







上个月去了客户那边实际感受了一下倾斜大数据(百G左右)的实际使用场景。客户的客户对当前的结果不满意,原因有几个:1,加载速度太慢,数据从不清晰到清晰要等待好久;2,崩溃的概率比较大。3,上层的点云数据很不好看。
经过现场分析,给出这样的临时解决方案:
1, V2版本生成的目录里pnts目录修改个名,那么就不会加载点云数据
2, 在服务端替换iis服务,使用nginx 发布静态服务,并且开启gzip压缩设置
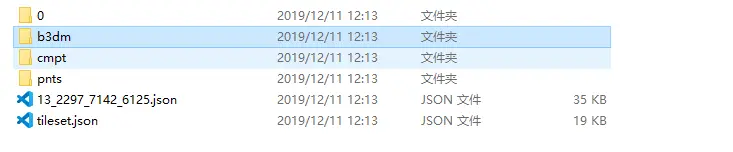
V2版本生成的目录
这两个都是短期的方案,如此操作之后,果然是快了一些,因为zip压缩后,传输的数据能节省小一半,还是非常有必要的。
当然我也是发现了一些其他问题,比如在我们V2版本重建的顶层块里出现了一些超大的块,竟然达到13M左右,这种文件加载起来必然慢。这也意味着V2版本的重建对于较大数据来说还是有缺陷的。所以我当时也承诺了会优化处理方案。
从去年我都说了,我们不太愿意在倾斜处理上耗费时间过多,原因有二:1,现在的工具smart3d 等倾斜生产工具都可以直接输出3dtiles。2,还有一些开源或者其他转换工具也同时存在。 但是从我们lab的后台统计来看,倾斜处理的使用次数占到小一半左右,也就是这个处理依然是需求最大的,至少其他免费工具并没有给出很好的解决方案,还是期待我们的处理。
19年5月倾斜处理重写了V2的版本,也就是当前大家使用的版本,这个版本我们使用点云做了顶层块的合并处理,解决一些数据加载马赛克的问题,而且使用多线程优化加速了处理过程。这一版当然也是大家吐槽比较多的:1,点云的确不好看。2,多线程带来的是处理时的内存需求急剧增加 , 这块需要解释下0表示线程数=cpu核心数,每个核心处理一个Tile,会把这个Tile全部载入内存,但是对于精度较高的倾斜数据,一个Tile内的数据量都可能上G,纹理解压后再翻10倍左右,导致内存使用很夸张。当时为何这么做?是因为当时设计的时候,设想尽力去减小渲染批次,对于原来倾斜中的小数据块(几十K的数据,包含的小于1024*1024的纹理)会做合并处理,所以每个Tile都是完全读入内存再做处理。 现在看来,这一版还不是最完美方案,客户依然是不满意的。
