






题前吐槽:被老师要求第一次写博客,如果有一些不足请大家指正,共同学习,共同进步。
题前大致介绍:
本篇博客内容简单介绍关于卷积神经网络中的感知机介绍,多层感知器在结构上扩展了我们在前半实验研究的简单感知器,将多个感知器分组在一个单层,并将多个层叠加在一起。
具体的内容:
我将在接下来的实验中通过“示例:带有多层感知器的姓氏分类”,掌握多层感知器在多层分类中的应用,希望大家可以通过本篇文章大致了解并且,掌握每种类型的神经网络层对它所计算的数据张量的大小和形状的影响。如何完成如图所示的分类问题?

本人使用的环境为python3.11
- 感知机和多层感知机
1.1 感知器
首先要搞清楚,最简单的神经网络单元是感知器。感知器在历史上是非常松散地模仿生物神经元的。就像生物神经元一样,有输入和输出,“信号”从输入流向输出。
每个感知器单元有一个输入(x),一个输出(y),和三个“旋钮”(knobs):一组权重(w),偏量(b),和一个激活函数(f)。权重和偏量都从数据学习,激活函数是精心挑选的取决于网络的网络设计师的直觉和目标输出。数学上,我们可以这样表示:
𝑦=𝑓(𝑤𝑥+𝑏)
激活函数,这里用f表示,通常是一个非线性函数。使用PyTorch 中的感知器实现,它接受任意数量的输入、执行仿射转换、应用激活函数并生成单个输出。
但是实际上感知机使用可以表示与门、与非门、或门的逻辑电路,这些基本逻辑电路可以进一步构成较为复杂的简单感知机在此,只进行简单的科普,不进行过多地解释和阐述
1.2 激活函数
激活函数是神经网络中引入的非线性函数,用于捕获数据中的复杂关系。在“深入到有监督的训练”和“多层感知器”中,我们深入研究了为什么学习中需要非线性,但首先,让我们看看一些常用的激活函数。
1.2.1 sigmoid
sigmoid 是神经网络历史上最早使用的激活函数之一。它取任何实值并将其压缩在0和1之间。数学上,sigmoid 的表达式如下:
𝑓(𝑥)=1/(1+𝑒)−𝑥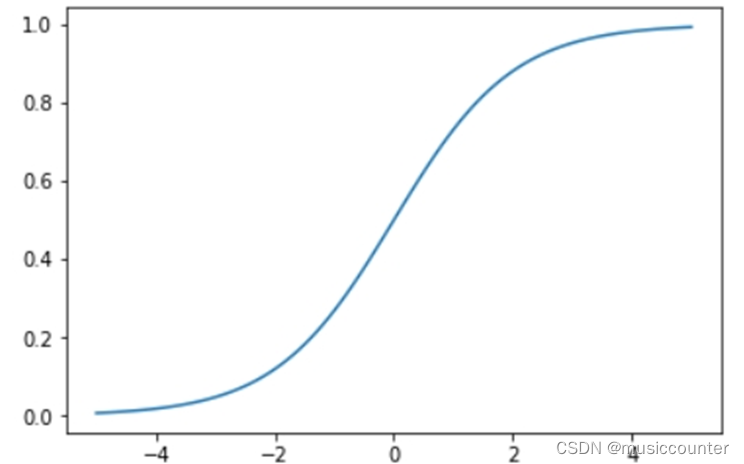
1.2.2 tanh
tanh是如Example 3-3所示,tanh 激活函数是 sigmoid 在外观上的不同变体。当你写下 tanh 的表达式时,这就变得很清楚了:
𝑓(𝑥)=𝑡𝑎𝑛ℎ𝑥=(𝑒𝑥−𝑒)−𝑥/(𝑒𝑥+𝑒)−𝑥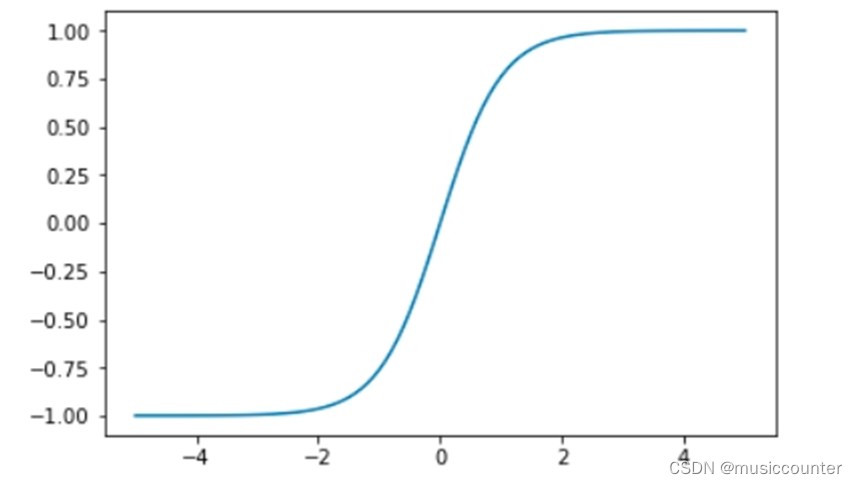
1.2.3 ReLU
ReLU(发音为 ray-luh)代表线性整流单元。这可以说是最重要的激活函数。事实上,我们可以大胆地说,如果没有使用 ReLU,许多最近在深度学习方面的创新都是不可能实现的。对于一些如此基础的东西来说,神经网络激活函数的出现也是令人惊讶的。它的形式也出奇的简单:
𝑓(𝑥)=𝑚𝑎𝑥(0,𝑥)
因此,ReLU 单元所做的就是将负值裁剪为零。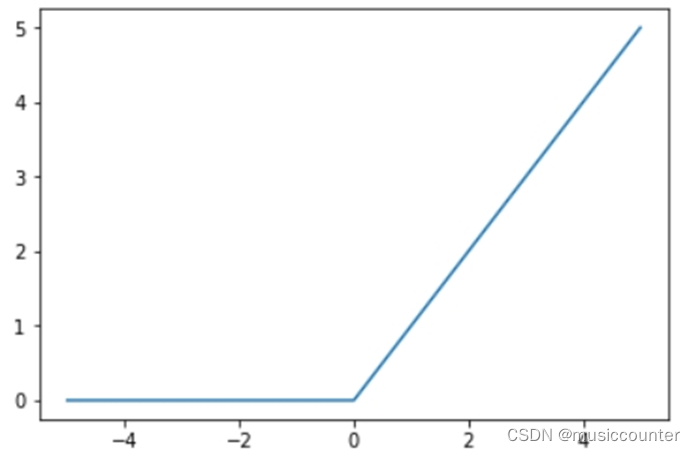
1.2.4 softmax
激活函数的另一个选择是 softmax 。与 sigmoid 函数类似,softmax 函数将每个单元的输出压缩为 0 到 1 之间。然而,softmax 操作还将每个输出除以所有输出的和,从而得到一个离散概率分布,除以 k 个可能的类。结果分布中的概率总和为 1。
1.3 多层感知机
现在就到我们的重头戏,多层感知器(MLP)被认为是最基本的神经网络构建模块之一。最简单的MLP是对感知器的扩展。感知器将数据向量作为输入,计算出一个输出值。在MLP中,许多感知器被分组,以便单个层的输出是一个新的向量,而不是单个输出值。在PyTorch中,正如您稍后将看到的,这只需设置线性层中的输出特性的数量即可完成。MLP的另一个方面是,它将多个层与每个层之间的非线性结合在一起。
