









1、绪论
1.1 图像增强的主流方法
CutMix
CutMix 是一种图像增强技术,它通过从另一幅图像中随机裁剪一个区域并粘贴到当前图像上来创建新的训练样本。同时,标签也会按照两个图像中裁剪区域的比例进行混合。这种方法有助于模型学习如何处理部分遮挡的情况,提高其在未见过的数据上的泛化能力。
MixUp
MixUp 是一种正则化技术,它通过随机选择两个训练样本,并将它们的图像和标签进行线性插值来创建新的训练样本。这种方法鼓励模型在训练样本之间进行线性插值,有助于模型学习平滑的决策边界,并提高其对标签噪声和对抗性样本的鲁棒性。
RandAugment
RandAugment 是一种自动化的图像增强策略,它通过随机选择和应用一系列图像变换(如旋转、缩放、裁剪等)来增强训练数据。这种方法旨在在不引入过多计算开销的情况下,通过随机选择和应用图像变换来最大化模型的性能提升。RandAugment 通常用于自动搜索最优的图像增强策略,帮助模型在未见过的数据上获得更好的性能。
1.2 KerasCV的图像增强技术
KerasCV 使得为图像分类和目标检测任务组装最先进、行业级的数据增强流水线变得轻而易举。KerasCV 提供了一系列预处理层,实现了常见的数据增强技术。
其中,三个最有用的层可能是 keras_cv.layers.CutMix、keras_cv.layers.MixUp 和 keras_cv.layers.RandAugment。这些层几乎被用于所有最先进的图像分类流水线中。
本文将向探讨如何将这些层组合成您自己的图像分类任务的数据增强流水线并引导初学者完成自定义 KerasCV 数据增强流水线的过程。
1.3 KerasCV的图像增强技术的应用场景
KerasCV中的图像增强技术具有广泛的应用范围,主要用于提升深度学习模型(特别是与图像相关的模型)的性能。这些技术通过应用各种变换和增强策略来扩展训练数据集,从而帮助模型学习更多的图像特征和模式。
- 图像分类:在图像分类任务中,图像增强技术用于增加训练样本的多样性和数量,从而帮助模型学习更多的类别特征和区分不同类别的能力。
- 目标检测:对于目标检测任务,图像增强技术可以用于模拟各种复杂场景和光照条件,从而提高模型在不同条件下的检测性能。
- 语义分割:在语义分割任务中,图像增强技术可以应用于增强图像的细节和纹理,从而帮助模型更准确地识别和分割图像中的不同区域。
- 图像生成:图像增强技术也可以用于图像生成任务,例如通过应用不同的变换和增强策略来生成新的图像样本,从而丰富生成模型的训练数据。
- 其他计算机视觉任务:除了上述任务外,KerasCV的图像增强技术还可以应用于其他各种计算机视觉任务中,如图像修复、图像超分辨率重建、视频处理等。
通过应用KerasCV中的图像增强技术,用户可以轻松地创建自定义的数据增强流水线,以满足不同任务和场景的需求。这些技术可以单独使用或组合使用,以最大程度地提高模型的性能和泛化能力。
1.4 使用准备
安装
!pip install -q --upgrade keras-cv
!pip install -q --upgrade keras # Upgrade to Keras 3.
导入方法
import os
os.environ["KERAS_BACKEND"] = "jax" # @param ["tensorflow", "jax", "torch"]
import matplotlib.pyplot as plt
# Import tensorflow for [`tf.data`](https://www.tensorflow.org/api_docs/python/tf/data) and its preprocessing map functions
import tensorflow as tf
import tensorflow_datasets as tfds
import keras
import keras_cv
2、kerasCV使用流程
2.1 数据导入
本文将使用102类花卉数据集(Flower Dataset)作为代码演示的目标数据集。以下是如何加载这个数据集的步骤(这里假设我们使用tensorflow.keras.preprocessing.image_dataset_from_directory来加载数据集,程序员可以指定自己的数据集):
BATCH_SIZE = 32
AUTOTUNE = tf.data.AUTOTUNE
tfds.disable_progress_bar()
data, dataset_info = tfds.load("oxford_flowers102", with_info=True, as_supervised=True)
train_steps_per_epoch = dataset_info.splits["train"].num_examples // BATCH_SIZE
val_steps_per_epoch = dataset_info.splits["test"].num_examples // BATCH_SIZE
接下来,将图像调整为固定大小(224, 224),并对标签进行独热编码。请注意,keras_cv.layers.CutMix 和 keras_cv.layers.MixUp 需要将目标标签进行独热编码。这是因为它们以稀疏标签表示无法实现的方式修改目标值。
MAGE_SIZE = (224, 224)
num_classes = dataset_info.features["label"].num_classes
def to_dict(image, label):
image = tf.image.resize(image, IMAGE_SIZE)
image = tf.cast(image, tf.float32)
label = tf.one_hot(label, num_classes)
return {"images": image, "labels": label}
def prepare_dataset(dataset, split):
if split == "train":
return (
dataset.shuffle(10 * BATCH_SIZE)
.map(to_dict, num_parallel_calls=AUTOTUNE)
.batch(BATCH_SIZE)
)
if split == "test":
return dataset.map(to_dict, num_parallel_calls=AUTOTUNE).batch(BATCH_SIZE)
def load_dataset(split="train"):
dataset = data[split]
return prepare_dataset(dataset, split)
train_dataset = load_dataset()
检测数据样本
def visualize_dataset(dataset, title):
plt.figure(figsize=(6, 6)).suptitle(title, fontsize=18)
for i, samples in enumerate(iter(dataset.take(9))):
images = samples["images"]
plt.subplot(3, 3, i + 1)
plt.imshow(images[0].numpy().astype("uint8"))
plt.axis("off")
plt.show()
visualize_dataset(train_dataset, title="Before Augmentation")

