







https://www.cnblogs.com/guoyaohua/p/9240336.html
统计语言模型(Statistical Language Model)
N-GRAM
参数容易爆炸,长文本无法处理, 还是没有考虑词与词之间的内在联系性,一个个孤立的原子单元。
词向量获取的方法
基于奇异值分解的方法
- 单词 - 文档 矩阵
相关词,往往出现在同一文档中, 建立 词和文档的矩阵,对矩阵做奇异值分解,获取词的向量表示。
2)单词 - 单词 矩阵
一个词的含义,由上下文信息决定。 两个词之间的上下文相似, 那么这两个词就可能非常相似。 设定上下文窗口, 建立 词和词之间的共现矩阵, 对共现矩阵做奇异值分解,获取词向量。
基于迭代的方法
基于迭代的方法,获取词向量,大多数是基于语言模型的训练得到的。
Distributed Representation
用一个连续的稠密向量去刻画一个word的特征。
词袋模型
TF.IDF
Neural Network Language Model
A neural probabilistic language model, 首次提出word embedding概念。

- 输入one-hot, C矩阵存储要学习的词向量矩阵。
- 前向反馈神经网络g,由tanh和softmax组成,
word在context下的条件概率: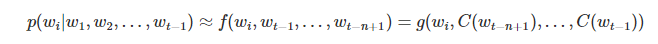
训练目标是最大化以下似然函数:
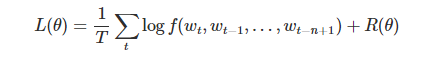
解决了数据稀疏问题,语义鸿沟问题。可以在连续空间中对文本序列建模。
NNLM存在的问题:
1)训练过慢,
2)只能定长,
CBoW & Skip-gram Model
word2vec的两种方法。
CBow(Continuous Bags-of-Words Model)

为了训练该模型,要先定义目标函数,然后采用梯度下降法,去优化模型。目标函数采用交叉熵函数:

最大化背景词生成任一中心词的概率。

最终,使用CBow的背景词向量。
直接使用梯度下降,开销很大,与词典V的规模有关。使用近似的方法计算梯度。
如图,时间窗口为2,
一个词袋模型的向量 * 一个embedding矩阵,得到一个连续的embedding向量。 从context对target word的预测中学习到词向量的表达。
Skip-gram

如图,中心词,只生成邻近距离为2的词,时间窗口为2(与N-Gram类似)。
长度为T的文本序列,时间窗口为m,跳字模型需要最大化给定任一中心词生成所有背景词的概率:
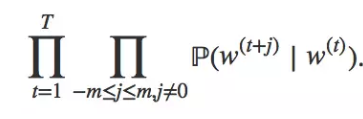
最大化以上的似然函数,也可以最小化以下的损失函数。
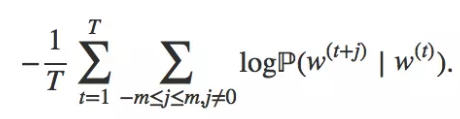
反过来,从target word对context预测中,学习word vector(在训练时,对上下文里的word进行采样)。
给定任一中心词wi,产生背景词wo的概率。(v、u表示中心词和背景词的向量)softmax函数定义:
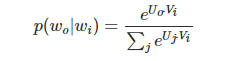
梯度更新迭代中心词和背景词的向量,可以得到该词作为中心词和背景图两组词向量。一般,会使用skip-gram模型的中心词向量。
本质是计算输入word的input vector 和 目标word的output vector之间的余弦相似度,用softmax归一化。当词典规模过大时,softmax计算开销很大,因此,使用近似方法求解参数,用以下两种优化算法:
1) 层次softmax(Hierarchical softmax)
特征重要性时,会用树结构,每次分裂时,选择包含信息量大的特征。
用Huffman树,V个词都是二叉树的叶子结点,上面有V-1个非叶子结点。n(w, j)表示从根节点到词w的路径上的第j个结点。
叶子节点的词没有直接输出向量, 非叶子节点都有相应的输出向量。
要计算的是目标词w的概率,
https://blog.csdn.net/imsuhxz/article/details/82115681

