






大家好,我是玄姐。
▼最近直播超级干,预约保你有收获
一个企业级的 AI 应用推理架构中往往面临以下5个关键问题:限流、负载均衡、异步化、数据管理、索引增强,本文对这5个关键问题进行深度剖析并给出优雅的解决方案。
—1—
AI 应用推理架构中的关键问题剖析
落地一个企业级 AI 应用产品是一项复杂的任务,它涉及到多个层面的产品化挑战。为了确保产品的稳定性、效率和高质量的输出结果,必须在大模型推理引擎的外围进行大量的工程优化工作。以下是构建此类 AI 应用服务时可能遇到的一些关键问题:

第一、接入层调度问题
用户请求的速率可能远高于大模型推理服务的处理速率,导致请求积压和服务器过载。
推理服务器间的负载可能不均衡,一些服务器过载而另一些则资源闲置,影响整体性能。
推理请求的处理时间可能较长且不确定,使得接入层服务难以设置合适的超时时间,增加了连接异常断开的风险。
传统的一问一答模式限制了人机交互的流畅性,无法支持复杂的双向交互。
第二、用户数据管理问题
需要有效管理用户信息,以便根据用户的具体需求定制化服务。
在多轮对话场景中,需要存储和管理历史对话信息,以维持对话的连贯性。
第三、结果的准确性问题
由于大模型的训练数据有限,可能无法覆盖所有行业数据和企业私域数据,影响结果的准确性。
—2—
AI 应用推理架构中5大关键问题解决方案
上面提到的 AI 应用推理架构中的问题可以概括为5大关键问题,分别为:限流、负载均衡、异步化、数据管理、索引增强,下面我们针对每个关键问题来逐一给出解决方案。
第一、限流关键问题的解决方案
为确保 AI 应用推理服务在面临前端请求速率与后端处理速率不匹配时的稳定性,防止服务过载,并维持服务的吞吐量和服务质量水平,实施请求限流是一种有效策略。在传统微服务服务架构中,可以利用 Redis 的 Incr 命令结合过期时间机制来实现固定窗口限流功能。
以下是实现该限流逻辑的伪代码示例:
ret = jedis.incr(KEY);if (ret == 1) { // 设置过期时间 jedis.expire(KEY, EXPIRE_TIME);}if (ret <= LIMIT_COUNT) { return true; } else { return false; }这是一种基础的限流方法,它能够在一个固定的 EXPIRE_TIME 时间内限制用户的请求数量不超过 LIMIT_COUNT。
然而,这种方法存在一些不足之处:限流效果不够平滑,用户可能在限流周期开始的第一秒就耗尽了所有的请求额度,导致在剩余时间内无法进行任何请求。此外,这种方法还要求用户不断尝试重新发送请求,这可以想象,在一个人机交互的场景中,如果机器人服务一直提示用户“系统繁忙,请稍后再试”,而用户需要不断重试,这种体验是非常糟糕的。
为了改善这个问题,我们可以采用令牌桶算法的限流逻辑,它能够解决限流不平滑和减少用户重试的需求。
以下是采用令牌桶算法的限流逻辑的伪代码示例:
// 请求端阻塞方式获取令牌jedis.blpop(TIMEOUT, KEY);
// 令牌生成端,定期向队列中投放令牌if (jedis.llen(KEY) < MAX_COUNT) { jedis.rpush(KEY, value, ...);}在限流策略中,引入等待机制可以在一定时间内避免用户端的重复请求尝试。如果用户在指定的 TIMEOUT 时间内未能成功获取令牌,则请求将被判定为失败。这种方法有效减少了用户端的重试频率。通过设置较短的令牌发放间隔,可以实现更加平滑的流量控制。
然而,这种限流方法并没有细致区分不同请求对推理服务器资源的不同影响。由于不同的推理请求可能会对推理服务器资源造成不同程度的消耗,因此,依据生成的 Token 数量来评估资源消耗可能更为合理。此外,业务可能需要根据特定情况实施自定义的限流逻辑。
