




 本文详细解读了Hugging Face Transformers库中text generation模块的GenerationMixin类,重点介绍了核心参数如max_length、min_length、do_sample、top_k、top_p等,以及Greedy Search、Beam Search、Sampling(包括Temperature、Top-k和Top-p)的原理和应用。通过实例演示,探讨了各种解码策略在文本生成中的效果和局限性。
本文详细解读了Hugging Face Transformers库中text generation模块的GenerationMixin类,重点介绍了核心参数如max_length、min_length、do_sample、top_k、top_p等,以及Greedy Search、Beam Search、Sampling(包括Temperature、Top-k和Top-p)的原理和应用。通过实例演示,探讨了各种解码策略在文本生成中的效果和局限性。
一、前言
最近在做文本生成,用到huggingface transformers库的文本生成 generate() 函数,是 GenerationMixin 类的实现(class transformers.generation_utils.GenerationMixin),是自回归文本生成预训练模型相关参数的集大成者。因此本文解读一下这些参数的含义以及常用的 Greedy Search、Beam Search、Sampling(Temperature、Top-k、Top-p)等各个算法的原理。
这个类对外提供的方法是 generate(),通过调参能完成以下事情:
- greedy decoding:当
num_beams=1而且do_sample=False时,调用greedy_search()方法,每个step生成条件概率最高的词,因此生成单条文本。 - multinomial sampling:当
num_beams=1且do_sample=True时,调用sample()方法,对词表做一个采样,而不是选条件概率最高的词,增加多样性。 - beam-search decoding:当
num_beams>1且do_sample=False时,调用beam_search()方法,做一个 num_beams 的柱搜索,每次都是贪婪选择top N个柱。 - beam-search multinomial sampling:当
num_beams>1且do_sample=True时,调用beam_sample()方法,相当于每次不再是贪婪选择top N个柱,而是加了一些采样。 - diverse beam-search decoding:当
num_beams>1且num_beam_groups>1时,调用group_beam_search()方法。 - constrained beam-search decoding:当
constraints!=None或者force_words_ids!=None,实现可控文本生成。
二、各输入参数含义
接下来分别看看各个输入参数(源代码):
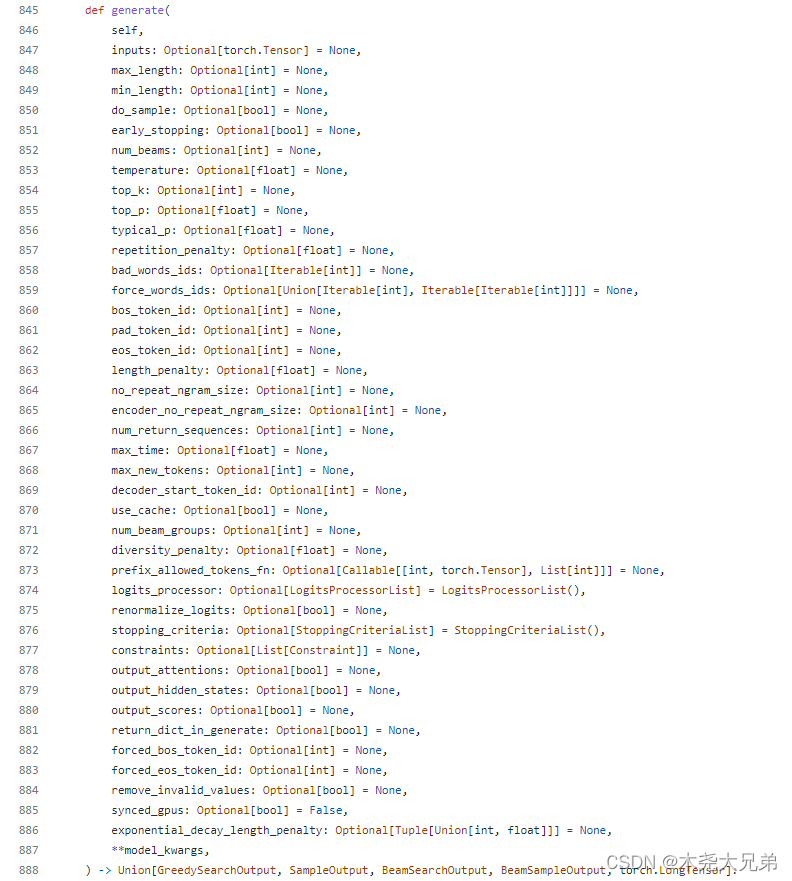
我觉得对文本生成质量最有用的几个参数有:max_length、min_length、do_sample、top_k、top_p、repetition_penalty。接下来选择性地记录各个参数的含义。
inputs (torch.Tensor of varying shape depending on the modality, optional) — The sequence used as a prompt for the generation or as model inputs to the encoder. If None the method initializes it with bos_token_id and a batch size of 1. For decoder-only models inputs should of in the format of input_ids. For encoder-decoder models inputs can represent any of input_ids, input_values, input_features, or pixel_values.
inputs:输入prompt。如果为空,则用batch size为1的 bos_token_id 初始化。对于只有decoder的模型(GPT系列),输入需要是 input_ids;对于 encoder-decoder模型(BART、T5等),输入更多样化。
max_length (int, optional, defaults to model.config.max_length) — The maximum length of the sequence to be generated.
max_length:生成序列的最大长度。
min_length (int, optional, defaults to 10) — The minimum length of the sequence to be generated.
min_length:生成序列的最短长度,默认是10。
do_sample (bool, optional, defaults to False) — Whether or not to use sampling ; use greedy decoding otherwise.
do_sample:是否开启采样,默认是 False,即贪婪找最大条件概率的词。
early_stopping (bool, optional, defaults to False) — Whether to stop the beam search when at least num_beams sentences are finished per batch or not.
early_stopping:是否在至少生成 num_beams 个句子后停止 beam search,默认是False。
num_beams (int, optional, defaults to 1) — Number of beams for beam search. 1 means no beam search.
num_beams:默认是1,也就是不进行 beam search。
temperature (float, optional, defaults to 1.0) — The value used to module the next token probabilities.
默认是1.0,温度越低(小于1),softmax输出的贫富差距越大;温度越高,softmax差距越小。
top_k (int, optional, defaults to 50) — The number of highest probability vocabulary tokens to keep for top-k-filtering.
top_k:top-k-filtering 算法保留多少个 最高概率的词 作为候选,默认50。详见下文。
top_p (float, optional, defaults to 1.0) — If set to float < 1, only the most probable tokens with probabilities that add up to top_p or higher are kept for generation.
top_p:已知生成各个词的总概率是1(即默认是1.0)如果top_p小于1,则从高到低累加直到top_p,取这前N个词作为候选。
typical_p
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2885
2885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









