







 本文详细介绍了HDFS中文件的写入和读取策略。在写入时,根据client是否为DataNode节点,确定副本存储规则。读取时,依据副本距离读取端的远近进行排序选择。数据块被分成多个部分,通过DataStreamer和pipeline进行传输,确保数据的高效和可靠性。
本文详细介绍了HDFS中文件的写入和读取策略。在写入时,根据client是否为DataNode节点,确定副本存储规则。读取时,依据副本距离读取端的远近进行排序选择。数据块被分成多个部分,通过DataStreamer和pipeline进行传输,确保数据的高效和可靠性。
HDFS文件写入与读写
副本(3个)选择策略说明:
1. 若client为DataNode节点,那存储block时,规则为:副本1,同client的节点上;副本2,不同机架节点上;副本3,同第二个副本机架的另一个节点上;其他副本随机挑选。
2. 若client不为DataNode节点,那存储block时,规则为:副本1,随机选择一个节点上;副本2,不同副本1,机架上;副本3,同副本2相同的另一个节点上;其他副本随机挑选。
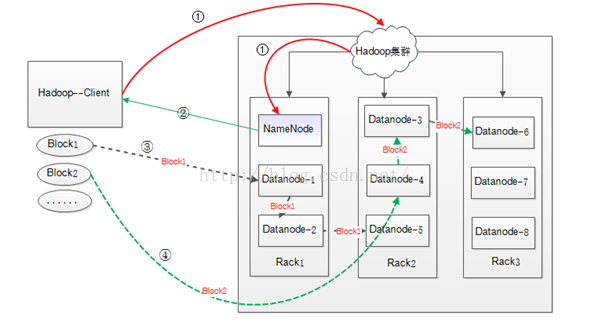
将一个100M的文件上传到HDFS中,Hadoop集群如上图所示的三个Rack,8个DataNode节点,集群配置采用默认配置。HDFS数据块的默认大小为64M,则该文件被分为两个BLOCK进行写入:Block1(64M)和Block2(36M)。
① Hadoop的Client向集群中的NameNode请求文件的写入(图中红色实线)
② NameNode节点接收到写入请求,记录block信息,并返回可用的DataNode节点。比如: Block1 : DataNode1——DataNode2——DataNode5
Block2 : DataNode4——DataNode3——DataNode6
需要说明的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1150
1150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