为了满足复杂的限流需求,仅依靠 Redis 的基本接口可能不够灵活。因此,引入一个独立的限流服务变得必要。该服务通过 Redis 与接入服务和限流服务解耦,利用 Redis 实现消息通知和结果推送。
简化后的 AI 应用推理服务框架如下图所示:用户的请求首先到达无状态的接入服务。接入服务利用 Redis 将限流相关的请求转发至限流服务。限流服务根据用户标识信息(uid)、推理服务器的负载情况、令牌状态等,结合业务逻辑和策略,决定请求是直接失败还是进入排队队列。请求在排队成功或超时后,限流服务将结果通知接入服务,接入服务根据限流结果决定是否将请求转发至推理服务。
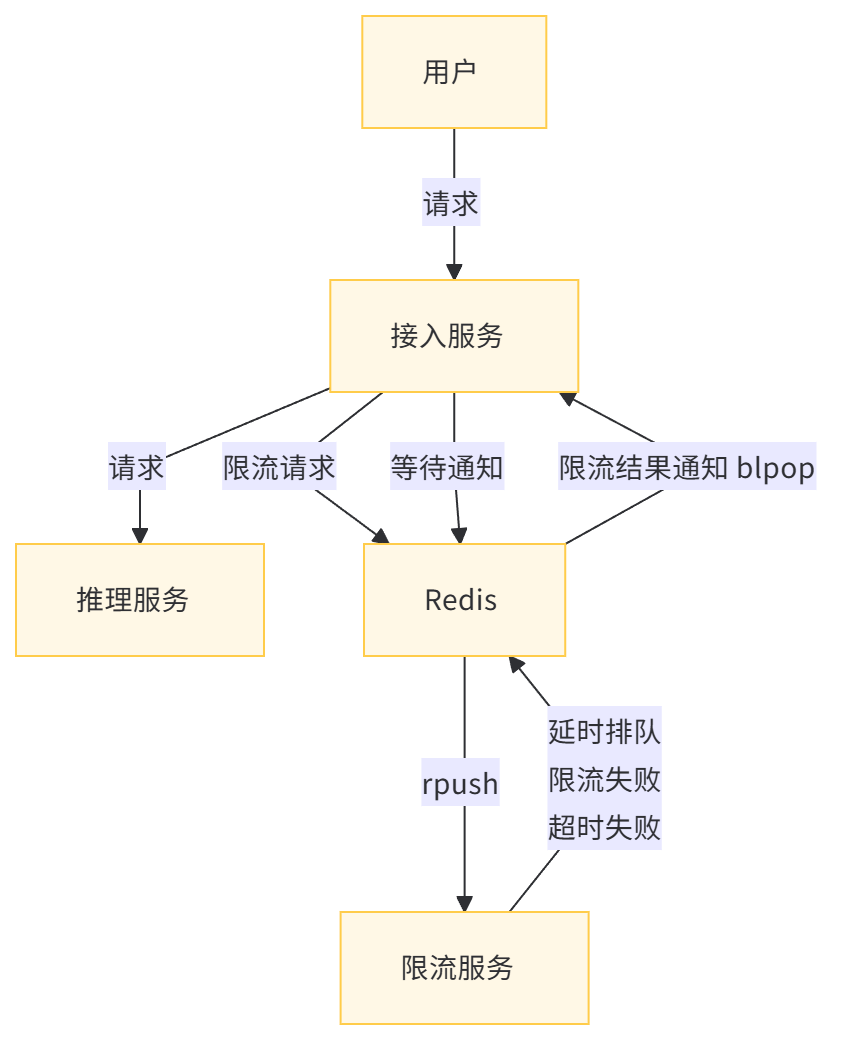
通过这种设计,独立的限流服务能够根据产品的具体需求定制限流策略,实现复杂的限流逻辑。同时,Redis 作为消息队列,不仅解耦了接入服务和限流服务,还完成了限流结果的实时推送,提高了系统的灵活性和响应速度。
这种架构设计使得系统能够更加精细和灵活地控制流量,同时保证了服务的稳定性和高效性,为实现高级的业务需求提供了支持。
第二、负载均衡关键问题的解决方案
为了应对不断增长的业务需求,后端通常会部署多台服务器来处理请求,这就需要一种策略来将用户的请求路由到合适的推理服务器上。常见的做法是使用 LVS、Nginx 等提供的第4层(L4)和第7层(L7)负载均衡服务来分配请求。
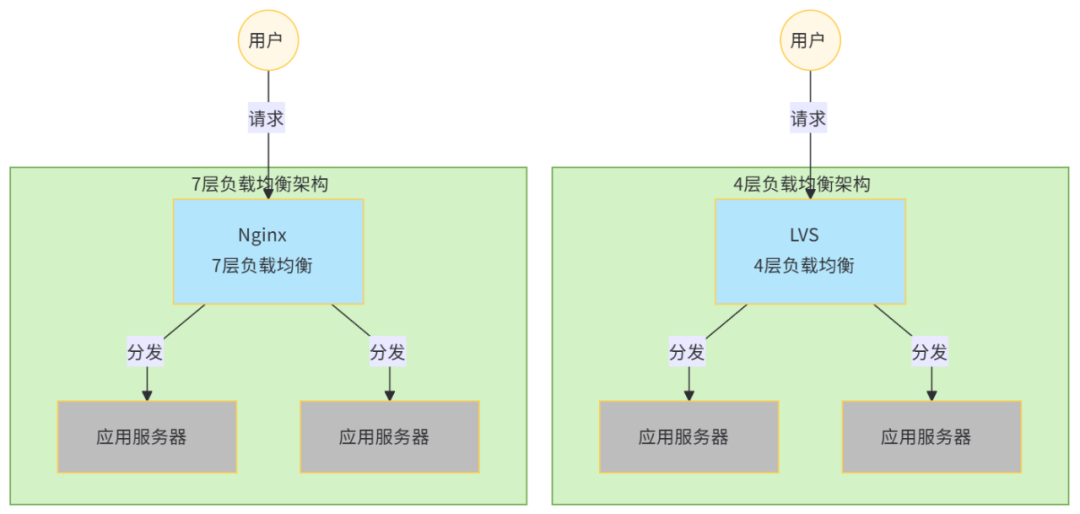
负载均衡器通常采用轮询调度(Round Robin)或加权轮询的方式来分发请求。这些调度算法没有考虑到请求之间的差异,也没有动态地考虑服务器负载的差异。在传统的应用场景中,由于每个用户请求对服务器的资源消耗相差不大,且请求执行速度快、资源消耗少,因此在请求数量足够多的情况下,各个服务器的负载会趋于均衡。
