






 文章描述了一种通过阿里云SDK和ScheduledSQL解决CDN日志按天粒度分析的方法,针对音频、视频和图片业务分类统计流量占比和PV。由于原始日志量大,直接查询导致超时,最终通过定时任务和新日志库存储来提高效率和准确性。
文章描述了一种通过阿里云SDK和ScheduledSQL解决CDN日志按天粒度分析的方法,针对音频、视频和图片业务分类统计流量占比和PV。由于原始日志量大,直接查询导致超时,最终通过定时任务和新日志库存储来提高效率和准确性。
需求
按天粒度分析阿里云所有域名的CDN日志,按文件后缀区分业务,统计流量占比、总流量、PV。
业务分类如下:
音频:
mp3、.wav等
视频:
mp4、mpg等
图片:
png、jepg等
构思
第一确认:
接口采用GET请求方式,根据URL中的日期参数,返回JSON格式的统计数据
第二确认:
阿里云CDN服务不支持自定义归类,只能利用CDN日志进行统计,通过对uri字段后缀名判断进行业务分类,对response_size字段进行汇总得出流量大小
注:response_size统计的大小不完全等于CDN流量的实际大小,业内一般差额在7%~13%,阿里云采用的是10%差额
第三确认:
原设想用GO语言,但通过学习阿里云日志服务接口文档,发现GO的文档太少,而Python的文档则很丰富,最终选择使用Python
第四确认:
最核心的问题,如何统计日志。之前使用方法是每日将日志下载到服务本地,在本地计算,果断弃掉这个方法,太重了。通过学习阿里云SDK文档,发现支持SQL,确定利用阿里云在线检索,但海量的日志检索,必然存在返回时间过长的问题,通过需求沟通,对时间没有特殊要求,只要能够返回数据就行。
示例代码:
from time import time
from aliyun.log import GetLogsRequest
request = GetLogsRequest("project1", "logstore1", fromTime=int(time()-3600), toTime=int(time()), topic='', query="*", line=100, offset=0, reverse=False)
# 或者
request = GetLogsRequest("project1", "logstore1", fromTime="2018-1-1 10:10:10", toTime="2018-1-1 10:20:10", topic='', query="*", line=100, offset=0, reverse=False)
res = client.get_logs(request)附链接:https://aliyun-log-python-sdk.readthedocs.io/README_CN.html#get
遇到的问题:
在测试过程中,发现将检索时间大于1小时后,就会出现检索超时或者返回数据不准确的问题。原因是日志量太大并且SQL语句判断太多,虽然早有预期执行SQL会消耗不少时间,但超时和检索结果不准的情况还是有点出乎意料,与阿里云客服沟通,检索量触发了阿里云的流量限制。根据客服的建议之一,使用SQL增强功能,依然无改善。
尝试客服建议的另一个方案——Scheduled SQL,大致原理是设置定时任务定期执行SQL,并将执行结果储存到单独的日志库内。
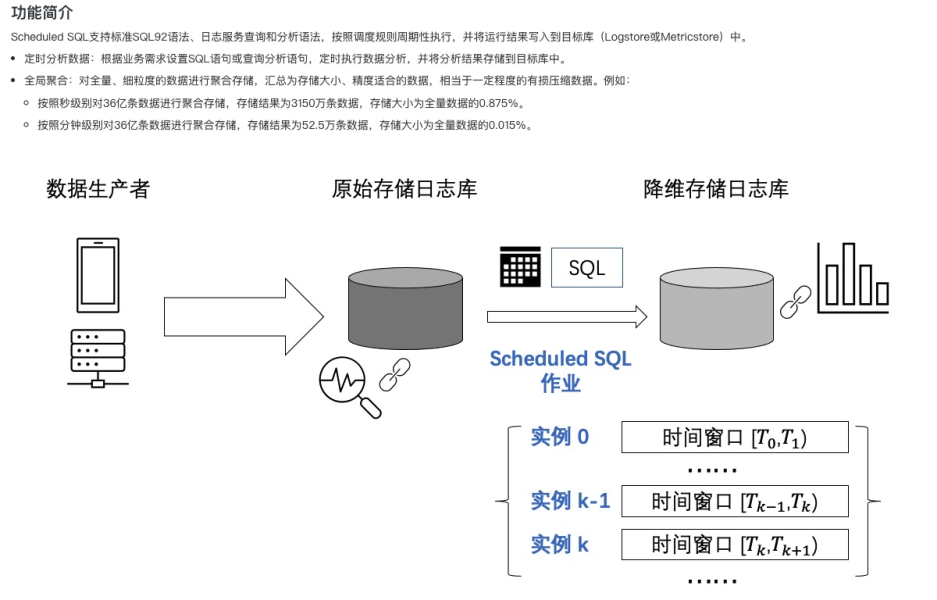
附链接:https://help.aliyun.com/document_detail/215936.html
最终方案
创建多个Scheduled SQL作业,每隔一个小时执行SQL,结果以新的字段名储存到新的日志库中,这边代码只需汇总新的日志库的字段即可。经过测试,接口结果返回不仅仅准确,检索时间没有限制,而且时间是秒级。
完整代码
from fastapi import FastAPI
from aliyun.log import LogClient
# 定义阿里云SDK访问地址、key
endpoint = 'cn-xxxx.log.aliyuncs.com'
accessKeyId = 'xxxxxxxxxxxxxxxx'
accessKey = 'xxxxxxxxxxxxxxx'
client = LogClient(endpoint, accessKeyId, accessKey)
app = FastAPI()
# 统计总流量PV和Flow
def total (begintime,endtime):
pv = client.get_log("kaishucdnlogintime", "cdnscheduled", begintime,endtime,query="*|select sum(total_pv) as pv")
flow = client.get_log("kaishucdnlogintime", "cdnscheduled", begintime,endtime,query="*|select sum(total_flow) as flow")
total_pv = int(pv.body[0]['pv'])
total_flow = int(flow.body[0]['flow'])
return total_pv,total_flow
# 统计image PV和Flow
def image (begintime,endtime):
pv = client.get_log("kaishucdnlogintime", "cdnscheduled", begintime,endtime,query="*|select sum(image_pv) as pv")
flow = client.get_log("kaishucdnlogintime", "cdnscheduled", begintime,endtime,query="*|select sum(image_flow) as flow")
image_pv = int(pv.body[0]['pv'])
