 RAG技术解析
RAG技术解析




公众号本本:【RAG探索第1讲】通过大模型读取外部文档的创新探索与自适应策略
今天是2024年7月3日,星期三,北京。
今天我们来看看两个问题:如何通过大模型来读取外部文档?在读取文档的过程中,如何根据问题难度自适应读取外部文档?
看了一些论文,提供了一些解决思路
问题1:如何通过大模型来读取外部文档?
最近关于RAG的文章越来越多,在看的过程中看到一些有意思的文章。
《Query2doc: Query Expansion with Large Language Models》
原文网址:https://arxiv.org/abs/2303.07678
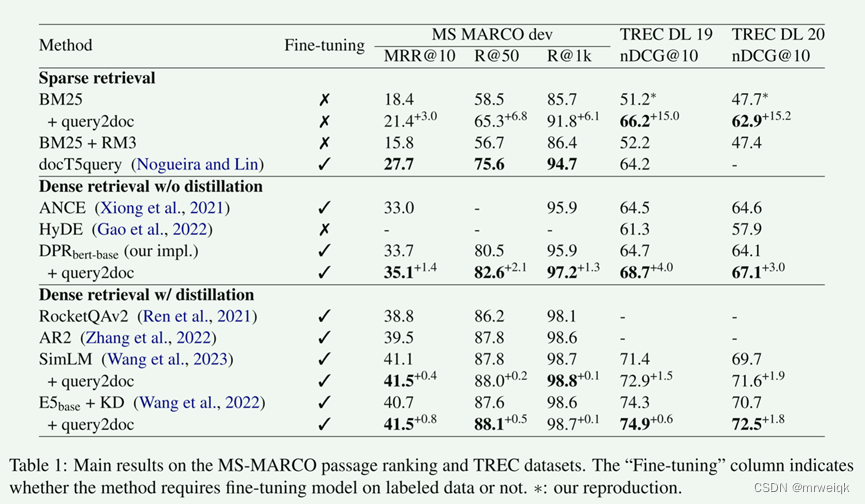
当前主流的检索方法有两种:一种是基于词汇的稀疏检索,一种是查询改写(根据外部信息)。 对于稀疏检索来说,文档扩展的方法被证明是有效的(document expansion methods like doc2query (Nogueira et al., 2019) have proven to be effective for sparse retrieval) 这篇论文提出:通过少量提示 LLM 生成伪文档,并将它们与原始查询连接起来形成新查询。
 首先对一个查询q,采用小样本prompt的方法生成伪文档d1,并生成k个标签,接着把q和d1拼接生成最终的查询q_last。 因为q要比伪文档短好多,所以,复制了n份(一般是5)查询q,使得最终权重一致。
首先对一个查询q,采用小样本prompt的方法生成伪文档d1,并生成k个标签,接着把q和d1拼接生成最终的查询q_last。 因为q要比伪文档短好多,所以,复制了n份(一般是5)查询q,使得最终权重一致。
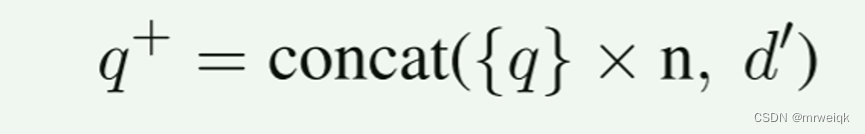
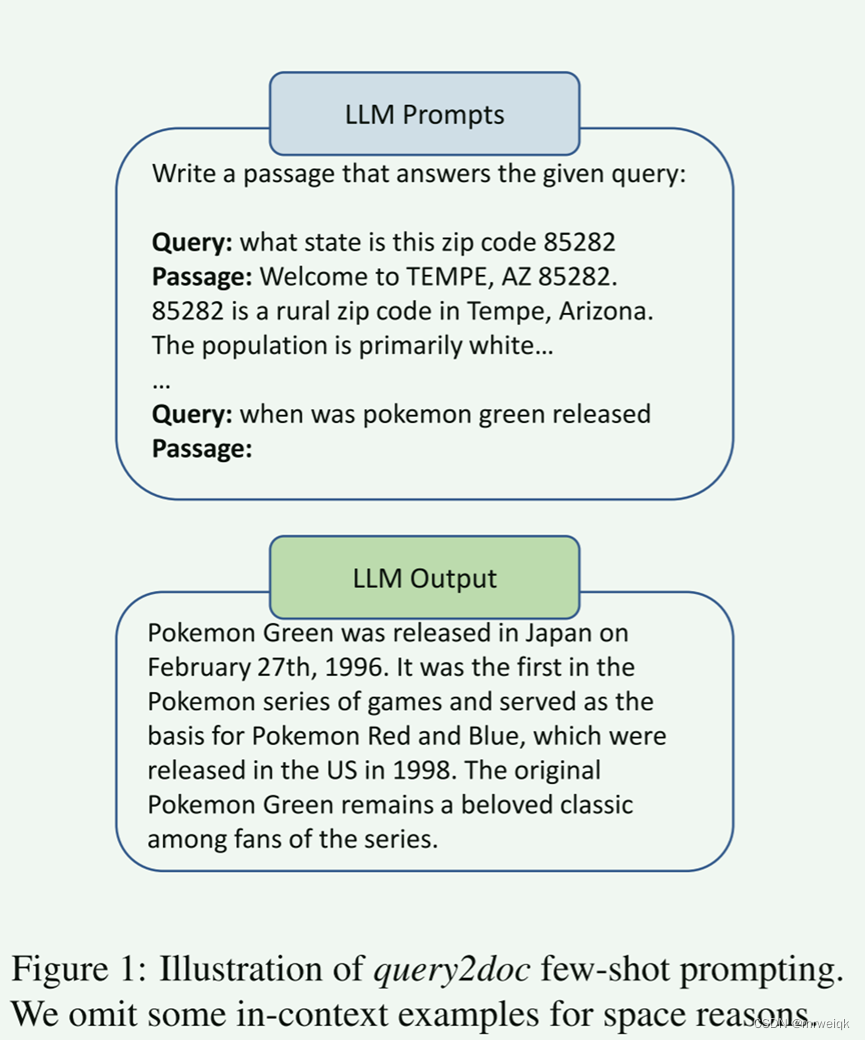
问题来了,伪文档是什么?Fig. 1中解释了这个问题,通过一些prompt来让大模型生成对应的伪文档。
问题2:在读取文档的过程中,如何根据问题难度自适应读取外部文档?
《Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity》
代码链接:https://github.com/starsuzi/Adaptive-RAG。
原文链接:https://arxiv.org/abs/2403.14403
检索增强大型语言模型 (LLM) 将外部知识库中的非参数知识纳入 LLM,已成为提高问答 (QA) 等多项任务响应准确性的有前途的方法。 然而,尽管有多种方法可以处理不同复杂度的查询,但它们要么处理具有不必要的计算开销的简单查询,要么无法充分解决复杂的多步骤查询; 然而,并非所有用户请求都只属于简单或复杂类别之一。 在这项工作中,我们提出了一种新颖的自适应 QA 框架,该框架可以根据查询复杂性从最简单到最复杂的策略动态选择最适合(检索增强)LLM 的策略。 此外,这个选择过程是通过分类器来操作的,分类器是一个较小的 LM,经过训练,可以使用自动收集的标签来预测传入查询的复杂性级别,这些标签是从模型的实际预测结果和数据集中固有的归纳偏差获得的。 这种方法提供了一种平衡的策略,在迭代和单步检索增强的 LLM 以及非检索方法之间无缝适应,以响应一系列查询复杂性。 我们在一组开放域 QA 数据集上验证了我们的模型,涵盖多种查询复杂性,并表明与包括自适应检索方法在内的相关基线相比,我们的模型提高了 QA 系统的整体效率和准确性。
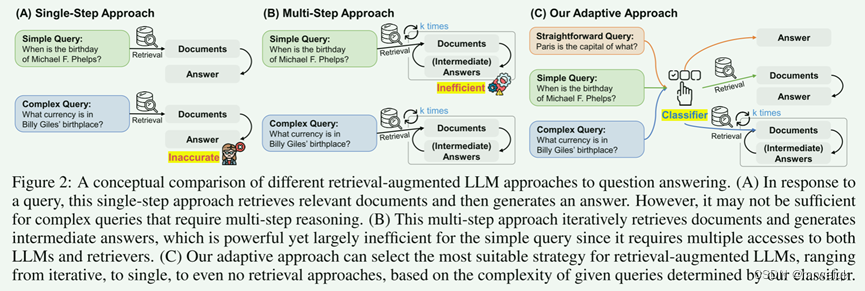
这篇论文讲了一个 单跳检索、多跳检索的内容。从图中可以很明显看出这篇论文主要的动机和创新的思路。
在给定query以后,分类器设计三个标签:“A”、“B”和“C”,其中“A”表示 q 是直接的并且可由 LLM(q) 本身负责,“B”表示 q 具有 中等复杂度,至少需要单步方法 LLM(q, d),“C”表示 q 很复杂,需要最广泛的解决方案 LLM(q, d, c)。除此以外,如果单步和多步方法都产生相同的正确答案,则选择简单的模型来进行回答。
对于简单的单跳,可能LLM自己可以回答出来(有些场景需要检索也可以回答出来)