然而,在 AI 应用推理场景下,不同请求对推理服务器的资源消耗可能有很大差异,请求执行时间较长,资源消耗较高。如果采用轮询调度的方式,可能会导致部分推理服务器过载,而另一部分服务器的资源却闲置,这不仅无法最大化整体吞吐量,也无法保证服务水平目标(SLO)。
虽然传统的负载均衡服务提供了基于应用服务器的连接数、负载等指标的动态调度算法,但在推理场景下,这些算法的效果并不理想。应用服务器的连接数并不能准确代表其负载,而且负载指标通常是由负载均衡服务定期刷新的,无法实时更新。此外,多个负载均衡服务器之间的状态同步也需要时间,如果多个负载均衡服务器同时将请求调度到一个负载较低的推理服务器上,可能会导致该服务器过载。
总的来说,由于单个推理请求的资源消耗较大,个体差异较大,少量的调度失衡就可能导致负载差异很大,因此传统的负载均衡服务无法满足推理请求的调度需求。
目前,针对推理请求的调度主要有两类方案:
基于代价估算的方案:由一个调度器评估每条推理请求的代价,通过一个小模型快速估算请求推理结果所需的 Token 数量,然后在全局维度上根据估算的代价来分发请求。这种方案的优点是在分发请求时能够考虑 KVCache 的亲和性,比如:将多轮对话分发到同一台推理服务器上,复用之前的 KVCache,减少重复计算。但缺点是调度逻辑较为复杂,调度器需要考虑服务器负载、请求估算代价、KVCache 亲和性等多个指标,而且全局的调度器可能存在性能瓶颈,也需要考虑高可用性问题。当估算模型出现偏差时,还可能导致负载不均。
基于拉取的模型:接入服务并不直接将请求转发给推理服务,而是将请求放入 Redis 的 stream 结构中,当推理服务空闲时,主动从 Redis 拉取请求。这保证了所有推理服务都能在最佳负载下运行。这种方案的优点是实现起来比较简单,能够保证推理服务器在最佳负载下运行,同时实现服务器间的负载均衡,提高整体吞吐量。缺点是很难保持 KVCache 的亲和性,后续优化手段有限。
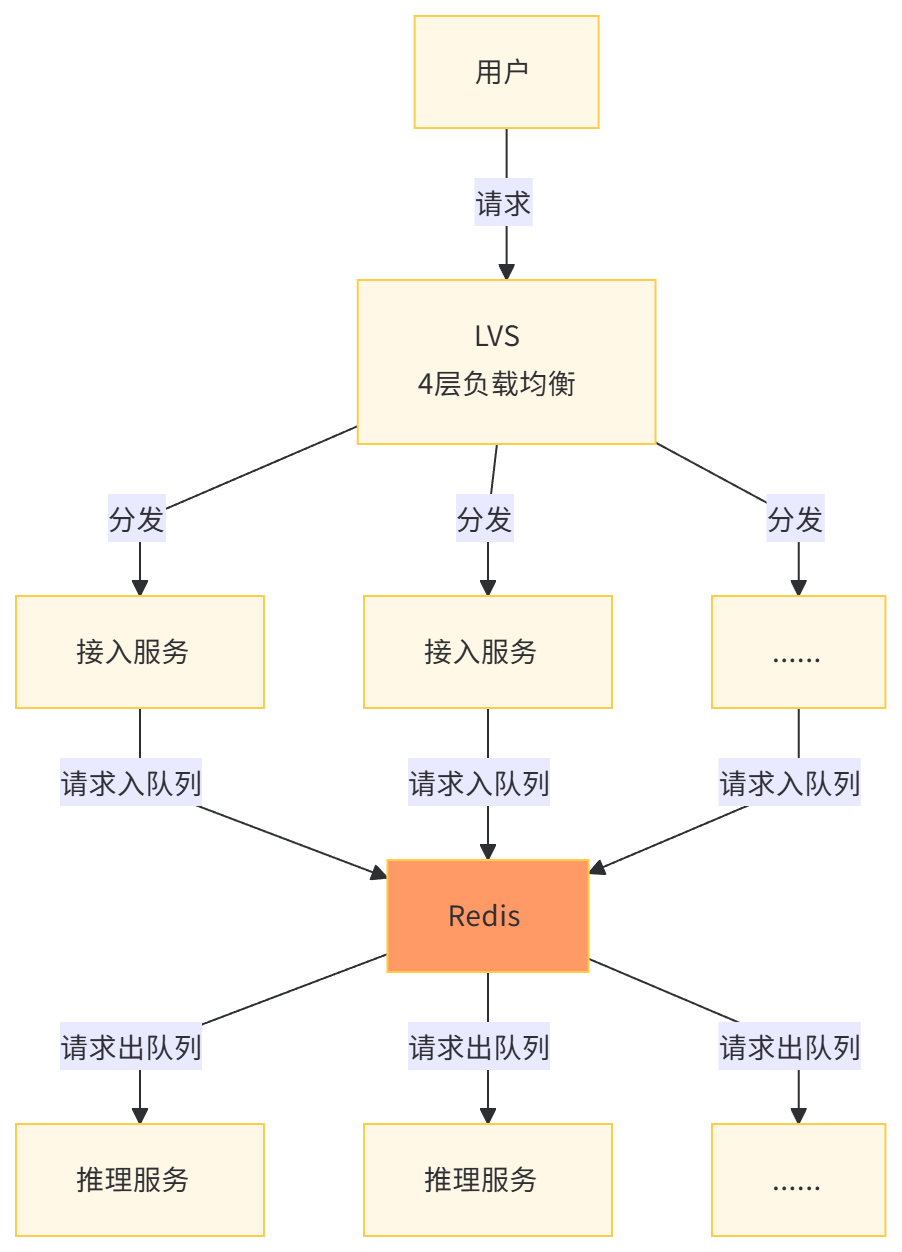