对MLP简单地展示一下图例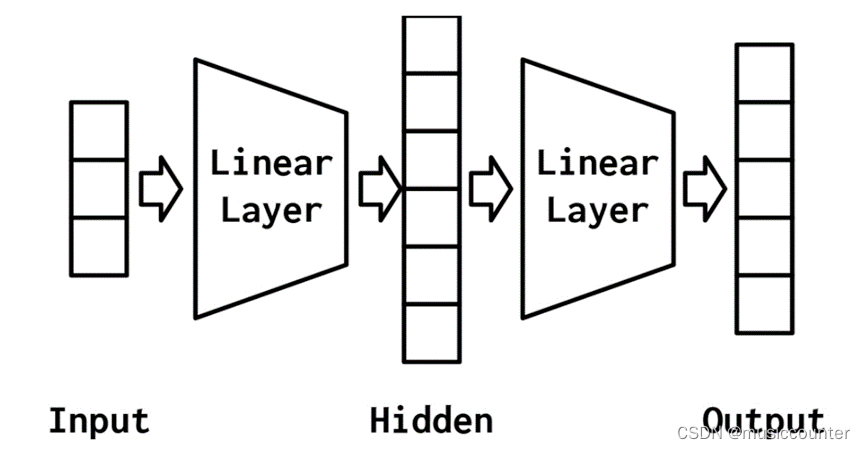
1.3.1 A Simple Example: XOR
让我们看一下前面描述的XOR示例,看看感知器与MLP之间会发生什么。在这个例子中,我们在一个二元分类任务中训练感知器和MLP:星和圆。每个数据点是一个二维坐标。在不深入研究实现细节的情况下,在左边的面板中,从填充的形状可以看出,感知器在学习一个可以将星星和圆分开的决策边界方面有困难。然而,MLP(右面板)学习了一个更精确地对恒星和圆进行分类的决策边界。
这些线是每个模型的决策边界。在边的面板中,感知器学习—个不能正确地将圆与星分开的决策边界。事实上,没有一条线可以。在右动的面板中,MLP学会了从圆中分离星。
虽然在图中显示MLP有两个决策边界,这是它的优点,但它实际上只是一个决策边界!决策边界就是这样出现的,因为中间表示法改变了空间,使一个超平面同时出现在这两个位置上,我们可以看到MLP计算的中间值。这些点的形状表示类(星形或圆形)。我们所看到的是,神经网络(本例中为MLP)已经学会了“扭曲”数据所处的空间,以便在数据通过最后一层时,用一线来分割它们。
MLP的输入和中间表示是可视化的。从左到右:(1)网络的输入;(2)第一个线性模块的输出;(3)第一个非线性模块的输出;(4)第二个线性模块的输出。第一个线性模块的输出将圆和星分组,而第二个线性模块的输出将数据点重新组织为线性可分的。
1.3.2 Implementing MLPs in PyTorch
我们将介绍PyTorch中的一个实现。如前所述,MLP除了中简单的感知器之外,还有一个额外的计算层。
import torch.nn as nn
import torch.nn.functional as F
class MultilayerPerceptron(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
"""
Args:
input_dim (int): the size of the input vectors
hidden_dim (int): the output size of the first Linear layer
output_dim (int): the output size of the second Linear layer
"""
super(MultilayerPerceptron, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)#第一个全连接层
self.fc2 = nn.Linear(hidden_dim, output_dim)#第二个全连接层
def forward(self, x_in, apply_softmax=False):
"""The forward pass of the MLP
Args:
x_in (torch.Tensor): an input data tensor.
x_in.shape should be (batch, input_dim)
apply_softmax (bool): a flag for the softmax activation
should be false if used with the Cross Entropy losses