所以上个月回来之后,再次重写倾斜处理V3(没办法就是喜欢推到重来),这次的设计目标和需求是: 1,处理过程没必要合并小数据块,加速数据载入数据, osgb 对应 b3dm的一对一转换(又恢复到V1版本的方案,迄今还不断有人问我要V1的处理程序,看来V2的却有点走弯路了)。2,对于顶层块的合并处理,并且输出结果一定是三角网(b3dm)。
针对第一条需求:
我们再也不必纠结整个Tile的载入到内存,转一个osgb,即可清空内存占用,这块我花费了1天多就重新实现了整个过程,测试完效率惊人,这种急速处理方式下,70G数据(大约31w个osgb)仅需要2.5小时转换完毕,这个速度和拷贝一遍这个目录的时间差不多,也就是实际的耗时都是在硬盘io上,因为的确没做什么复杂运算,只是转个格式而已。内存占用非常小,在1G以下。
针对第二条需求:
这个没有前面的 海量模型处理(关于海量模型处理的文章)的技术积累,还真做不了这个事情. 具体的三角网合并精简算法不再细说,我们只看下最终的重建效果:
测试数据约10平方公里,940+个 Tile, 70G左右
最顶层块的包围盒
下拉几级之后的包围盒

处理完成的目录,tile开头是原始osgb一对一得到目录,top是我们重建的顶层块目录
这个重建效果还是达到了初步的设想,这个数据重建顶层块的时间大约耗费了2.5小时,再加上转原始osgb,总计这块处理完成大约耗时5个小时左右。
数据处理到这里并没有结束,又发现了一个问题: 这个数据处理完毕之后,浏览一会之后,明显感觉cesium会卡顿, 很奇怪是内存中的tile并不多,经过仔细分析,虽然载入到内存中tile(调试面板里的Content Ready)数据量不多,但是总的Tile对象(调试面板里的Total)却达到了31w个。
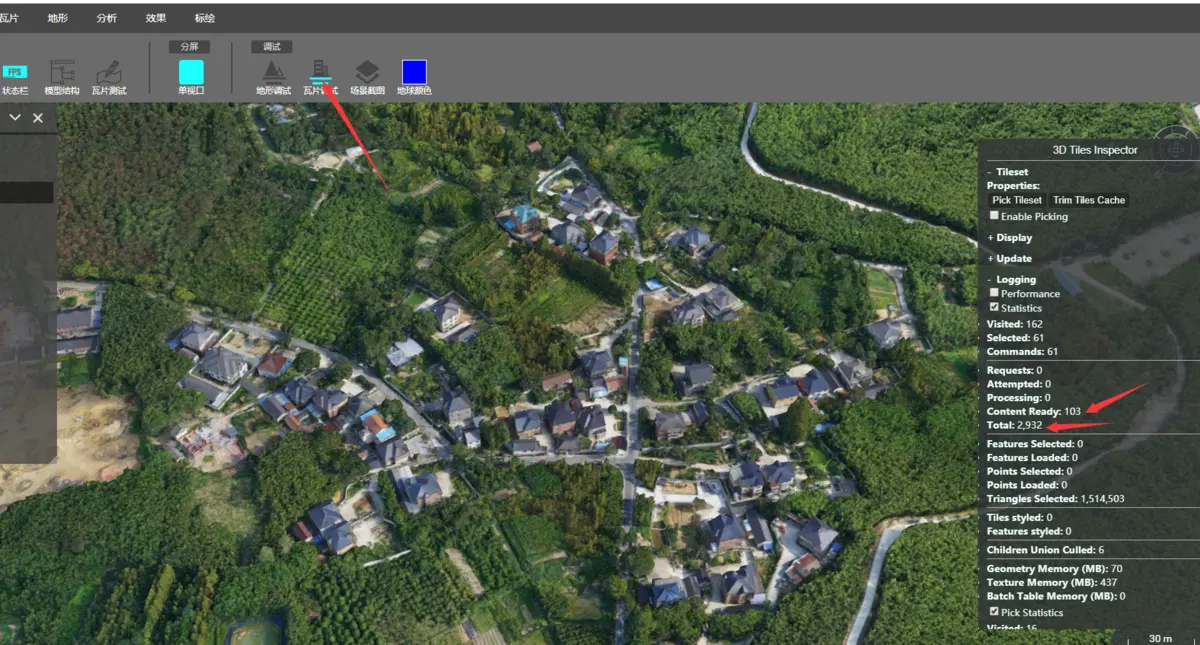
瓦片分析工具
这也是我以前忽略的问题,影响cesium的性能除了本身每个Tile的数据量之外,还有这个索引Tile的个数,因为cesium毕竟是js实现的引擎,每个Tie即便没有请求资源,但是也会创建js的Tie对象,Cesium的数据载入淘汰都需要对整颗索引树进行遍历,当索引过大,还是会严重影响性能。