这两种方案各有优缺点,需要根据具体的业务需求和系统架构来选择最合适的负载均衡调度策略。
第三、请求异步化关键问题的解决方案
在复杂的模型推理场景中,由于推理过程耗时较长且推理时间不确定,如果接入服务同步等待结果,可能会导致过多的 HTTP 连接,以及因连接异常断开而导致的请求失败等问题,这些问题会降低整体性能并增加失败率。
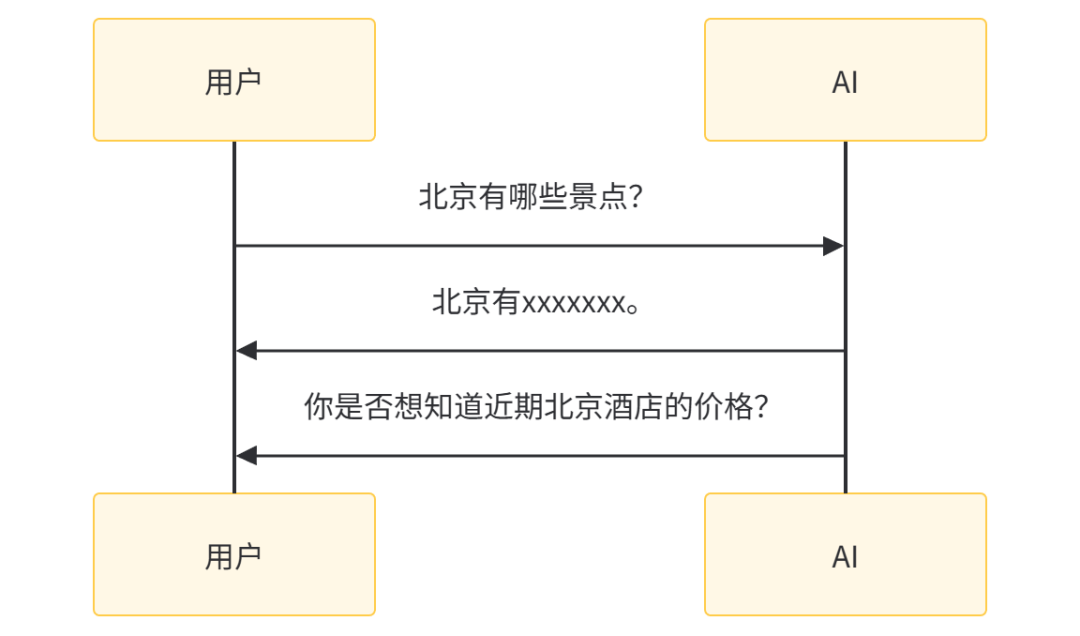
另一方面,同步请求方式通常遵循用户发起提问、服务端完成推理后返回答案的一问一答模式。如果服务端能够合理判断用户需求并主动发起对话,可以提升交互体验。例如,当用户询问北京的景点后,他们可能对北京的旅游感兴趣,因此也可能关心北京的酒店信息。异步化可以使架构更加灵活,简化后期扩展新业务逻辑的过程。
此时,可以引入 Redis 作为消息队列,将推理结果写入 Redis stream 结构中。接入服务在请求提交成功后即可返回用户请求提交成功的状态,并可以流式地返回推理结果,避免用户长时间等待。此外,这种设计解耦了接入服务和推理服务之间的强绑定关系,允许其他服务组件也能向 Redis stream 结构写入数据,实现对用户的主动交互。
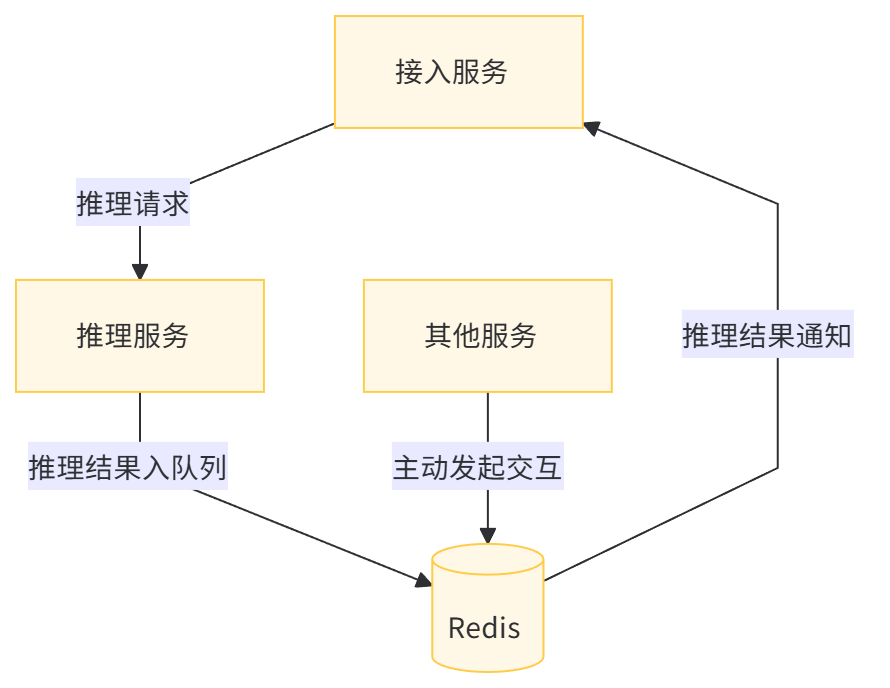
通过异步化改造,可以获得以下好处:
流式返回结果给用户,提升用户体验。
解耦组件间的直接关联,方便后续业务逻辑的扩展。
避免请求发起端盲目等待结果返回,提高效率。
第四、用户数据管理关键问题的解决方案
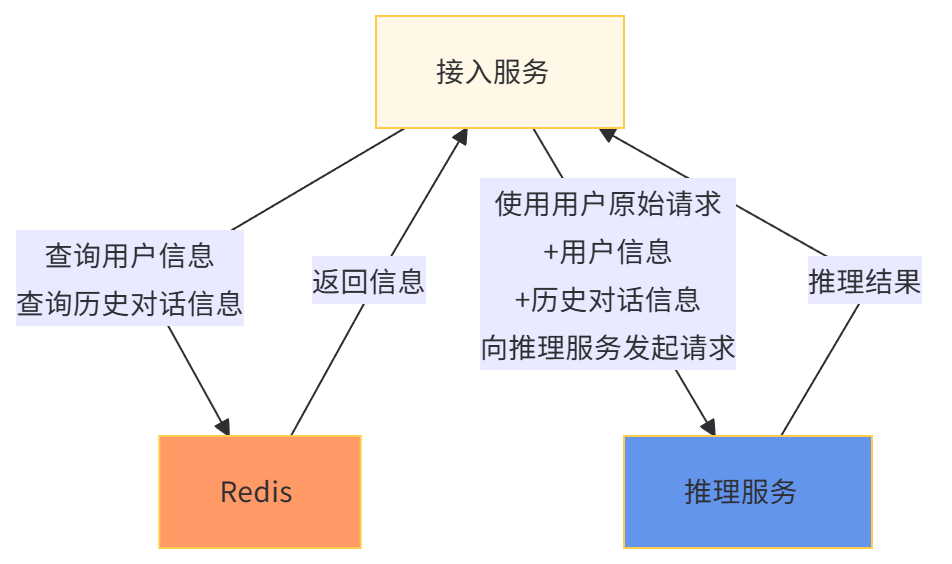
1、户信息管理与个性化服务
通过整合用户的注册信息和历史对话记录,系统能够为每位用户创建独特的标签。这些标签随后作为系统提示(Prompt)与用户请求一同提交至推理引擎,从而生成定制化的结果。这种“千人千面”的方法使得服务结果更贴合用户的个性化需求和预期。
