







写文件大致路径
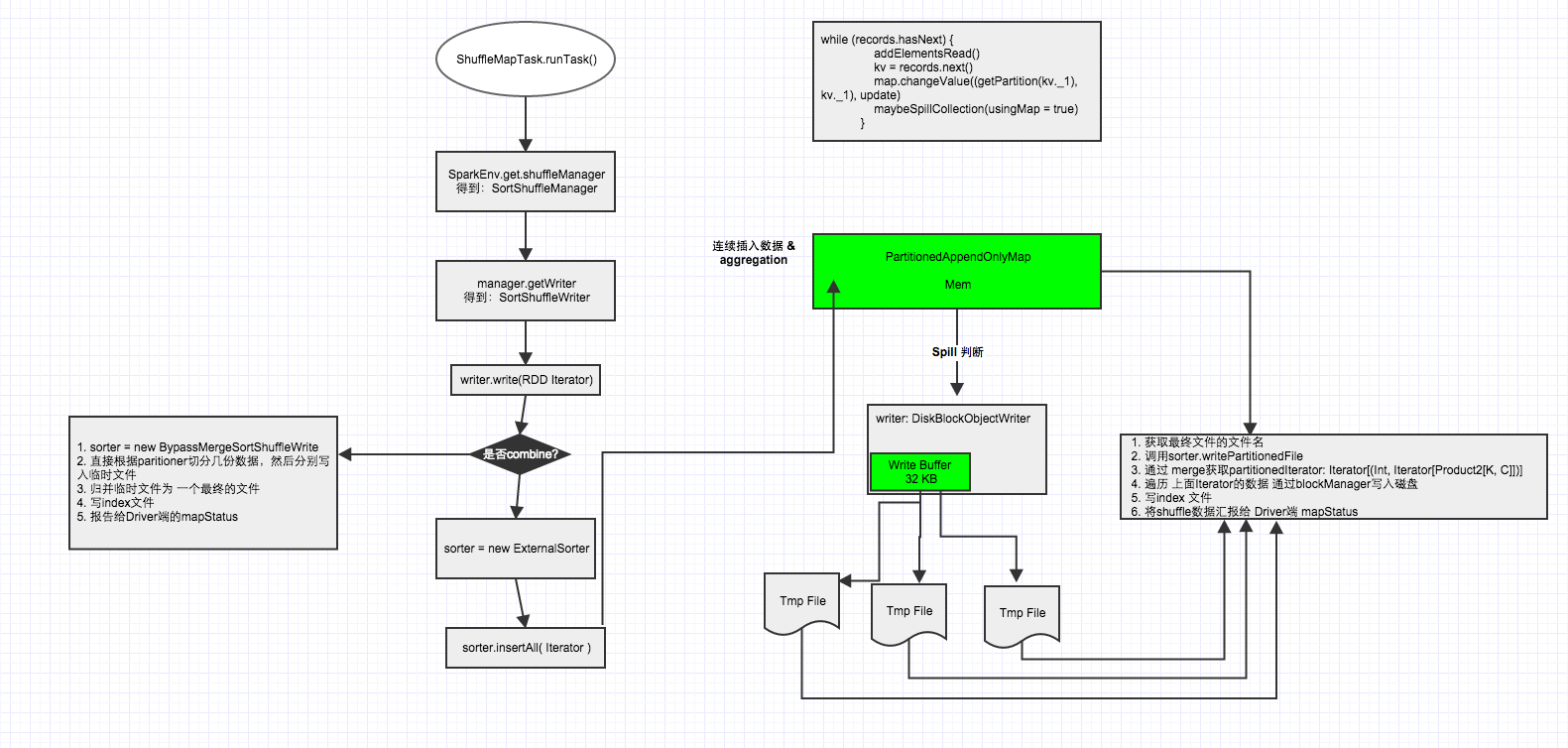
入口是:ShuffleMapTask.runTask()
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
writer.stop(success = true).get- 首先拿到shuffleManager,这里应该是:SortShuffleManager
- 通过shuffleManager拿到ShuffleWriter,这里应该是SortShuffleWriter
- 通过shuffleManager迭代写该任务partition数据
shuffleManager提供了注册shuffle,获取shuffleRead shuffleWriter的功能;
shuffleWriter 提供了写partition数据到磁盘文件功能:根据是否需要进行map端combine,具体实现分别通过ExternalSorter, BypassMergeSortShuffleWriter这两个类(接口为:SortShuffleFileWriter)完成。
public interface SortShuffleFileWriter<K, V> {
void insertAll(Iterator<Product2<K, V>> records) throws IOException;
long[] writePartitionedFile(BlockId blockId, TaskContext context, File outputFile) throws IOException;
void stop() throws IOException;
}先看ExternalSorter的实现:
- sorter.insertAll(records)
while (records.hasNext) {
addElementsRead()
kv = records.next()
map.changeValue((getPartition(kv._1), kv._1), update)
maybeSpillCollection(usingMap = true)
}这里的Map是PartitionedAppendOnlyMap[K, C](Implementation of WritablePartitionedPairCollection that wraps a map in which the keys are tuples
* of (partition ID, K)),这个全内存的数据结构,在存数据时,如果写满了就触发spill操作。对于触发spill操作的条件判断,这里不详细描述。
看看spill实现:
- 获取临时文件名
diskBlockManager.createTempShuffleBlock():”temp_shuffle_” + id - 获取writer
openWriter():diskWriter - 写数据到磁盘
- 记录临时文件到
private val spills = new ArrayBuffer[SpilledFile
写完一个task对应的partition数据后,会做merge操作,把磁盘上的临时文件和内存数据 进行迭代处理得到一个Iterator(详细实现在分析), 这个Iterator会提供给写文件时使用。
(p, mergeWithAggregation(
iterators, aggregator.get.mergeCombiners, keyComparator, ordering.isDefined))输出文件名:
val outputFile = shuffleBlockResolver.getDataFile(dep.shuffleId, mapId)
文件名: "shuffle_" + shuffleId + "_" + mapId + "_" + reduceId + ".data"真正写文件发生在:val partitionLengths = sorter.writePartitionedFile(blockId, context, outputFile)
实现是 ExternalSorter.writePartitionedFile
for ((id, elements) <- this.partitionedIterator) {
if (elements.hasNext) {
val writer = blockManager.getDiskWriter(blockId,
outputFile,
serInstance,
fileBufferSize,
context.taskMetrics.shuffleWriteMetrics.get)
for (elem <- elements) {
writer.write(elem._1, elem._2)
}
writer.commitAndClose()
val segment = writer.fileSegment()
lengths(id) = segment.length
}
}这里最主要的是this.partitionedIterator,源码中介绍为:
an iterator over all the data written to this object, grouped by partition and
aggregated by the requested aggregator. For each partition we then have an
iterator over its contents, and these are expected to be accessed in order (you
can’t “skip ahead” to one partition without reading the previous one).
Guaranteed to return a key-value pair for each partition, in order of partition
ID.