给定词wi,生成词w的条件概率。
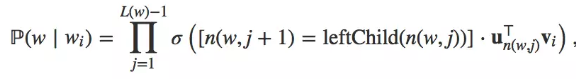
词向量和二叉树中非叶子结点向量是需要学习的模型参数,
计算开销从O(V)下降到O(log2|V|)
对低频词效果好。
Huffman编码
是一种 无损 数据压缩的 熵编码(权值编码) 算法。
评估符号出现的概率, 出现概率高的符号使用较短的编码,出现概率低的使用较长的编码。
Huffman编码 又称为 最优二叉树,表示一种 带权路径长度最短的 二叉树。叶子节点的权值 乘以 该节点到根节点的路径长度。
上面节点的权值大于下面的。 左节点的权值大于右边的。(权值就是词频)
2)负采样(Negative Sampling)
对高频词效果好。
(负采样与正采样相对应。给定一个上下文词(context), 目标词也在上下文中,则这一对就是正采样; 给定上下文中的一个词,目标词是不在上下文的,字典里随机选取的,则这一对就是负采样)
背景词预测中心词, 这个中心词是标准答案,是正例;其余的所有词就都是负例,从其它所有词里面抽取负采样样本。
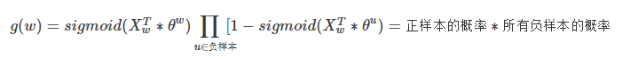
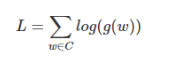
词典很大时,我们负样本取少量时,计算开销就很小。
https://www.cnblogs.com/ooon/p/5558119.html
词与句子的嵌入,是基于深度学习的nlp系统的重要组成部分,在固定长度的稠密向量中编码单词和句子,提高神经网络处理文本数据的能力。
趋势是:对通用嵌入的追求,在大型语料库上预训练好嵌入,可以插入到各种下游任务中,这是一种迁移学习。
https://www.jianshu.com/p/a6bc14323d77
Glove 词向量
Glove(Global Vectors for Word Representation)
基于全局词频统计(count-based & overall statistics)的词表征(word representation)工具。
根据语料库构建一个共现矩阵X , 矩阵中每个元素Xij 表示单词i 和 上下文单词j 在特定大小的上下文窗口内 共同出现的次数。
两个单词在上下文窗口的距离为d,1/d作为权重 。 距离越远的两个单词,所占总计数的权重越小。
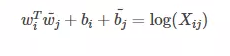
wi wj这两个是最终要获取的词向量。 bi bj这两个是词向量的bias。

根据上述公式,获得的loss函数。
Pik / Pjk, 这个共现概率的比率, 依赖于三个单词i,j, k。
评价:
word2vec只是在局部上下文窗口上,训练模型。很少使用语料中的一些统计信息。
Glove的优缺点:
LSA 计算代价较大,对所有单词的统计权重都是一致的。
word2vec没有充分利用语料。
Glove克服了上面的缺点。
Elmo(Embeddings from Language Models),
https://blog.csdn.net/triplemeng/article/details/82380202
http://www.sohu.com/a/281795578_473283
来自于语言模型的词向量表示,利用深度上下文单词表征,优势在于:
1)处理单词用法的复杂特性(句法,语义)
2)用法在不同语言上下文中的变化(词的多义性)(最大的不同)
词向量不是一成不变的,根据上下文随时变化。
ELMO模型是Bi-LSTM的多层表示的组合,基于大量文本,从深层的模型中的**内部状态(internal state)**学习而来。 这些词向量很容易加入到多种nlp任务中。
在大型语料库上训练一个深度双向语言模型(BiLM), 把它的内部状态学到的函数作为词向量。这些学到的词表征,在多项nlp任务上都有大幅度提升。
预训练模型的深度内部状态 这个非常重要,
Bidirectional language models

t1, t2, t3, ,是一系列的tokens, 利用多层的LSTM实现这种, ELMO语言模型就使用了stacked bidirectional LSTM来表示。
如下图中,biLSTM只叠加了两层, 第一层对应低层,找到语法方面的特征(比如词性标注), 第二层对应高层,捕捉词于在语境中的意义和特征。底层和高层结合,发挥更大的优势。(这里只有两层,层数可以再加,具体效果需要实验验证)