image_flow = int(flow.body[0]['flow'])
return image_pv,image_flow
# 统计video PV和Flow
def video (begintime,endtime):
pv = client.get_log("kaishucdnlogintime", "cdnscheduled", begintime,endtime,query="*|select sum(video_pv) as pv")
flow = client.get_log("kaishucdnlogintime", "cdnscheduled", begintime,endtime,query="*|select sum(video_flow) as flow")
video_pv = int(pv.body[0]['pv'])
video_flow = int(flow.body[0]['flow'])
return video_pv,video_flow
# 统计audio PV和Flow
def audio (begintime,endtime):
pv = client.get_log("kaishucdnlogintime", "cdnscheduled", begintime,endtime,query="*|select sum(audio_pv) as pv")
flow = client.get_log("kaishucdnlogintime", "cdnscheduled", begintime,endtime,query="*|select sum(audio_flow) as flow")
audio_pv = int(pv.body[0]['pv'])
audio_flow = int(flow.body[0]['flow'])
return audio_pv,audio_flow
@app.get('/aliyun/beginDate={fromtime}&endDate={totime}')
def calculate(fromtime: str=None, totime: str=None):
# 调整时间格式
fromtime = list(fromtime)
totime = list(totime)
f_time = fromtime[0] + fromtime[1] + fromtime[2] + fromtime[3] + "-" + fromtime[4] + fromtime[5] + "-" + fromtime[6] + fromtime[7] + " 0:0:0"
t_time = totime[0] + totime[1] + totime[2] + totime[3] + "-" + totime[4] + totime[5] + "-" + totime[6] + totime[7] + " 23:59:59"
# 获取 audio、image、video及totalpv数据
total_pv = total(f_time,t_time)[0]
audio_pv = audio(f_time,t_time)[0]
image_pv = image(f_time,t_time)[0]
video_pv = video(f_time,t_time)[0]
other_pv = total_pv - audio_pv - video_pv
# 获取 audio、image、video及tatal流量数据
total_flow = round(total(f_time,t_time)[1]/1024/1024/1024,3)
audio_flow = round(audio(f_time,t_time)[1]/1024/1024/1024,3)
image_flow = round(image(f_time,t_time)[1]/1024/1024/1024,3)
video_flow = round(video(f_time,t_time)[1]/1024/1024/1024,3)
other_flow = total_flow - audio_flow - video_flow - image_flow
# 计算 audio、image、video百分比
audio_flow_ratio = round(audio_flow/total_flow*100,3)
image_flow_ratio = round(image_flow/total_flow*100,3)
video_flow_ratio = round(video_flow/total_flow*100,3)
other_flow_ratio = round(other_flow/total_flow*100,3)
res = {"data":{"total":[{"totalFlow":image_flow,"flowRatio":image_flow_ratio,"pv":image_pv,"type":"image"},{"totalFlow":audio_flow,"flowRatio":audio_flow_ratio,"pv":audio_pv,"type":"audio"},{"totalFlow":video_flow,"flowRatio":video_flow_ratio,"pv":video_pv,"type":"video"},{"totalFlow":other_flow,"flowRatio":other_flow_ratio,"pv":other_pv,"type":"other"}]}}
return res
if __name__ == '__main__':
import uvicorn
uvicorn.run(app=app,
host="0.0.0.0",
port=8080,
workers=1)
















 1394
1394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