利用 Redis 的 hash 结构,可以以树状格式高效存储用户的属性信息,该结构同时支持快速的单个查询(点查)和批量查询操作。
2、历史消息管理与对话连续性
在多轮对话场景中,系统需存储先前的对话内容,并将这些信息作为提示词(Prompt)影响后续请求,以保持对话的连贯性。此外,为了产品化需求,系统还需保存用户在一定时间内的历史对话记录,以便用户能够回顾之前的交流内容。
对话信息的存储方式具有很高的灵活性,可采用多种实现策略。例如,可以使用 zset 结构来保存历史对话,并将对话的时间戳作为评分(score),这样不仅便于对对话信息进行排序,还能轻松实现最早对话的删除以及按时间顺序查看历史对话。
如果服务已经通过 stream 结构实现了异步化改造,那么所有的推理请求和结果都将存储在 stream中,无需额外存储。Stream 结构支持设置队列大小,并能自动删除最早的对话消息。
3、会话(Session)管理
鉴于不同的对话可能涉及不同的上下文信息,可以使用 Redis 的 hash 结构来存储会话(session)信息,以实现快速切换和管理。这种方法有助于维护不同对话的独立性和连贯性,提升用户体验。
第五、RAG(检索增强生成)
采用检索增强生成(Retrieval-Augmented Generation,简称 RAG)的方法可以有效应对传统大语言模型(LLM)在实际应用中遇到的限制,这些限制包括:
知识更新滞后:LLM 的训练数据往往停留在某个时间节点,难以实现实时更新。
产生幻觉:LLM 有时会产生与事实不符的内容。
领域专业性不足:通用模型在特定领域(比如:法律、医学等)的表现可能不尽如人意。
推理能力有限:LLM 在处理复杂的推理任务时可能表现不佳。
与大模型微调(Fine-tuning)相比,RAG 方法的成本更低,且能保持更高的数据时效性。
以实现一个接入 Milvus 向量数据库的 FAQ 问答机器人为例,可以采取以下方案:
