










上周我们讨论了OpenAI 最新的 o1 模型系列,探索它如何利用人工智能中一个有趣的范式进行测试时间计算,或者更简单地说是“推理”。
我们讨论了 o1 实时调整推理过程的能力如何带来更灵活、更强大的人工智能系统,当模型遇到新问题或复杂问题时尤其有用。不幸的是,这种“推理”在生成时间(延迟)和成本(需要生成更多标记才能回答)方面有很大限制。
💡 回顾:OpenAI 的 o1 模型系列OpenAI 的 o1 模型系列在生产环境中使用 LLM 引入了测试时(当用户与模型交换时)计算。这允许模型在生成最终答案之前执行额外的推理步骤(在推理时)。
我们当前人工智能推理方法的一个关键问题可以用一句话来概括:“我们教会机器我们思考的方式。”它反映了基于人类直觉的训练模型的更深层次缺陷,而这不一定是推理的真正运作方式(没人知道)。这开启了一场更广泛的讨论,即机器如何独立发展推理技能,而不仅仅是模仿人类的方法。
在此基础上,我们想分享一些令人兴奋的进展,这些进展重塑了人工智能模型的推理学习方式。这些进步以自学推理为中心,人工智能模型通过从自己的推理过程中学习来增强其能力。
传统上,提高 AI 模型的推理能力需要使用标注有人类推理步骤的大型数据集(或使用思路链提示技术,每次都必须提及,并且在模型训练期间无法改进)。使用注释既费时又费钱,限制了模型接触各种问题解决策略的机会。它严重依赖人类的专业知识来指导模型的学习,当我们需要海量单词的大型数据集时,这可能会成为定价方面的瓶颈。
那么,让人工智能模型自学如何更有效地推理呢?我们不必依赖大量人工注释的数据,而是可以使用强化学习技术,使用相对较小的数据集,并使用模型自己生成的推理步骤来不断改进。这种自我改进循环使模型能够从成功和错误中学习,从而变得更加智能和有能力。
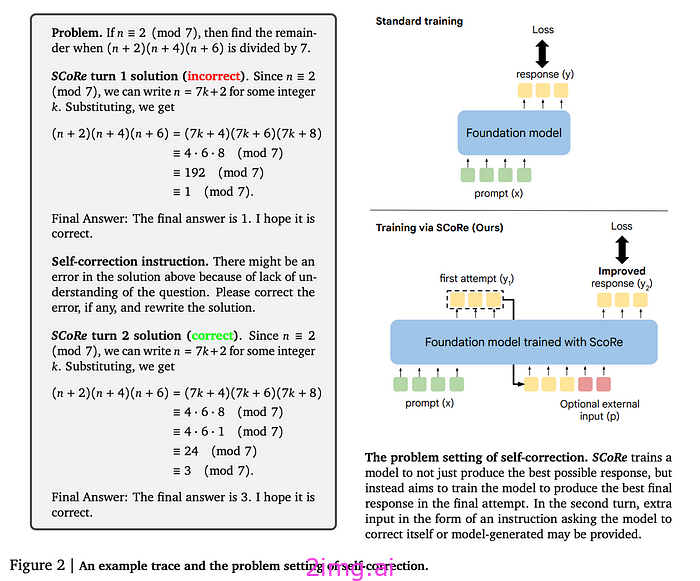
基于人工智能自学推理的概念,一种最新的方法SCoRe(通过强化学习进行自我纠正)取得了重大进展,与 OpenAI 的 o1 模型系列的功能非常相似。与 o1 一样,SCoRe 使模型能够通过多轮交互迭代地改进其响应,从而在推理过程中进行自我纠正。SCoRe 不依赖于大型、预先注释的数据集,而是允许模型使用自生成的数据来提高其性能,在推理过程中逐步改进其推理。通过使用强调成功纠正的奖励来塑造学习过程,SCoRe 与 o1 模型实时调整其推理的能力保持一致,使这两种方法对于解决复杂和新颖的任务都非常有效。这是一张展示 SCoRe 工作原理的论文图片:
o1中的自我纠正自我讨论示例:

提高 AI 推理效率的关键在于教会模型三件重要的事情:
1)常识(例如语言或数学原理);
2)自我意识——知道自己何时不知道答案;
3)推理时实时执行任务,其中模型动态学习并实时适应任务,而不是预先学习所有可能的任务。
这种推理时的动态学习为有效应对不可预见的挑战打开了新的大门。
太棒了!强化学习 (RL) + 高质量数据 + 扩展 = 大脑。听起来很神奇。在实践中如何做到这一点?
💡 强化学习只是锦上添花(正如 Yan LeCun 所说)。它只是功能算法之上的一个优化层。它不是开创性或基础性的工作,但它仍然可以改进特定领域,例如测试时推理。ps,人工智能推理的进步不仅仅是强化学习。进步 = 更少的结构 + 更多的计算 + 更多的数据。我们已经看到,放松模型运行的僵化框架,同时增加它们对数据和计算资源的访问,会带来令人惊讶的突破。
该领域的基础工作之一是Zelikman 等人 (2022) 提出的自学推理器 (STaR)方法。
STaR 方法使模型能够使用一小组示例来引导其推理能力,而不是依赖于具有人工注释推理步骤的海量数据集。
该模型试图通过生成逐步解释或“基本原理”来解决问题。然后,它会保留导致正确答案的基本原理,并根据这些成功的例子进行微调,逐步解决更复杂的任务。
在 STaR 的基础上, Hosseini 等人 (2024)提出了自学推理验证 (V-STaR),在模型中引入了一个“验证器”组件。此验证器可帮助 LLM(生成器)评估其自身推理的质量。该模型为每个问题生成多条推理路径,使用正确和不正确的解决方案来训练验证器。
验证器学会区分有效和无效的策略,从而提高模型在面对新任务时选择最准确、最有效的推理路径的能力。然后,我们只需在“思考过程”中生成多个潜在响应,并使用验证器选择最佳响应,我们反复执行此操作以训练 LLM“更好地思考”。V-STaR 可能是 OpenAI 用来训练 o1 的方法(或类似方法)。
💡 这凸显了 AI 开发中的一个关键概念:扩展 = 用更具扩展性的选项取代当前的瓶颈。通过识别和消除模型训练和微调方面的限制,例如训练前限制或测试时计算期间的延迟问题,我们可以更有效地扩展 AI 性能。随着每个瓶颈得到解决,下一个挑战就会出现,但系统会继续改进。
最近的一项研究(由 Google Deepmind 开展)强调,扩展测试时间计算比扩展预训练工作更有效。例如,在某些情况下,在测试时间应用额外的计算(通过计算优化搜索等方法)已被证明比预训练规模大 14 倍的模型表现更好。这表明,我们不必只专注于对大规模模型进行预训练,而是可以通过在推理过程中策略性地分配计算资源来显著提高性能。
这反映了V-STaR和OpenAI 的 o1模型中所使用的方法,其中在测试时间计算和预训练规模之间取得平衡,从而优化在部署期间给您正确答案的概率。
另一项噪音较小的创新是Quiet-STaR,同样由 Zelikman 等人 (2024) 发表。Quiet-STaR 引入了一种有趣的机制,即模型生成的“内部想法”不会直接输出,而是用<|startofthought|>和<|endofthought|>标记标记。这些标记指示模型何时开始和结束其推理过程,类似于模型使用<|endoftext|>标记来表示一代的结束。这种“安静”推理发生在直接输出流之外,但可以显著增强预测,就像 o1 所做的那样。与使用验证器的 V-STaR 不同,Quiet-STaR 依靠一种名为REINFORCE的强化学习方法来优化其推理过程。在这种设置中,模型会生成几个潜在的想法,并收到有关哪些想法有助于解决问题的反馈。这使得模型可以迭代地改进其内部推理,确保未来的决策基于更精细的思考。
就像 o1 一样,这些自学推理方法使模型能够通过迭代自我改进来提高其推理能力。o1 模型的强化学习方法使其能够识别和纠正思路链中的错误,从而实现更具弹性的推理。这反映了 STaR、V-STaR 和 Quiet-STaR 模型如何从自己的推理过程中学习以提高性能。
这对我们为什么重要?
经过自学推理训练的模型可以处理需要多步思考的更复杂任务,例如战略规划、数据分析或细致入微的客户互动。它们能够更好地应对新的和不可预见的挑战,使我们的系统更具适应性和弹性。
这种方法减少了对大型注释数据集的依赖,节省了时间和资源。不幸的是,它在推理过程中也需要更多的计算能力——这一概念现在被称为“测试时计算”。
正如我们在 o1 模型中讨论的那样,增加测试时间计算可以让模型在部署期间执行额外的推理步骤(与训练时间计算相比,见下图),从而在复杂任务上获得更好的性能。

有趣的是,测试时间计算的概念最近已成为人工智能研究的焦点。最新研究表明,测试时间计算(模型在推理过程中执行的额外推理)可以替代更广泛的预训练。采用更高效的测试时间计算方法的模型可以解决通常需要更大的预训练模型的问题,从而可能节省大量资源并提高模型的大规模适应性。OpenAI 研究员 Noam Brown 问道:如果模型可以思考数周来解决复杂问题会怎样?
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











