








一、vLLM 简介
vLLM 用于大模型并行推理加速,核心是 PagedAttention 算法,官网为:https://vllm.ai/。

vLLM 主要特性:
- 先进的服务吞吐量
- 通过 PagedAttention 对注意力 key 和 value 进行内存管理
- 对传入请求的批处理
- 针对 CUDA 内核的优化
vLLM 灵活易用:
- 与 HuggingFace 模型无缝集成
- 支持并行采样、beam search 等解码算法的高吞吐量服务
- 支持分布式推理的张量并行
- 支持流式输出
- 兼容 OpenAI 的接口服务
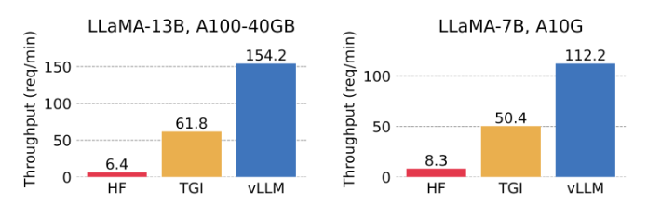
图 - 服务吞吐量对比:单路输出
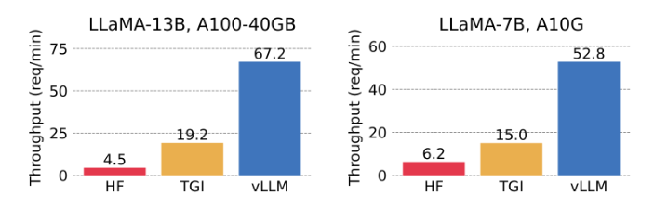
图 - 服务吞吐量对比:3 路并行输出
二、vLLM 原理
PagedAttention 原理(一)
用于自回归生成的 KV cache 占大量显存,受OS中的虚拟内存和分页的思想启发,提出了该 attention 优化算法,可在不连续的显存空间存储连续的 key 和 value。用于将每个序列的 KV cache 分块(blocks),每块包含固定数量的 token 的 key 和 value 张量。

动图☝️:以 for 的 attention计算为例。KV cache 被划分为多个块,块在内存空间中不必连续
PagedAttention 原理(二)
因为 blocks 在显存中不必连续,所以可以像 OS 的虚拟内存分页一样,以更灵活的方式管理键和值:
- 将 block 视为 page
- 将 token 视为 bytes
- 将序列视为进程
序列的连续逻辑块通过 block table 映射到非连续物理块。
物理块可在生成新 token 时按需分配。因此只有最后一个block会发生显存浪费,小于4%。

动图☝️:通过 block table 将逻辑块映射到物理块
PagedAttention 原理(三)
并行采样时,同一个 prompt 生成多个输出序列,这些序列生成时可以共享 prompt 的 attention 计算和显存。
与 OS 中进程共享物理 page 的方式类似,不同序列可以通过将其逻辑块映射到同一物理块来共享块。为了确保共享安全,Paged Attention 跟踪物理块的引用计数,并实现 “写时复制”(Copy-on-Write)机制,即需要修改时才复制块副本。内存共享使得显存占用减少 55%,吞吐量提升 2.2x。
写时复制(Copy-on-write,简称COW)是一种计算机程序设计领域的优化策略。其核心思想是,如果有多个调用者(callers)同时请求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。

动图☝️:并行采样生成时的引用计数和 Copy-on-Write
三、内部模型实测
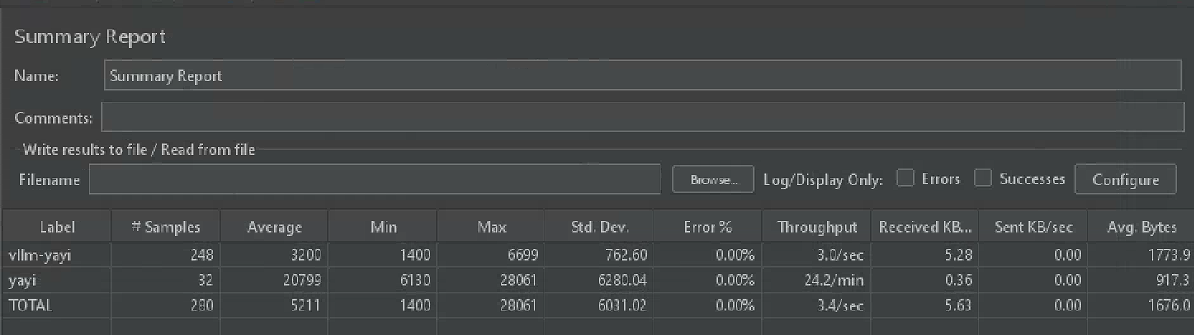
硬件:单卡A100(80G)
模型:内部 7B 模型
测试工具:Apache JMeter
实验结论:vLLM 加速 7.44 倍
指标解释:
# Samples :总请求数(样本个数)
Throughput :吞吐量(Request/Sec),即每秒处理的请求数
Average :平均响应时间(ms)
Received KB/sec :每秒从服务器端接收到的数据量(字节)
Sent KB/sec :每秒向服务器发送数据量(字节)















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