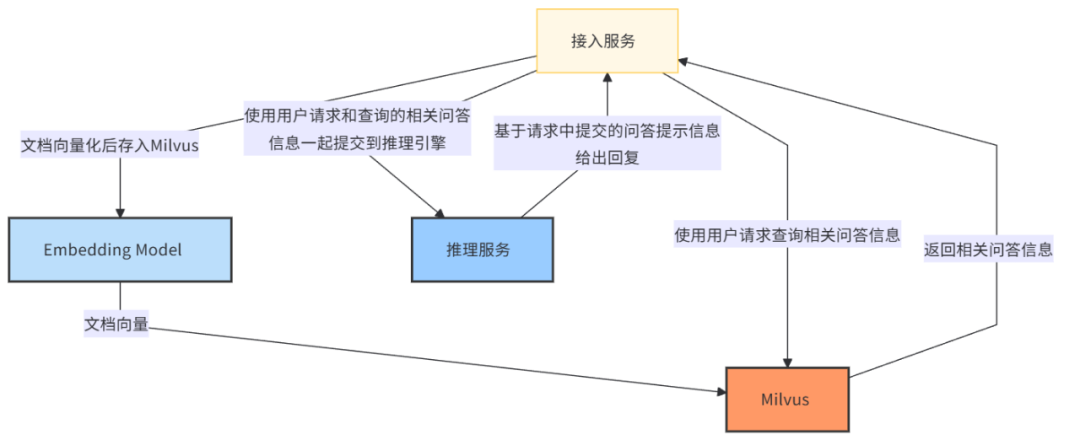
数据检索:利用 Milvus 等向量数据库,根据用户的问题检索最相关的 FAQ 条目。
信息融合:将检索到的信息与 LLM 的生成能力相结合,以提供更准确、更丰富的回答。
上下文理解:通过检索增强,LLM 能够更好地理解上下文,从而提高回答的相关性和准确性。
持续更新:由于 RAG 不依赖于模型的全面微调,因此可以更容易地更新知识库,以反映最新的信息和数据。
通过这种方式,RAG 不仅能够提高问答系统的性能,还能够保持成本效益和灵活性,使其成为处理特定领域问题的有效工具。
综合上述5个关键问题的解决方案,一个典型场景的 AI 应用推理服务流程如下所示:
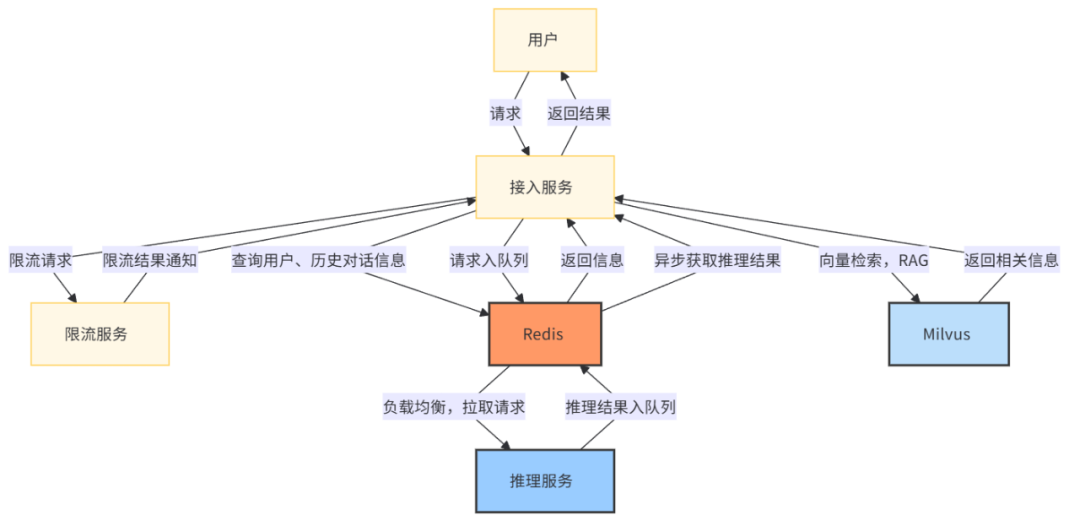
1、用户发起请求到接入服务服务器。
2、接入服务异步请求限流服务,并在请求的 UUID 上等待 Redis 通知。
3、限流服务在排队完成或超时后通过 Redis 将限流结果通知给接入服务。
4、接入服务通过 Redis 查询到用户信息、历史对话信息,作为请求的 Prompt。
5、接入服务通过 Milvus 向量检索拿到相关信息,也作为请求的 Prompt。
6、接入服务将请求写入 Redis stream 队列。
7、空闲的推理服务从 Redis stream 拉取到推理请求。
8、推理服务将推理结果写入 Redis stream 队列。
9、接入服务通过 Redis 异步获取到推理结果。
10、返回用户结果。
这个流程描述了用户请求如何通过接入服务、限流服务、Redis 以及推理服务进行处理,并最终将结果返回给用户。通过使用 Redis 作为消息队列和存储,实现了请求的异步处理和负载均衡,提高了系统的响应性和可靠性。
👉 轮到你了:你认为 AI 应用企业级落地还有哪些注意点?