Returns:
the resulting tensor. tensor.shape should be (batch, output_dim)
"""
intermediate = F.relu(self.fc1(x_in))#对第一层应用ReLu激活函数
output = self.fc2(intermediate)#输出网络
if apply_softmax:
output = F.softmax(output, dim=1)#softmax激活函数
return output#返回输出张量
在上述内容中我们实例化了MLP。由于MLP实现的通用性,可以为任何大小的输入建模。为了演示,我们使用大小为3的输入维度、大小为4的输出维度和大小为100的隐藏维度。请注意,在print语句的输出中,每个层中的单元数很好地排列在一起,以便为维度3的输入生成维度4的输出。
batch_size = 2 # number of samples input at once
input_dim = 3
hidden_dim = 100
output_dim = 4
# 设置相应的参数
# Initialize model
mlp = MultilayerPerceptron(input_dim, hidden_dim, output_dim)
print(mlp)
运行结果:
import torch
def describe(x):
print("Type: {}".format(x.type()))
print("Shape/size: {}".format(x.shape))
print("Values: \n{}".format(x)) # 打印相应的数据
x_input = torch.rand(batch_size, input_dim)
describe(x_input)
y_output = mlp(x_input, apply_softmax=False)
describe(y_output)
运行结果

- 对于具体的层感知器在多层分类中的应用
2.1分类问题的代码实现(部分)
losses = []
batch_size = 10000
n_batches = 10
max_epochs = 10
loss_change = 1.0
last_loss = 10.0
change_threshold = 1e-3
epoch = 0
all_imagefiles = []
lr = 0.01
首先我们能对于所涉及到训练的参数进行初始化
def early_termination(loss_change, change_threshold, epoch, max_epochs):
terminate_for_loss_change = loss_change < change_threshold
terminate_for_epochs = epoch > max_epochs
# return terminate_for_loss_change or
return terminate_for_epochs
然后我们定义了一个用于训练中提前终止的函数,可能是用于机器学习模型。你的函数似乎检查损失变化是否低于某个阈值,或者是否达到了最大的训练轮数。
继而就是重头戏了,我们将对模型训练进行一系列的操作,部分代码未给出但是大致步骤如下图所展示:
optimizer = optim.Adam(params=mlp1.parameters(), lr=lr)
cross_ent_loss = nn.CrossEntropyLoss()