2.2 RandAugment 数据增强
RandAugment 已经被证明能在多个数据集上提供改进的图像分类结果。它对图像执行一系列标准的增强操作。
要在 KerasCV 中使用 RandAugment,程序员需要提供几个值:
value_range描述了你图像中值的范围magnitude是一个在 0 到 1 之间的值,描述了应用的扰动的强度augmentations_per_image是一个整数,告诉层对每个单独的图像应用多少次增强- (可选)
magnitude_stddev允许从标准差为magnitude_stddev的分布中随机采样
magnitude - (可选)
rate表示在每个层应用增强的概率。
程序员可以在 RandAugment 的 API 文档中阅读更多关于这些参数的信息。
rand_augment = keras_cv.layers.RandAugment(
value_range=(0, 255),
augmentations_per_image=3,
magnitude=0.3,
magnitude_stddev=0.2,
rate=1.0,
)
def apply_rand_augment(inputs):
inputs["images"] = rand_augment(inputs["images"])
return inputs
train_dataset = load_dataset().map(apply_rand_augment, num_parallel_calls=AUTOTUNE)
visualize_dataset(train_dataset, title="After RandAugment")

2.3CutMix and MixUp 图像增强技术
CutMix 和 MixUp 允许我们生成类间样本。CutMix 随机切出一幅图像的部分并放置到另一幅图像上,而 MixUp 则在两幅图像的像素值之间进行插值。这两种技术都可以防止模型过拟合训练数据分布,并提高模型泛化到分布外样本的可能性。此外,CutMix 可以防止模型过度依赖任何特定特征来进行分类。程序员可以在他们各自的论文中阅读更多关于这些技术的信息:
- CutMix: 训练强大的分类器
- MixUp: 超越经验风险最小化
在这个例子中,我们将在手动创建的预处理流程中独立使用 CutMix 和 MixUp。在大多数最先进的流程中,图像会随机地通过 CutMix、MixUp 或者两者都不用进行增强。下面的函数实现了这两种方法。
cut_mix = keras_cv.layers.CutMix()
mix_up = keras_cv.layers.MixUp()
def cut_mix_and_mix_up(samples):
samples = cut_mix(samples, training=True)
samples = mix_up(samples, training=True)
return samples
train_dataset = load_dataset().map(cut_mix_and_mix_up, num_parallel_calls=AUTOTUNE)
visualize_dataset(train_dataset, title="After CutMix and MixUp")

3、自定义图像增强流程
程序员可能想从 RandAugment 中排除某种增强,或者想在默认的 RandAugment 增强之外添加 keras_cv.layers.GridMask 作为一种选项。
KerasCV 允许程序员使用 keras_cv.layers.RandomAugmentationPipeline 层来构建生产级的自定义数据增强流程。这个类与 RandAugment 的操作类似,它会为每个图像选择随机层进行 augmentations_per_image 次数的增强。RandAugment 可以看作是 RandomAugmentationPipeline 的一个特例。事实上,我们的 RandAugment 实现内部就是继承自 RandomAugmentationPipeline。
在下文的例子中,我们将通过从标准的 RandAugment 策略中移除 RandomRotation 层,并替换为 GridMask 层来创建一个自定义的 RandomAugmentationPipeline。
作为第一步,让我们使用辅助方法 RandAugment.get_standard_policy() 来创建一个基础流程。
layers = keras_cv.layers.RandAugment.get_standard_policy(
value_range=(0, 255), magnitude=0.75, magnitude_stddev=0.3
)
过滤掉 RandomRotation 层
layers = [
layer for layer in layers if not isinstance(layer, keras_cv.layers.RandomRotation)
]
将 keras_cv.layers.GridMask 添加到我们的层中
layers = layers + [keras_cv.layers.GridMask()]
将增强流程组合在一起
pipeline = keras_cv.layers.RandomAugmentationPipeline(
layers=layers, augmentations_per_image=3
)
def apply_pipeline(inputs):
inputs["images"] = pipeline(inputs["images"])
return inputs
使用建立的增强流程
train_dataset = load_dataset().map(apply_pipeline, num_parallel_calls=AUTOTUNE)
visualize_dataset(train_dataset, title="After custom pipeline")
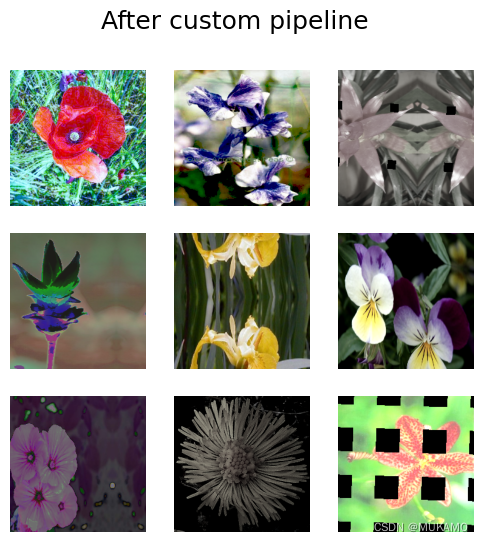
自定义旋转流程
pipeline = keras_cv.layers.RandomAugmentationPipeline(
layers=[keras_cv.layers.GridMask(), keras_cv.layers.Grayscale(output_channels=3)],
augmentations_per_image=1,
)
使用上面定义的旋转流程
train_dataset = load_dataset().map(apply_pipeline, num_parallel_calls=AUTOTUNE)
visualize_dataset(train_dataset, title="After custom pipeline")

