只要存在合并的,无论当前是第几页,展示完所有合并的结果之后才是非合并的数据,不可能第一个五个合并,4个非合并。到了第二页之后,竟然还有合并数据?所以就不符合业务场景了
- 鉴于之前的解决思路,开始着手思考能不能在MySQL层面把数据合并的问题解决,减少MySQL到Java层面的对象ResultSet的转换消耗的同时,能完成
真分页的解决,开始思考Group By 去解决,终于有了以下认为可行的方案,先看最终查询结果集和上面的对比:
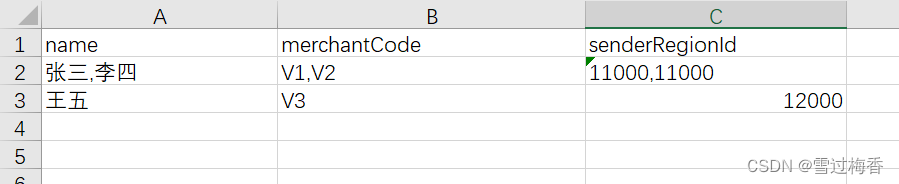
可能看出来了,这个结果集是不是减少了1行ResultSet的返回,同时肯定减少了Java对象的创建消耗,更别提不需要的对象创建了。
那么在上面的查询结果中,基于GROUP BY 对senderRegionId 分组,再使用GROUP_CONCAT对合并结果合并,那么是不是证明通过GROUP_CONCAT 合并结果存在多条的就是合并的数据,而仍然是一个对象的是不是就是表示是非合并数据?
那么这个时候再将合并结果返回到Java创建2个对象,在对合并对象进行分隔符解析转换成所需要的真实对象,组装成Group即可。
面对上面的结果,我想写个LIMIT 10, ORDER BY 一下对于各位应该都不难了吧。
这一步做完,就解决了剩下的2个问题,1.无法分页的问题。2.大批量ResultSet导致JavaOOM和解析对象消耗时间过长
同时切记一定要创建好索引,写一个伪SQL吧
SELECT GROUP_CAONCAT(a.name) AS name, ... FROM
(SELECT name,... FROM table WHERE name = '123') AS a
GROUP BY name,...
// 需要注意的是,在实际代码开发中还遇到怎么直接在sql层面让合并的直接置顶呢?在合并结果集后面不能单纯的追加 ORDER BY name DESC,
// 两个原因:字符串类型MySQL排序存在非理想的排序。2.GROUP BY 后面的Order By 无法直接对group过后的字段进行排序
// 所以这样改造。
SELECT GROUP_CAONCAT(a.name) AS name, ... FROM
(SELECT name,... FROM table WHERE name = '123') AS a
GROUP BY name,...
ORDER BY LENGTH(GROUP_CONCAT(a.name));
// 这样就可以实现 合并最多的数据保证在最上面啦,又有同学问啦,怎么解决时间排序的问题呢,那么就在子查询解决就好了。
SELECT GROUP_CAONCAT(a.name) AS name, ... FROM
(SELECT name,... FROM table WHERE name = '123' ORDER BY create_time DESC) AS a
GROUP BY name,...
ORDER BY LENGTH(GROUP_CONCAT(a.name));
// 剩下的思路就交给大家吧
最终结果电脑不在身边,下次截个图再更新一下。
重要的还是思路。有很多巧思或者数据处理的优先级都能影响到效率,我只是把合并的逻辑放到MySQL,Java层面想办法解析出合并的数据,就可以拥有这么大的提升,对我本人也是蛮震撼的。 冲鸭~














 98
98











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