如果你手头有contextcapture导出的3dtiles,你会发现他的每个b3dm都对应了一个json,原本还挺鄙视这种做法,因为增加了额外的网络请求,现在看来,人家是故意而为之,所以经过修改,我们现在新版输出的json(海量模式下)会对目录里一个b3dm(非叶子节点)生成一个json。修改之后果然不卡了。(这个问题做了3dtiles转换一年多才发现,实在汗颜,当然主要问题还是缺少大的测试数据,一般的数据没有这么多块,自然也体会不到这个差异)
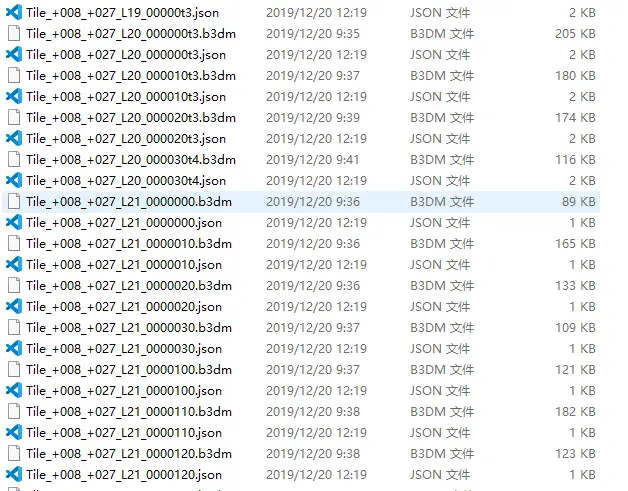
多json的生成
还有一个问题没有解决,就是倾斜的崩溃问题:
我们来估算下资源消耗,我们目前常见分辨率都是1920x1080屏幕,如果我们用256x256的影像切片铺满,最少大概需要32块,考虑我们视角位置不可能刚好是瓦片分隔处,所以常见的我们还要多显示一圈数据(7+7+4+4=22)。也就是平面四叉分隔下,一屏幕最少需要54块填满。我们换成倾斜数据,假设倾斜的显示精度和256x256的平面影像一致,但是倾斜是立体的,显示的时候必然依据和相机的距离精度递减,简单来估算,距离相机最近的是54个块,稍远一点是27个块,再远一点是14个 以此递减(实际计算是按照精度,而不是依据这种估算的)估算下来也就是最终最多显示100多个块(selected)是合理的。因为倾斜是金字塔数据,显示这屏数据的时候,我们还要创建它们的父块资源,那么实际访问的是200多块(visited)。
如果倾斜都是平面的,那么每块的纹理都是256x256,如果都是立方体,那么为了保持这个精度都是256x256x6,但是倾斜我们拍摄的主体一般都是室外建筑或者地形甚至工厂管道,并不是那么简单的几何体,它都有沟沟壑壑,如果每个三角形都是保持这种精度,那么纹理必要要大于 256x256x6,这种你分析下倾斜输出的osgb即可知道,高级别的数据里面大部分存储都是2048x2028的纹理,这种纹理一张就需要占用12M显卡资源,200多块就要占用接近2G的纹理资源。下来我们再考虑一层底图影像的资源(几百M),还有其他几何体资源(几百M)。所以数据精度稍高,显卡占用就超过3G,而一般低端显卡显存(或者移动端)就这么大点,不崩才怪。 而且很多人因为嫌倾斜不清晰,设置maximumScreenSpaceError为8(默认16)甚至更小,这会导致加载和显示数据再次翻倍,最终结果就是显存消耗更大,更容易崩溃.

