









一、感知器
神经元又叫感知器:它可以拟合任何的线性函数,任何线性分类或线性回归问题都可以用感知器来解决。异或不行,因为不能用一条直线将异或的结果分类
m个输入,n个输出,隐含层为

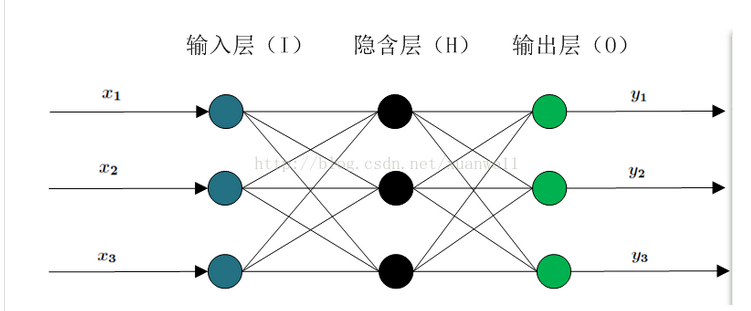
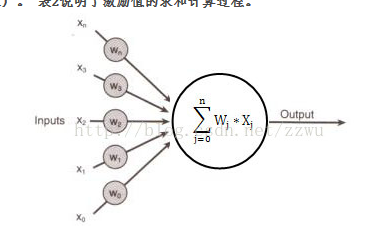
其中单个神经元:
xi 为输入,
wi为权重,在-1到1之间,b为偏置项
为激励值,在-1到1之间
激活函数:阶跃函数:
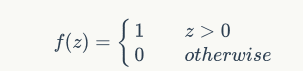
输出=f(wi*xi+```+```+b)
设阈值为1,则激励值大于等于阈值,输出1,否则0;
BP算法要求激活函数可导
输出又称为标记
神经元的训练:感知器规则
将权重项和偏置项初始化为0,然后,利用下面的感知器规则迭代的修改wi和b,直到训练完成
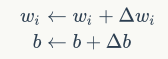
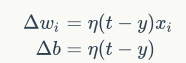
是与输入对应的权重项,b是偏置项。事实上,可以把b看作是值永远为1的输入xb所对应的权重。t是训练样本的实际值,一般称之为label。而y是感知器的输出值,它是根据计算得出。η是一个称为学习速率的常数,其作用是控制每一步调整权的幅度。
二、线性单元,梯度下降算法
感知器有一个问题,当面对的数据集不是线性可分的时候,『感知器规则』可能无法收敛,这意味着我们永远也无法完成一个感知器的训练。为了解决这个问题,我们使用一个可导的线性函数来替代感知器的阶跃函数,这种感知器就叫做线性单元。线性单元在面对线性不可分的数据集时,会收敛到一个最佳的近似上。
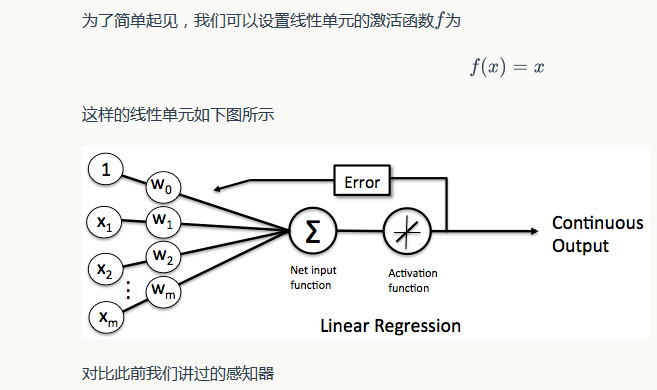
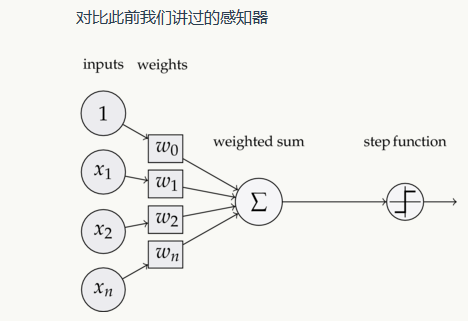
这样替换了激活函数f之后,线性单元将返回一个实数值而不是0,1分类。因此线性单元用来解决回归问题而不是分类问题。
三、监督学习和无监督学习
监督学习是指样本中有输入和对应的输出;无监督学习是指样本中只有输入。
四、监督学习
目标函数:对误差的优化函数。
(一)、梯度下降优化算法
梯度是一个向量,它指向函数值上升最快的方向


(二)、随机梯度下降算法(Stochastic Gradient Descent, SGD)
批梯度下降(Batch Gradient Descent,BGD)
全连接(full connected, FC)神经网络
一个神经网络的连接方式、网络的层数、每层的节点数这些参数,则不是学习出来的,而是人为事先设置的。对于这些人为设置的参数,我们称之为超参数(Hyper-Parameters)。
(三)、反向传播算法(Back Propagation)
(四)、卷积网络
局部连接:每个神经元不再和上一层的所有神经元相连,而只和一小部分神经元相连
权值共享:一组连接可以共享同一个权重,而不是每个连接有一个不同的权重,这样又减少了很多参数
下采样:可以使用Pooling来减少每层的样本数,进一步减少参数数量,同时还可以提升模型的鲁棒性。
在训练神经网络前一般需要对数据进行预处理,一种重要的预处理手段是归一化处理















 4510
4510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