Elmo 训练
https://www.cnblogs.com/robert-dlut/p/9824346.html (最棒的链接)
两个方向语言模型的最大似然。直接加和。

Elmo获取词表示
把双向语言模型的每一个中间层进行一个求和,或者使用最高层的表示。
ELMO利用预训练的biLM产生词向量,
具体使用,ELMO一般都会在自己任务的语料库上进行微调,保证对新domain的适应。
具体来讲如何使用ElMo产生的表征呢?对于一个supervised NLP任务,可以分以下三步:
1)产生pre-trained biLM模型。模型由两层bi-LSTM组成,之间用residual connection连接起来。
2)在任务语料上(注意是语料,忽略label)fine tuning上一步得到的biLM模型。可以把这一步看为biLM的domain transfer。
3)利用ELMo的word embedding来对任务进行训练。通常的做法是把它们作为输入加到已有的模型中,一般能够明显的提高原模型的表现。
多层表征进行叠加,来代表相应位置的向量,效果会更好。
https://www.cnblogs.com/jiangxinyang/p/10235054.html
增量训练学习:使用小批量的数据学习,是这种学习方式的核心,
CHIP项目中,使用给定的词向量作为ELMO的输入,利用ELMO去更新迭代给定的词向量,保存训练好的词向量作为最终的增量词向量。
BERT
bert要解决的问题:
比较好的一篇文章。。
https://www.cnblogs.com/jfdwd/p/11202021.html
http://www.sohu.com/a/281795578_473283
https://zhuanlan.zhihu.com/p/46652512
(Bidirectional Encoder Representation from Transformers),双向transformer的encoder。。。主要是用来训练语言模型的,所以需要encoder的部分。。
BERT建立在目前nlp中很多聪明方法之上,半监督序列学习,ELMO,Transformer
堆叠的transformer块,互相连接。。。

两个任务: masked lm 和 next sentence prediction。。
一个训练好的Transformer Encoder堆栈。

BERT模型有大量的编码器层(Transformer Blocks)
与CV里面的VGG-Net网络很相似。

创新点:
1)BERT聪明的语言建模任务遮盖了输入中15%的单词,并要求模型预测丢失的单词。 (可以从任何方向上去预测mask词,不仅仅是单向的) (deep bi-directional)
2)预测下一个句子。 (学习句子之间的关系,二分类问题,句子和下一个句子进行拼接,标为正例;不是下一句子,标为负例)
最后目标函数:上面两个任务进行目标函数求和取似然。
3)使用transformer encoder,多层堆叠。 基于self-attention,模型上下层直接全部互相连接。 (Elmo只是两个单向的简单拼接, GPT是基于transformer decoder,从左到右受限制的transformer)

BERT:
数据,模型,算力, 应用。
微调,要用谷歌的TPU。
1, 也是无监督的,充分利用大量未标注数据,数据量足够大;
2. transformer, 学习多个方向的语义关系。
3. mask,强迫学习上下文关系。
https://www.jianshu.com/p/4dbdb5ab959b?from=singlemessage
BERT的缺点:
由于需要mask一部分输入,忽略了被mask位置之间的依赖关系,预训练和微调效果存在差异。预训练有mask词,微调的时候没有。
bert模型的最新进展:
ERNIE from Baidu, 针对NLP在中文上的表现,进行了改进。。(针对分词粒度, 基于字mask,词mask,短语mask。。)
ALBERT: 原始bert模型过于庞大复杂,对其进行瘦身。。因式分解词向量参数,交叉参数共享,去掉预测下一句任务,句子排序任务(自监督学习)。。
XL-Net
(泛化的 自回归预训练模型) 最大化所有可能的因式分解顺序的 对数似然, 学习双向语境信息。 融合了 当前最优的自回归模型Transformer-XL。
集合了AR(自回归)和AE(自编码)方法的优势,又避免了二者的缺陷。














 573
573











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