某视角下的资源消耗
频繁崩溃的原因如果定位了,那么解决方式也就明确了,减少数据资源消耗,尤其是纹理的资源消耗,这里有一个严重误区, 一张1024x1024的jpg硬盘大小 只有100K, 我们把它压缩到70K是不是就降低了显存消耗? 显卡并不能直接使用jpg格式去创建资源,也就是需要在cpu和内存里把jpg解压缩,这张图片解压缩后的大小是固定的也就是3MB,创建显存也就是占用3MB,所以显存只跟你图片分辨率有关系,而和你的图片格式甚至压缩参数没关系. 但是现代显卡为了解决这个问题,提出了若干种显卡能使用的压缩格式,最早也是最常见的就是 dxt,具体可以百度,但是这种方式的压缩率是固定的(8:1) 左右,也就是1024的图片压缩成dxt实际占用到 400K,这个反倒比jpg大不少,但是他真的是节省显卡资源. 我们lab的支持的几种纹理优化方式列表如下:

lab上的纹理格式
1, 默认 保留原始纹理格式(osgb里一般默认是jpg)
2, 减小总量 纹理格式输出为webp
最大的减小纹理传输数据量,比jpg压缩还会少20%,但是不减小显存消耗
3, 减小显存 纹理格式输出 ktx (实际是dxt压缩)
减小显存消耗,但是纹理存储数据量会增加到4倍左右
4, 综合优化 纹理格式输出crn (基于dxt之上的二次压缩)
减小显存消耗,纹理存储接近默认的方式
扯了这么多,估计没人愿意看,谁关心你错了多少次,熬了多少夜,只要结果,ok,满足你们,我们说下倾斜处理的结论:
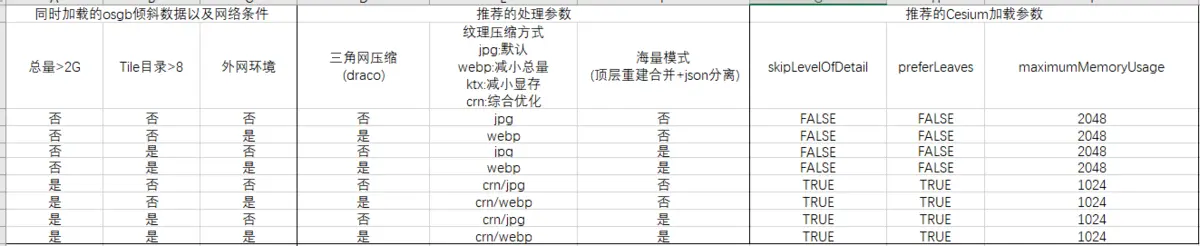
倾斜处理参数表
这张表对于实在看不明白的人 或者 懒得看的人一个最佳方式,根据你的数据以及网络方式选择 对应一行的处理参数。我们再逐个解释下:
1, 三角网压缩(draco)
draco压缩是一种非常高效的压缩方式,同一数据源,默认处理为70G,开启 draco压缩为37G 。但是注意压缩率并不是 70:37,因为draco 只针对顶点数据,这两个值还包含纹理数据(大约为30G),所以实际的压缩率为(70-30):(37-30)。 可见这个压缩率还是挺高的。
结论是:如果数据最终是公网发布的,那么还是要做下draco压缩,大大节省带宽(50%左右)。但是如果是本地局域网,可以不做压缩,因为压缩为有损压缩,数据质量会降,降低的不明显。
如果既要保证原始原始质量,又要公网发布,那么一定开起公网服务器的 gzip压缩,能节省(20%左右的带宽)
2, 纹理压缩方式
上述的70G数据,开起draco+webp之后为31G,也就是做了webp压缩,比原始不压缩的纹理小了6G, 原始为30G, 压缩率为 30:(30-6) 差不多相交默认(jpg)节省 16% 左右的纹理,这也是webp的优势。
如果数据总量较小的前提下,又是公网传输,我们只考虑传输效率,那么做下webp压缩,进一步提升数据加载速度。
如果数据总量较大,那么无论是否是公网传输,我们第一位考虑的就是系统稳定性,那么尽可能的节省资源,最好做crn压缩。
但是这块又有个比较尴尬的问题,crn的压缩实在是慢,1024*1024的crn的压缩速度在秒级,数据较大的情况下,这个处理速度的是个灾难,关于这个我们未来会给出解决方案,敬请期待。
3,海量模式(CesiumLab V2.2.0版本改为重建顶层)
海量模式其实做了两个事情:1,合并顶层块 + json分离。当然json分离我前面也提到了它的影响。下面我们主要说合并顶层块。
合并顶层块这个主要针对的Tile目录过多的情况下,一般大于8个还是有必要合并一下的,当然现在也见过一些倾斜生产的软件,输出的本身Tile个数不是太多,那么这种实际没必要合并。
如果顶层块太多,但是不合并,那么带来的问题就是顶层类似马赛克一样刷新显示,而且资源得到不释放,比如上述的示例数据有970块,假设这些块每个的纹理是1M(大约512*512)纹理,那么这个就是很可观的资源浪费。而且一旦显示顶层层级,cesium的command过多,也会很卡。