while not early_termination(loss_change, change_threshold, epoch, max_epochs):
for _ in range(n_batches):
# step 0: fetch the data
x_data, y_target = get_toy_data(batch_size)
# step 1: zero the gradients
mlp1.zero_grad()
# step 2: run the forward pass
y_pred = mlp1(x_data).squeeze()
# step 3: compute the loss
loss = cross_ent_loss(y_pred, y_target.long())
# step 4: compute the backward pass
loss.backward()
# step 5: have the optimizer take an optimization step
optimizer.step()
# auxillary: bookkeeping
loss_value = loss.item()
losses.append(loss_value)
loss_change = abs(last_loss - loss_value)
last_loss = loss_value
2.2关键代码的解释和知识的拓展部分
all_imagefiles = []: 一个空列表,用于存储每个 epoch 生成的图像文件路径。
optimizer = optim.Adam(params=mlp1.parameters(), lr=lr): 使用 Adam 优化器来优化多层感知机的参数。
Adam简介
Adam 在深度学习领域内是十分流行的算法,因为它能很快地实现优良的结果。经验性结果证明 Adam 算法在实践中性能优异,相对于其他种类的随机优化算法具有很大的优势。下图是不同模型与其训练的比较。(来自(十) 深度学习笔记 | 关于优化器Adam-CSDN博客)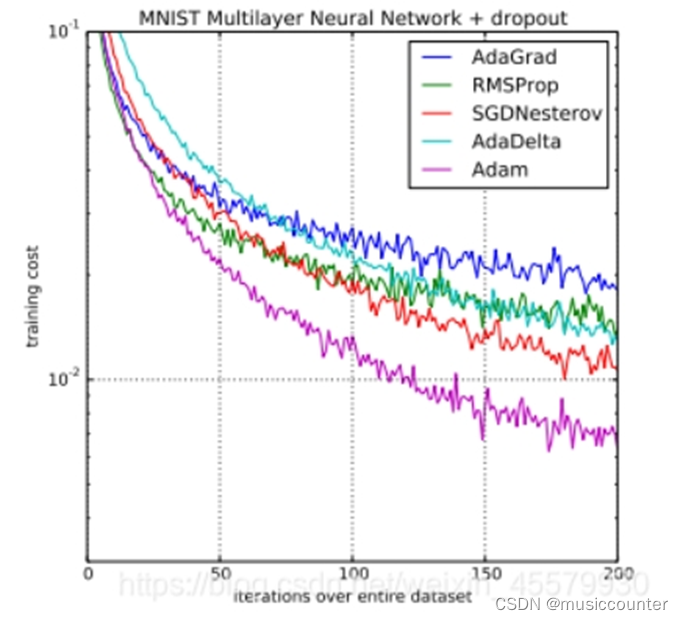
因此使用其可以显著改善模型的准确性。
cross_ent_loss = nn.CrossEntropyLoss(): 定义交叉熵损失函数,用于计算分类问题的损失。
early_termination 函数:根据损失变化和达到最大 epoch 来确定是否提前终止训练。
对于交叉熵函数我们有如下定义:
交叉熵是信息熵论中的概念,它原本是用来估算平均编码长度的。在深度学习中,可以看作通过概率分布q ( x ) q(x)q(x)表示概率分布p ( x ) p(x)p(x)的困难程度。其表达式为: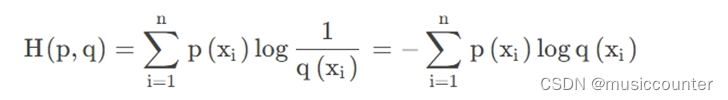
如以下三分类问题经过softmax后的答案:
(来自:交叉熵损失函数(cross-entropy loss function)原理及Pytorch代码简介_损失函数 dkl-CSDN博客)
mlp1.zero_grad(): 将模型的梯度置零。
y_pred = mlp1(x_data).squeeze(): 进行前向传播,得到模型的预测值。
loss = cross_ent_loss(y_pred, y_target.long()): 计算预测值和真实标签之间的交叉熵损失。
loss.backward(): 反向传播,计算梯度,根据梯度更新模型参数。
那么什么是反向和正向传播?