对于多跳,常规的多跳需要多次访问大模型,这比较浪费时间。 该文设计了一个自适应的方法,使用LM做了一个简单的分类器,这样可以节省时间。
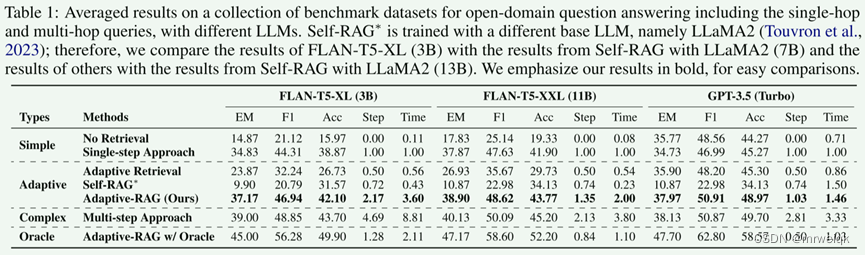
数据集分两个类别:单跳数据集:1) SQuAD v1.1 2)Natural Questions 3)TriviaQA 多跳数据集:1) MuSiQue 2) HotpotQA 3) 2WikiMultiHopQA
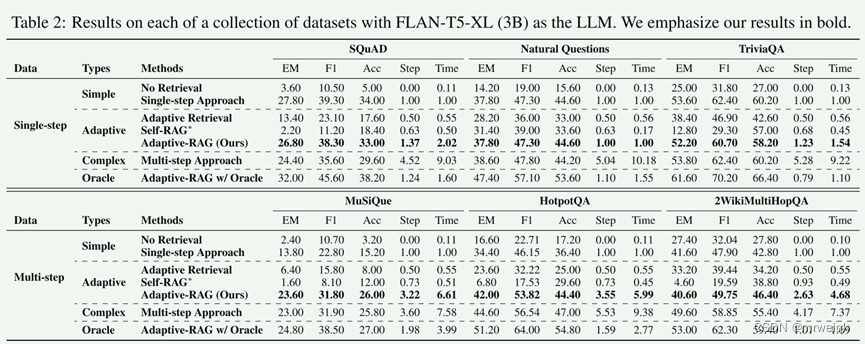
测量指标:F1测量预测答案和真实答案之间重叠单词的数量,EM测量它们是否相同,Acc测量预测答案是否包含真实答案。
总结
今天,我们探讨了两个关于大模型读取外部文档的问题:其一是如何通过大模型读取外部文档,另一个是如何根据问题难度自适应读取外部文档。
首先,关于如何通过大模型读取外部文档的问题,我们讨论了一篇有趣的论文《Query2doc: Query Expansion with Large Language Models》。该论文提出了一种通过大模型生成伪文档,并将其与原始查询拼接形成新查询的方法。通过这种方式,可以有效提高检索结果的准确性。
接着,我们讨论了自适应读取外部文档的问题,引用了论文《Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity》。该论文提出了一种自适应的问答框架,通过训练一个分类器来预测查询的复杂性,从而选择最适合的检索增强策略。通过这种方法,可以在响应各种复杂度的查询时实现效率和准确性的平衡。
这两篇论文为通过大模型读取外部文档提供了新的思路和方法,不仅提升了检索结果的准确性,也优化了处理不同复杂度问题的效率。
相关阅读
大模型名词扫盲贴
RAG实战-QAnything
提升大型语言模型性能的新方法:Query Rewriting技术解析
一文带你学会关键词提取算法—TextRank 和 FastTextRank实践


















 672
672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