目前我们合并速度还是比较慢,大约合并重建一个块需要30s,比如上述970个Tile块,那么待合并的顶层块有1/3左右,也就是330多个块,那么需要的时间大约为 (330 * 30 s)=170分钟左右,这个速度未来我们也会优化,给出加速方案。
最后再说几个影响加载效率的关键参数:
1, maximumScreenSpaceError
这个参数默认是16,只要是lab输出的数据,我们已经考虑这个默认值了,所以一般情况下,不需要修改。
2,skipLevelOfDetail
这个参数默认值是 true,是Cesium在1.5x 引入的一个优化参数,这个参数在金字塔数据加载中,可以跳过一些级别,这样整体的效率会高一些,数据占用也会小一些。
但是带来的异常是:1) 加载过程中闪烁,看起来像是透过去了,数据载入完成后正常。2,有些异常的面片,这个还是因为两级LOD之间数据差异较大,导致的。
当这个参数设置false,两级之间的变化更平滑,不会跳跃穿透,但是清晰的数据需要更长,而且还有个致命问题,一旦某一个tile数据无法请求到或者失败,导致一直不清晰。
所以我们建议:对于网络条件好,并且数据总量较小的情况下,可以设置false,提升数据显示质量。
3, preferLeaves
这个参数默认是false,同等条件下,叶子节点会优先加载。但是Cesium的tile加载优先级有很多考虑条件,这个只是其中之一,如果skipLevelOfDetail=false,这个参数几乎无意义。所以要配合skipLevelOfDetail=true来使用,此时设置preferLeaves=true。这样我们就能最快的看见符合当前视觉精度的块,对于提升大数据以及网络环境不好的前提下有一点点改善意义。
4, maximumMemoryUsage
这个参数默认是512,也即是当几何体和纹理资源大于512MB的时候,Cesium就会淘汰掉当前帧中没有visited的所有块,这个值其实很小,也是cesium为了避免资源占用过高的一个保障,不过上述我们也估算过最差情况下,没有做纹理crn压缩的情况下,这个值很容易被超过,导致很多人误以为cesium的淘汰没有效果。这个值如果设置的过小,导致cesium几乎每帧都在尝试淘汰数据,增加了遍历的时间,也同时增加了崩溃的风险。这个值如果设置的过大,cesium的淘汰机制失效,那么容易导致显存超过显卡内存,也会导致崩溃。这个值应该处于最差视角下资源占用 和 显存最大量之间。
结论:这个参数要根据当前显卡显存来配置,如果我们场景只显示这一个倾斜数据,这个可以设置到显存的50%左右,比如我的显存是6G,这个可以设置到3000左右。那么既保证不超过显存限制,又可以最大利用显存缓存,配合crn压缩之后,这个几乎可以保证你第二次查看倾斜同一位置的时候,看不到加载过程,非常棒。
综上:倾斜大数据处理我基本说清楚了,还是要根据您的数据来。
CesiumLab倾斜处理V3
这里依然保留V2版本程序,主要是避免日后支持麻烦,还有很多人总怀念过去,所以保留下来.
到这里CesiumLab对于倾斜的处理结果我觉得也到了最终的方案,不可能再出现Cesium加载的质的飞跃, 基本已经能保证你无论多大的倾斜,无论什么视角都是在30fps以上帧率运行了,而且不崩溃.
上周末又去了下客户现场,部署了我们最新处理的数据,客户还是挺满意的,系统再也没有因为资源耗尽而崩溃.
当然各位测试过程可能还是有各种各样的问题,那么请给我发数据,没有数据我解决不了问题。















 4559
4559











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