对于深度学习中的正向传播我们可以了解按顺序(从输入层到输出层)计算和存储神经网络中每层的结果。如下图: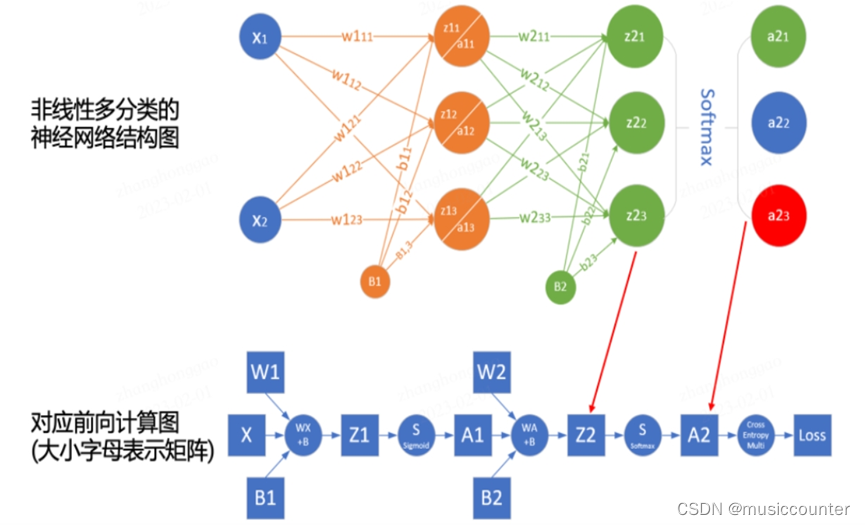
相对应的反向传播(backward propagation,简称 BP)指的是计算神经网络参数梯度的方法。其原理是基于微积分中的链式规则,按相反的顺序从输出层到输入层遍历网络,依次计算每个中间变量和参数的梯度。两者区别在于正向传播是将输入数据通过神经网络向前传播以获得预测结果,而反向传播是根据预测结果和实际标签之间的差异来更新神经网络中的参数,使得网络能够更好地拟合数据。
最后我们将所得到的分类结果打印出来代码如下:
fig, ax = plt.subplots(1, 1, figsize=(10, 5))
visualize_results(mlp1, x_data_static, y_truth_static, ax=ax, epoch=epoch,
title=f"{loss_value:0.2f}; {loss_change:0.4f}")
plt.axis('off')
epoch += 1
all_imagefiles.append(f'/home/jovyan/perceptron_epoch{epoch}_toylearning.png')
plt.savefig(all_imagefiles[-1])
好的,至此我们所有模型训练完毕