4、训练示例
作为综合实践,让我们使用这些层来进行一些实际操作。在本节中,我们将使用CutMix、MixUp和RandAugment在牛津花卉数据集上训练一个先进的ResNet50图像分类器。
def preprocess_for_model(inputs):
images, labels = inputs["images"], inputs["labels"]
images = tf.cast(images, tf.float32)
return images, labels
train_dataset = (
load_dataset()
.map(apply_rand_augment, num_parallel_calls=AUTOTUNE)
.map(cut_mix_and_mix_up, num_parallel_calls=AUTOTUNE)
)
visualize_dataset(train_dataset, "CutMix, MixUp and RandAugment")
train_dataset = train_dataset.map(preprocess_for_model, num_parallel_calls=AUTOTUNE)
test_dataset = load_dataset(split="test")
test_dataset = test_dataset.map(preprocess_for_model, num_parallel_calls=AUTOTUNE)
train_dataset = train_dataset.prefetch(AUTOTUNE)
test_dataset = test_dataset.prefetch(AUTOTUNE)

接下来,我们应该创建模型本身。请注意,我们在损失函数中使用label_smoothing=0.1。当使用MixUp时,强烈建议使用标签平滑。
input_shape = IMAGE_SIZE + (3,)
def get_model():
model = keras_cv.models.ImageClassifier.from_preset(
"efficientnetv2_s", num_classes=num_classes
)
model.compile(
loss=keras.losses.CategoricalCrossentropy(label_smoothing=0.1),
optimizer=keras.optimizers.SGD(momentum=0.9),
metrics=["accuracy"],
)
return model
训练模型
model = get_model()
model.fit(
train_dataset,
epochs=1,
validation_data=test_dataset,
)
5、总结
文章的讨论涵盖了如何使用先进的图像增强技术来训练和优化卷积神经网络(CNN)模型,特别是在图像分类任务中。以下是对今天讨论内容的全面总结:
5.1图像增强技术
- CutMix:一种数据增强方法,通过切割一幅图像的区域并用另一幅图像的相应区域替换,同时混合两个图像的标签。这种方法可以帮助模型学习不同物体之间的特征关系。
- MixUp:一种简单的数据增强策略,通过随机混合两个训练样本及其标签来创建新的训练样本。这种方法能够增加模型的泛化能力。
- RandAugment:一个自动的数据增强策略,通过应用一系列随机但合理的转换来增加模型的鲁棒性。
5.2. 模型选择:ResNet50
- 选择ResNet50作为基础模型,这是一个在图像分类任务中广泛使用的深度卷积神经网络结构,具有优秀的性能和广泛的适用性。
5.3. 标签平滑
- 在使用MixUp等增强技术时,建议使用标签平滑。标签平滑通过将硬标签替换为软标签来防止模型过度自信,从而提高模型的泛化能力。
5.4. 模型训练与优化
- 将图像增强技术与ResNet50模型结合,在特定数据集(如牛津花卉数据集)上进行训练。通过调整学习率、批量大小、训练轮次等超参数以及增强技术的参数来优化模型的性能。
5.5. 自定义增强流程
- 讨论了如何根据特定任务或数据集的需求,通过组合不同的增强层来创建自定义的增强流程。这允许我们更精确地控制数据增强的方式和程度。
5.6. 评估与迭代
- 强调了在训练过程中使用验证集来评估模型性能的重要性。通过不断迭代和优化模型结构、参数以及增强策略,我们可以逐步提高模型的性能。
5.7. 实际应用
- 讨论了这些技术和策略在现实世界应用中的潜在用途,包括但不限于图像分类、目标检测、图像分割等计算机视觉任务。
通过结合先进的图像增强技术和深度卷积神经网络模型,我们可以训练出性能优越的图像分类器,并在各种实际应用中取得良好的表现。今天的讨论为我们提供了宝贵的见解和实践经验,有助于我们在未来的工作中更好地应用这些技术和策略。
















 6125
6125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