PS1:
为了帮助同学们彻底掌握 MCP 开发 AI 应用以及 AI 大模型新架构体系设计的新范式,我会开场直播和同学们深度剖析,请同学们点击以下预约按钮免费预约。
PS2:
【全新推出】为了帮助大家更好的掌握 AI 大模型适合的应用落地场景、应用开发技能,推荐大家加入《3天大模型应用开发项目实战直播训练营》,通过3天直播,带你快速掌握 Agent、RAG、Fine-tuning 微调、MCP、Prompt 等技能,让大家快速掌握企业级 AI 大模型应用实战能力。此训练营刚上新,原价199元,为了回馈粉丝的支持,早鸟价19元,点击以下报名。
—3—
3天大模型应用开发项目实战直播课
3天的直播课,带你快速掌握 Agent、RAG、Fine-tuning 微调、MCP、Prompt 等 AI 大模型应用开发核心技术和企业级项目实践经验。
直播模块一:Agent 智能体开发实战篇
Agent 智能体技术原理深度解读
Agent 规划能力深度剖析与实践
Agent 行动能力深度剖析与实现
Agent 工具调用之 MCP 深度剖析
Agent 智能体 ReAct 机制深度解读
从0到1,手搓代码实现企业级智能客服
直播模块二:RAG 知识库 & Fine-tuning 微调篇
RAG 知识库核心技术解读
RAG 知识库知识切分剖析与实践
RAG 知识库两阶段检索剖析与实践
RAG 知识库项目全流程深度实践
LoRA 微调技术原理剖析
RAG 和 Fine-tuning 微调技术选型
直播模块三:综合案例实战:Agent + RAG + Fine-tuning 微调 + MCP + Prompt 案例实战篇
Agentic RAG 项目需求分析
Agentic RAG 架构设计--知识库管理
Agentic RAG 架构设计--在线联网问答
Agentic RAG 架构设计--效果评估
Agentic RAG 架构设计--模型弹性扩容
Agentic RAG 核心代码实现
基于 Agent、RAG、Fine-tuning 微调、MCP、Prompt,从需求分析、架构设计、架构技术选型、硬件资料规划、核心代码落地、服务治理等全流程实践,深度学习企业级 AI 大模型应用落地项目全流程重点难点问题解决。

3天时间,你能学会什么?
在真实项目实践中,你会获得4项硬核能力:
第一、全面掌握 DeepSeek 大模型、Agent、RAG、Fine-tuning 微调、MCP、Prompt 的原理、架构和实现方法,掌握核心技术精髓。
第二、熟练使用 AI 大模型应用开发平台:LangChain、LangGraph、LlamaIndex、AutoGen、Spring AI Alibaba、Swarm 等主流开发框架,为企业级技术实践打下坚实基础。
第三、通过企业级项目实战演练,能够独立完成基于 Agent、RAG、Fine-tuning 微调、MCP、Prompt 的 AI 大模型应用的适用场景、设计开发和维护,真正学会解决企业级实际问题的能力。
第四、为职业发展提供更多可能性,无论是晋升加薪还是转行跳槽,提升核心技术竞争力。
限时优惠:
【全新推出】,刚上线,原价199元,回馈粉丝们支持,早鸟价19元!赶快加入把~~
—4—
添加助教直播学习
购买后,一定记得添加助理,否则无法进行直播学习👇

参考来源:
https://mp.weixin.qq.com/s/SeUJxNK10fhR6YsWSJRYwg
⬇戳”阅读原文“,立即报名!
END


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