2.3相关结果展示
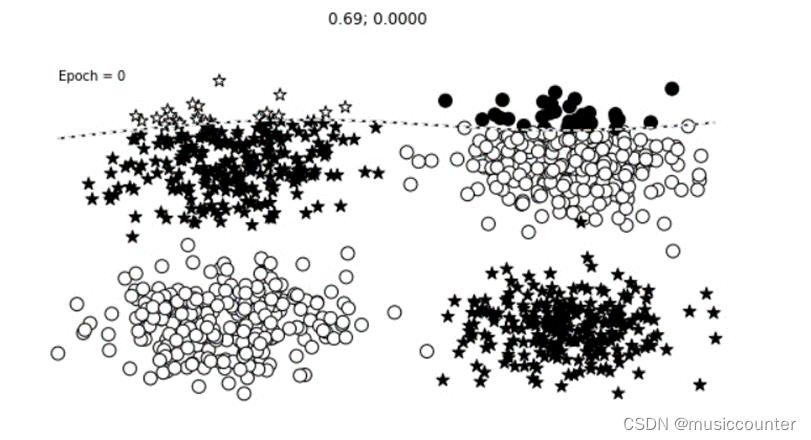
下面就是我们随着迭代次数的增加而得到的分类情况,其中分类效果情况明显随着Epoch的增加逐级递增,需要注意的是我们可以尽量将感知机增加多层的情况这样效果更佳。
如下图:
单层情况:
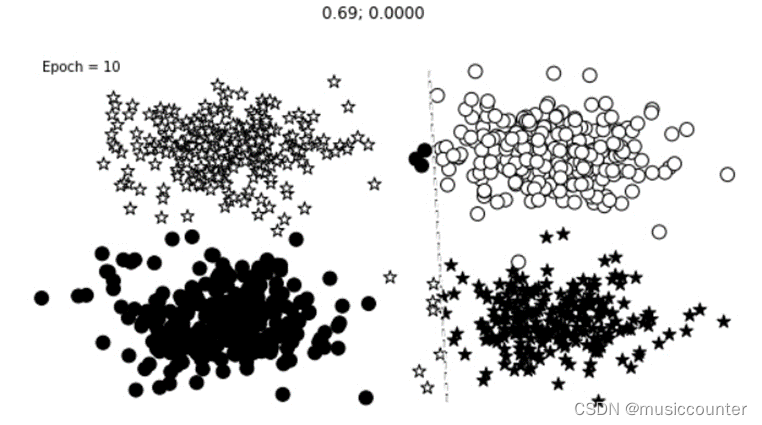
那么同理对于三层感知机:
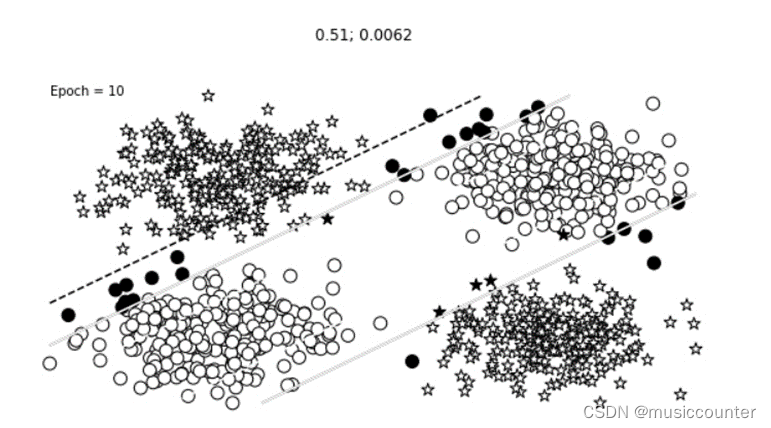
2.4相关实验总结
由此可以看出多层感知机(MLP)相对于单层感知机在处理复杂问题时具有一些优势,这些优势主要来自于其具有更多的层次和参数,下面让我们最后一起总结一下吧:
非线性映射能力,强适应性以及一些特有的技术:MLP在实际应用中还可以结合其他技术来进一步提升性能,例如使用Dropout来防止过拟合、使用批标准化来加速训练收敛、使用残差连接来构建更深的网络等等。MLP相对于单层感知机具有更强的表示能力和灵活性,能够处理更加复杂的问题,并且是深度学习领域的基础模型之一。
此文章为个人编写,引用时请注明链接来源以及作者
感谢 您的 阅读、点赞、收藏 和 评论 ,别忘了 还可以 关注 一下哈,感谢 您的支持















 674
674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