主要就是说:所有的数据已经根据partition分好组和完成聚合,而且根据partitionID进行了排序;即分区排序,分区内的数据完成聚合(未排序)。
这样写文件时,每完成一个分区记录一个fileSegment,并且记录偏移量。后续的reduce就根据偏移量拿到自己需要的数据。
偏移量的索引数据也会被持久化为文件:"shuffle_" + shuffleId + "_" + mapId + "_" + NOOP_REDUCE_ID + ".index"
一个Executor最终的文件数目: maptaskNum
如果map端不需要combine,则使用BypassMergeSortShuffleWriter
insertAll的核心代码:
partitionWriters = new DiskBlockObjectWriter[numPartitions];
for (int i = 0; i < numPartitions; i++) {
final Tuple2<TempShuffleBlockId, File> tempShuffleBlockIdPlusFile = blockManager.diskBlockManager().createTempShuffleBlock();
final File file = tempShuffleBlockIdPlusFile._2();
final BlockId blockId = tempShuffleBlockIdPlusFile._1();
partitionWriters[i] = blockManager.getDiskWriter(blockId, file, serInstance, fileBufferSize, writeMetrics).open();
}
// Creating the file to write to and creating a disk writer both involve interacting with
// the disk, and can take a long time in aggregate when we open many files, so should be
// included in the shuffle write time.
writeMetrics.incShuffleWriteTime(System.nanoTime() - openStartTime);
while (records.hasNext()) {
final Product2<K, V> record = records.next();
final K key = record._1();
partitionWriters[partitioner.getPartition(key)].write(key, record._2());
}
for (DiskBlockObjectWriter writer : partitionWriters) {
writer.commitAndClose();
}根据numPartitions来创建对应数目的DiskBlockObjectWriter,即写临时文件的handler,每个handler需要32KB 的Buffer。
主要过程:遍历该map任务的分区数据,然后通过hash(partitioner.getPartition(key))确定该record写入到那个临时文件,然后通过DiskBlockObjectWriter写入到临时文件。
数据都写入临时文件之后,就是文件归并为一个最终的文件,核心代码如下:
final FileOutputStream out = new FileOutputStream(outputFile, true);
final long writeStartTime = System.nanoTime();
boolean threwException = true;
try {
for (int i = 0; i < numPartitions; i++) {
final FileInputStream in = new FileInputStream(partitionWriters[i].fileSegment().file());
boolean copyThrewException = true;
try {
lengths[i] = Utils.copyStream(in, out, false, transferToEnabled);
copyThrewException = false;
} finally {
Closeables.close(in, copyThrewException);
}
if (!blockManager.diskBlockManager().getFile(partitionWriters[i].blockId()).delete()) {
logger.error("Unable to delete file for partition {}", i);
}
}
threwException = false;
} finally {
Closeables.close(out, threwException);
writeMetrics.incShuffleWriteTime(System.nanoTime() - writeStartTime);
}即将所有临时文件的数据逐一复制到最终的文件里。
在这一部分主要消耗内存的部分是DiskBlockObjectWriter的 32KB Buffer。如果reduce任务1000个,一个map任务需要消耗的内存就是 1000x32KB。 如果当前正在执行的task任务数目为 C 个, 那么map总消耗内存为 1000x32KBxC 。
注意根据这里的内存消耗 配置合适的reduce任务数目, 比如reduceBy(…, num)这里的num不能设置过大。















 5175
5175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









